This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Manish Limaye Pillar #1: Data platform The data platform pillar comprises tools, frameworks and processing and hosting technologies that enable an organization to process large volumes of data, both in batch and streaming modes. The choice of vendors should align with the broader cloud or on-premises strategy.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. The system had an integration with legacy backend services that were all hosted on premises. The downside here is over-provisioning.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
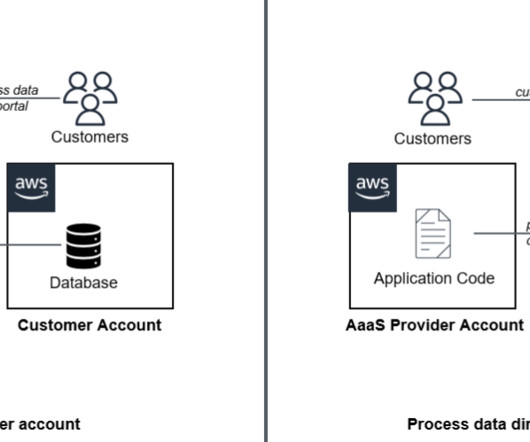
The AaaS model accelerates data-driven decision-making through advanced analytics, enabling organizations to swiftly adapt to changing market trends and make informed strategic choices. times better price-performance than other cloud datawarehouses. Data processing jobs enrich the data in Amazon Redshift.
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. About the Authors Songzhi Liu is a Principal Big Data Architect with the AWS Identity Solutions team.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. The producer account will host the EMR cluster and S3 buckets.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. The decoupled compute and storage architecture of Amazon Redshift enables you to build highly scalable, resilient, and cost-effective workloads.
The currently available choices include: The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR , Amazon DynamoDB , or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
Each data producer within the organization has its own data lake in Apache Hudi format, ensuring data sovereignty and autonomy. This enables data-driven decision-making across the organization. AWS Glue – Bluestone used the AWS Glue PySpark environment for implementing data extract, transform, and load (ETL) processes.
They enable transactions on top of data lakes and can simplify data storage, management, ingestion, and processing. These transactional data lakes combine features from both the data lake and the datawarehouse. Data can be organized into three different zones, as shown in the following figure.
Modern, real-time businesses require accelerated cycles of innovation that are expensive and difficult to maintain with legacy data platforms. The hybrid cloud’s premise—two dataarchitectures fused together—gives companies options to leverage those solutions and to address decision-making criteria, on a case-by-case basis. .
The Cloudera Data Platform (CDP) represents a paradigm shift in modern dataarchitecture by addressing all existing and future analytical needs. Technology cost reduction / avoidance. AWS, Google or Azure) and thus allow for execution of a use case wherever it is most costs effective to do so.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and data lakes can become equally challenging.
The AWS modern dataarchitecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your data lake and the datawarehouse. The following screenshot shows an example C360 dashboard built on QuickSight.
The Delta tables created by the EMR Serverless application are exposed through the AWS Glue Data Catalog and can be queried through Amazon Athena. Solution overview The following diagram shows the overall architecture of the solution that we implement in this post. Monjumi Sarma is a Data Lab Solutions Architect at AWS.
These sit on top of datawarehouses that are strictly governed by IT departments. The role of traditional BI platforms is to collect data from various business systems. Data Environment First off, the solutions you consider should be compatible with your current dataarchitecture.
SageMaker Lakehouse organizes data using logical containers called catalogs , enabling teams to seamlessly query and analyze data across their entire ecosystemfrom S3 data lakes to Amazon Redshift warehousesusing familiar Apache Iceberg compatible tools. An S3 bucket in the producer account to host the sample Iceberg table data.
Go to the Compute section of your project, and on the Datawarehouse tab, choose Add compute. Under Add a data source , choose Add connection , then choose Amazon Redshift. Enter the following parameters in the connection details, and choose Add data. Host : Enter the Amazon Redshift managed VPC endpoint.
This is the final part of a three-part series where we show how to build a data lake on AWS using a modern dataarchitecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content