This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a data lake on AWS using a modern dataarchitecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Why telco should consider modern dataarchitecture. The challenges.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with data quality, and lack of cross-functional governance structure for customer data.
However, embedding ESG into an enterprise datastrategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG data integrity and fostering collaboration with sustainability teams.
The telecommunications industry continues to develop hybrid dataarchitectures to support data workload virtualization and cloud migration. Telco organizations are planning to move towards hybrid multi-cloud to manage data better and support their workforces in the near future. 2- AI capability drives data monetization.
The Cloudera Data Platform (CDP) represents a paradigm shift in modern dataarchitecture by addressing all existing and future analytical needs. AWS, Google or Azure) and thus allow for execution of a use case wherever it is most costs effective to do so. In particular, SDX enables clients to: .
HEMA has a bespoke enterprise architecture, built around the concept of services. Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. Tommaso is the Head of Data & Cloud Platforms at HEMA.
Four-layered data lake and data warehouse architecture – The architecture comprises four layers, including the analytical layer, which houses purpose-built facts and dimension datasets that are hosted in Amazon Redshift.
The world now runs on Big Data. Defined as information sets too large for traditional statistical analysis, Big Data represents a host of insights businesses can apply towards better practices. But what exactly are the opportunities present in big data? In manufacturing, this means opportunity.
They enable transactions on top of data lakes and can simplify data storage, management, ingestion, and processing. These transactional data lakes combine features from both the data lake and the data warehouse. Data can be organized into three different zones, as shown in the following figure.
These inputs reinforced the need of a unified datastrategy across the FinOps teams. We decided to build a scalable data management product that is based on the best practices of modern dataarchitecture. Data source locations hosted by the producer are created within the producer’s AWS Glue Data Catalog.
With an extensive career in the financial and tech industries, she specializes in data management and has been involved in initiatives ranging from reporting to dataarchitecture. She currently serves as the Global Head of Cyber Data Management at Zurich Group.
Transformation styles like TETL (transform, extract, transform, load) and SQL Pushdown also synergies well with a remote engine runtime to capitalize on source/target resources and limit data movement, thus further reducing costs. With a multicloud datastrategy, organizations need to optimize for data gravity and data locality.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
Earlier this month we hosted the second annual Data-Centric Architecture Forum (#DCAF2020) in Fort Collins, CO. Last year, (2019) we hosted the first Data-Centric Architecture conference. In 2019, the focus was on getting a sketch of a reference architecture (click here to see). Trip report).
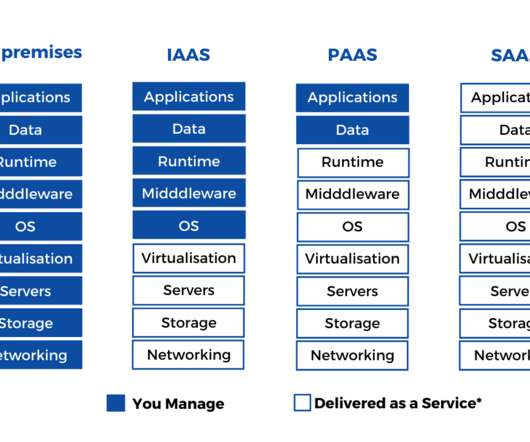
IaaS provides a platform for compute, data storage and networking capabilities. IaaS is mainly used for developing softwares (testing and development, batch processing), hosting web applications and data analysis. To try and test the platforms in accordance with datastrategy and governance. No pun intended.
The gold standard in data modeling solutions for more than 30 years continues to evolve with its latest release, highlighted by: PostgreSQL 16.x Migration and modernization : It enables seamless transitions between legacy systems and modern platforms, ensuring your dataarchitecture evolves without disruption.
In your project, in the navigation pane, choose Data. Choose the plus sign, and for Add data source , choose Add connection. For Data source name , enter postgresql_source. For Host , enter the host name of your Aurora PostgreSQL database cluster. Select PostgreSQL. For Database , enter your database name.
Under Add a data source , choose Add connection , then choose Amazon Redshift. Enter the following parameters in the connection details, and choose Add data. Host : Enter the Amazon Redshift managed VPC endpoint. He is also the author of Simplify Big Data Analytics with Amazon EMR and AWS Certified Data Engineer Study Guide.
This is the final part of a three-part series where we show how to build a data lake on AWS using a modern dataarchitecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content