This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a data lake on AWS using a modern dataarchitecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Why telco should consider modern dataarchitecture. The challenges.
Build up: Databases that have grown in size, complexity, and usage build up the need to rearchitect the model and architecture to support that growth over time. It also anonymizes all PII so the cloud-hosted chatbot cant be fed private information.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau.
The telecommunications industry continues to develop hybrid dataarchitectures to support data workload virtualization and cloud migration. Telco organizations are planning to move towards hybrid multi-cloud to manage data better and support their workforces in the near future. 2- AI capability drives data monetization.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Choose Create.
Integrating ESG into data decision-making CDOs should embed sustainability into dataarchitecture, ensuring that systems are designed to optimize energy efficiency, minimize unnecessary data replication and promote ethical data use.
Modernizing a utility’s dataarchitecture. These capabilities allow us to reduce business risk as we move off of our monolithic, on-premise environments and provide cloud resiliency and scale,” the CIO says, noting National Grid also has a major data center consolidation under way as it moves more data to the cloud.
To create and manage the data products, smava uses Amazon Redshift , a cloud data warehouse. In this post, we show how smava optimized their data platform by using Amazon Redshift Serverless and Amazon Redshift data sharing to overcome right-sizing challenges for unpredictable workloads and further improve price-performance.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
The new approach would need to offer the flexibility to integrate new technologies such as machine learning (ML), scalability to handle long-term retention at forecasted growth levels, and provide options for cost optimization. Athena supports a variety of compression formats for reading and writing data.
The technological linchpin of its digital transformation has been its Enterprise DataArchitecture & Governance platform. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
The Cloudera Data Platform (CDP) represents a paradigm shift in modern dataarchitecture by addressing all existing and future analytical needs. Infrastructure cost optimization. reduce technology costs, accelerate organic growth initiatives). Business value acceleration. In particular, SDX enables clients to: .
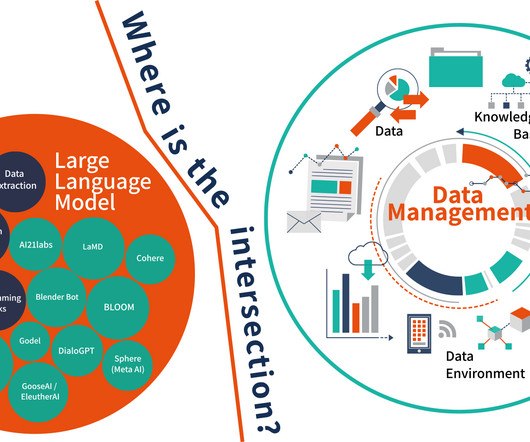
I did some research because I wanted to create a basic framework on the intersection between large language models (LLM) and data management. But there are also a host of other issues (and cautions) to take into consideration. Another concern relates to the definition of ‘data constraints.’
These topics include federation with the Swisscom identity provider (IdP), JDBC connections, detective controls using AWS Config rules and remediation actions, cost optimization using the Redshift scheduler, and audit logging. The following high-level architecture diagram shows ODP with different layers of the modern dataarchitecture.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and data lakes can become equally challenging.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. HEMA has a bespoke enterprise architecture, built around the concept of services. Tommaso is the Head of Data & Cloud Platforms at HEMA.
But this glittering prize might cause some organizations to overlook something significantly more important: constructing the kind of event-driven dataarchitecture that supports robust real-time analytics. An event-based, real-time dataarchitecture is precisely how businesses today create the experiences that consumers expect.
Combined with the characteristics of the infrastructure itself (location, cost, performance) should be workload profiles, including access controls and collaboration, workload optimization features (e.g. for machine learning), and other enterprise policies.
The size of the data sets is limited by business concerns. Use renewable energy Hosting AI operations at a data center that uses renewable power is a straightforward path to reduce carbon emissions, but it’s not without tradeoffs.
The currently available choices include: The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR , Amazon DynamoDB , or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
With data becoming the driving force behind many industries today, having a modern dataarchitecture is pivotal for organizations to be successful. This data is sent to Apache Kafka, which is hosted on Amazon Managed Streaming for Apache Kafka (Amazon MSK).
Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc. The gigantic evolution of structured, unstructured, and semi-structured data is referred to as Big data. Self-Service.
