

7 types of tech debt that could cripple your business
CIO Business Intelligence
MARCH 25, 2025
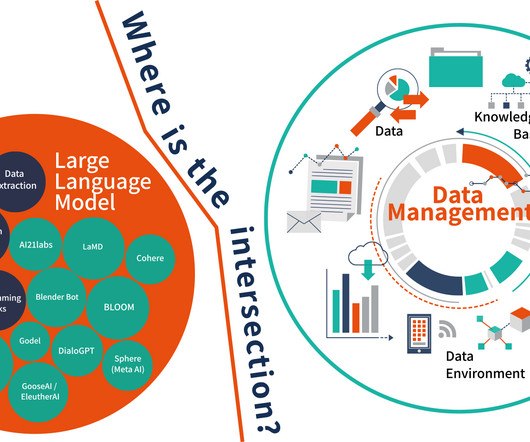
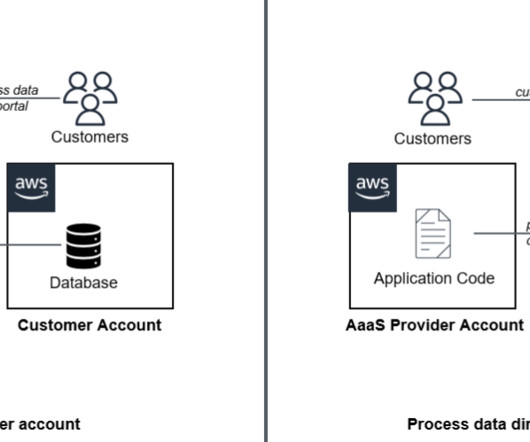
Types of data debt include dark data, duplicate records, and data that hasnt been integrated with master data sources. Using the companys data in LLMs, AI agents, or other generative AI models creates more risk. Playing catch-up with AI models may not be that easy.

















































Let's personalize your content