This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern dataarchitecture. Datalakes store all of an organization’s data, regardless of its format or structure.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern dataarchitecture to accelerate the delivery of new solutions.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. And move with confidence and trust with built-in governance to address enterprise security needs.
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Previously, there were three types of data structures in telco: .
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Organizations have chosen to build datalakes on top of Amazon Simple Storage Service (Amazon S3) for many years. A datalake is the most popular choice for organizations to store all their organizational data generated by different teams, across business domains, from all different formats, and even over history.
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. Data architect vs. data engineer The data architect and data engineer roles are closely related.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
Data scientists derive insights from data while business analysts work closely with and tend to the data needs of business units. Business analysts sometimes perform data science, but usually, they integrate and visualizedata and create reports and dashboards from data supplied by other groups.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs. Amazon AppFlow can be used to transfer data from different SaaS applications to a datalake.
Noel had already established a relationship with consulting firm Resultant through a smaller datavisualization project. Resultant recommended a new, on-prem data infrastructure, complete with datalakes to provide stake holders with a better way to manage data reliability, accuracy, and timeliness.
It provides insights and metrics related to the performance and effectiveness of data quality processes. In this post, we highlight the seamless integration of Amazon Athena and Amazon QuickSight , which enables the visualization of operational metrics for AWS Glue Data Quality rule evaluation in an efficient and effective manner.
In a modern dataarchitecture, unified analytics enable you to access the data you need, whether it’s stored in a datalake or a data warehouse. Select the Visual with a blank canvas , because we’re authoring a job from scratch, then choose Create.
We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science.
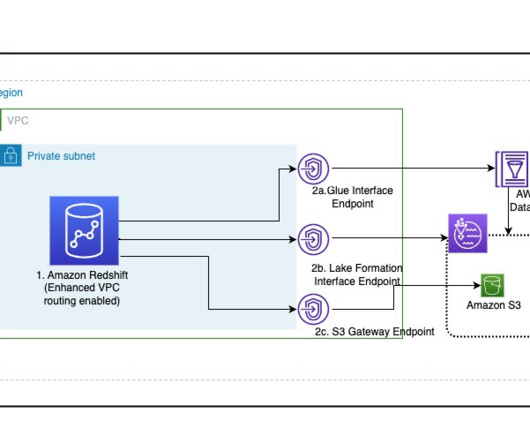
Many customers are extending their data warehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3). Choose Create endpoint.
Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Compare ongoing data that is replicated from the source on-premises database to the target S3 datalake.
So Thermo Fisher Scientific CIO Ryan Snyder and his colleagues have built a data layer cake based on a cascading series of discussions that allow IT and business partners to act as one team. Martha Heller: What are the business drivers behind the dataarchitecture ecosystem you’re building at Thermo Fisher Scientific?
To bring their customers the best deals and user experience, smava follows the modern dataarchitecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption. This is the Data Mart stage.
Amazon Redshift enables data warehousing by seamlessly integrating with other data stores and services in the modern data organization through features such as Zero-ETL , data sharing , streaming ingestion , datalake integration , and Redshift ML.
ATPCO is the industry leader in providing pricing and merchandising content for airlines, global distribution systems (GDSs), online travel agencies (OTAs), and other sales channels for consumers to visually understand differences between various offers. This slowed down their pace of innovation because it added time to the analytics journey.
Data fabric and data mesh are emerging data management concepts that are meant to address the organizational change and complexities of understanding, governing and working with enterprise data in a hybrid multicloud ecosystem. The good news is that both dataarchitecture concepts are complimentary.
The dataarchitecture diagram below shows an example of how you could use AWS services to calculate and visualize an organization’s estimated carbon footprint. Customers have the flexibility to choose the services in each stage of the data pipeline based on their use case. usage_therms", "gasutilization"."usage_scf"
The initial stage involved establishing the dataarchitecture, which provided the ability to handle the data more effectively and systematically. “We This allowed us to derive insights more easily.”
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificial intelligence (AI) applications.
In fact, AMA collects a huge amount of structured and unstructured data from bins, collection vehicles, facilities, and user reports, and until now, this data has remained disconnected, managed by disparate systems and interfaces, through Excel spreadsheets.
In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse. 1: Multi-function analytics . 2: Open formats. Flexible and open file formats.
Kinesis Data Streams has native integrations with other AWS services such as AWS Glue and Amazon EventBridge to build real-time streaming applications on AWS. Refer to Amazon Kinesis Data Streams integrations for additional details. The raw data can be streamed to Amazon S3 for archiving.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
The following is a high-level architecture of the solution we can build to process the unstructured data, assuming the input data is being ingested to the raw input object store. The steps of the workflow are as follows: Integrated AI services extract data from the unstructured data.
In working with clients, these are some of the most common “pain points” I routinely address: Difficulty in extracting data out of legacy systems. Limited real-time analytics and visuals. Inability to get data quickly. Data accuracy concerns. More time spent accessing data vs. making data-driven decisions.
In this post, we dive deep into the tool, walking through all steps from log ingestion, transformation, visualization, and architecture design to calculate TCO. With QuickSight, you can visualize YARN log data and conduct analysis against the datasets generated by pre-built dashboard templates and a widget.
Both engines provide native ingestion support from Kinesis Data Streams and Amazon MSK via a separate streaming pipeline to a datalake or data warehouse for analysis. OpenSearch Service offers visualization capabilities powered by OpenSearch Dashboards and Kibana (1.5
Strategize based on how your teams explore data, run analyses, wrangle data for downstream requirements, and visualizedata at different levels. The AWS modern dataarchitecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud.
Here are some of the key use cases: Predictive maintenance: With time series data (sensor data) coming from the equipment, historical maintenance logs, and other contextual data, you can predict how the equipment will behave and when the equipment or a component will fail. Eliminate data silos.
Building datalakes from continuously changing transactional data of databases and keeping datalakes up to date is a complex task and can be an operational challenge. You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes.
The most common big data use case is data warehouse optimization. Big dataarchitecture is used to augment different applications, operating alongside or in a discrete fashion with a data warehouse. A big data implementation may even replace a data warehouse entirely with a datalake.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. provides a visual ETL tool for authoring jobs to read from and write to Amazon Redshift, using the Redshift Spark connector for connectivity. AWS Glue 4.0 Sudipta Bagchi is a Sr.
DaaS is a core component of modern dataarchitecture. It provides a governed standard for accessing existing data objects and pipelines for sharing new data objects within an organization. Because it hides the underlying complexities of connecting to and preparing data sources, DaaS helps expand usage of available data.
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a datalake, transformed, and made available for analytics, machine learning (ML), and visualization. In his spare time, he loves to play cricket and badminton.
Busy Executives and Managers have their information needs best served via visual exhibits that are focussed on their areas of priority and highlight things that are of specific concern to them. Without paying attention to this, your shiny warehouse or datalake will be a technological curiosity, not an indispensable business tool.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content