Cisco has multiple reference architectures for running Ozone. The hardware certification includes high density nodes with close to 500 TB per node optimized for performance and TCO. Data processing workloads tend to be more sensitive to the performance of transferring data between Datanodes and the various applications that process it.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
The main reason for this change is that this title better represents the move that our customers are making; away from acknowledging the ability to have data ‘anywhere’. It delivers the same data management capabilities across all of these disparate environments.
The architecture consists of many layers: Rules engine – The rules engine was responsible for intercepting every incoming request. Based on the nature of the request, it routed the request to the API cluster that could optimally process that specific request based on the response time requirement.
These inputs reinforced the need of a unified data strategy across the FinOps teams. We decided to build a scalable data management product that is based on the best practices of modern dataarchitecture. Our source system and domain teams were mapped as data producers, and they would have ownership of the datasets.
Transformation styles like TETL (transform, extract, transform, load) and SQL Pushdown also synergies well with a remote engine runtime to capitalize on source/target resources and limit data movement, thus further reducing costs. With a multicloud data strategy, organizations need to optimize for data gravity and data locality.
The last two years have seen remarkable acceleration of digital transformation in a whole host of segments. The data spun off its business is remarkable allowing advanced analytics use cases such as: Business Category. Marketing and Sales Optimization – . Pricing Optimization – . By 2025, Industry 4.0
Tracking data changes and rollback Build your transactional data lake on AWS You can build your modern dataarchitecture with a scalable data lake that integrates seamlessly with an Amazon Redshift powered cloud warehouse. Data can be organized into three different zones, as shown in the following figure.
Cost and resource efficiency – This is an area where Acast observed a reduction in data duplication, and therefore cost reduction (in some accounts, removing the copy of data 100%), by reading data across accounts while enabling scaling.
Here’s what a few our judges had to say after reviewing and scoring nominations: “The nominations showed highly creative, innovative ways of using data, analytics, data science and predictive methodologies to optimize processes and to provide more positive customer experiences. ” – Cornelia Levy-Bencheton. .”
Most organisations are missing this ability to connect all the data together. from Q&A with Tim Berners-Lee ) Finally, Sumit highlighted the importance of knowledge graphs to advance semantic dataarchitecture models that allow unified data access and empower flexible data integration.
Amazon Redshift is straightforward to use with self-tuning and self-optimizing capabilities. You can get faster insights without spending valuable time managing your data warehouse. All data written to Amazon Redshift is automatically and continuously replicated to Amazon Simple Storage Service (Amazon S3).
Migration and modernization : It enables seamless transitions between legacy systems and modern platforms, ensuring your dataarchitecture evolves without disruption. Migration and modernization : It enables seamless transitions between legacy systems and modern platforms, ensuring your dataarchitecture evolves without disruption.
VeloxCon 2024 , the premier developer conference that is dedicated to the Velox open-source project, brought together industry leaders, engineers, and enthusiasts to explore the latest advancements and collaborative efforts shaping the future of data management.
3- Advanced AI Integration At this stage of adoption, financial institutions and insurance companies engage more intensively with AI and its capabilities, extracting more valuable insights from data. Push predictive analytics to optimize operations and enhance profitability. Even more training and upskilling.
Misconception 3: All data warehouse migrations are the same, irrespective of vendors While migrating to the cloud, CTOs often feel the need to revamp and “modernize” their entire technology stack – including moving to a new cloud data warehouse vendor. This enabled data-driven analytics at scale across the organization 4.
Alation Connect previously synced metadata and query logs from data storage systems including the Hive Metastore on Hadoop and databases from Teradata, IBM, Oracle, SqlServer, Redshift, Vertica, SAP Hana and Greenplum. Get the latest data cataloging news and trends in your inbox. In the release of Alation 4.0,
Strategize based on how your teams explore data, run analyses, wrangle data for downstream requirements, and visualize data at different levels. The AWS modern dataarchitecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud.
The Delta tables created by the EMR Serverless application are exposed through the AWS Glue Data Catalog and can be queried through Amazon Athena. Solution overview The following diagram shows the overall architecture of the solution that we implement in this post. Monjumi Sarma is a Data Lab Solutions Architect at AWS.
The platform has been used to modernize and unify the information technology (IT) ecosystem of major financial firms, simplify human capital management (HCM) across brands’ subsidiaries, and optimize reporting processes in complex healthcare settings.
The selection of the best BI tools stands as a critical step in leveraging data effectively, driving success, and maintaining competitive advantage in modern markets. Data-driven Decisions: BI tools empower businesses to make informed decisions by furnishing actionable insights, optimizing operations, and uncovering growth opportunities.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content