This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To succeed in todays landscape, every company small, mid-sized or large must embrace a data-centric mindset. This article proposes a methodology for organizations to implement a modern data management function that can be tailored to meet their unique needs.
Refer to How can I access OpenSearch Dashboards from outside of a VPC using Amazon Cognito authentication for a detailed evaluation of the available options and the corresponding pros and cons. For more information, refer to the AWS CDK v2 Developer Guide. For instructions, refer to Creating a public hosted zone.
Refer to IAM Identity Center identity source tutorials for the IdP setup. Copy and save the client ID and client secret needed later for the Streamlit application and the IAM Identity Center application to connect using the Redshift Data API. For more details, refer to Creating a workgroup with a namespace.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Choose Create.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and data lakes can become equally challenging. Example Corp.
In a two-part series, we talk about Swisscom’s journey of automating Amazon Redshift provisioning as part of the Swisscom ODP solution using the AWS Cloud Development Kit (AWS CDK), and we provide code snippets and the other useful references. See the following admin user code: admin_secret_kms_key_options = KmsKeyOptions(.
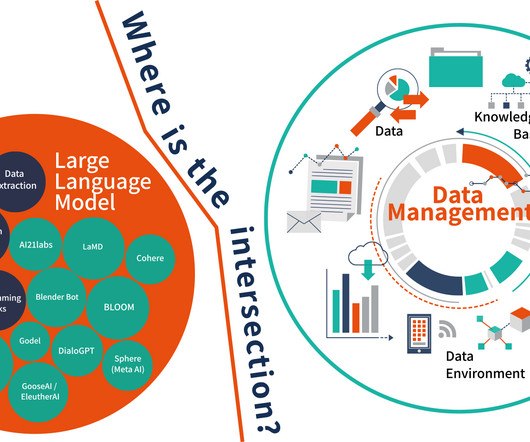
I did some research because I wanted to create a basic framework on the intersection between large language models (LLM) and data management. But there are also a host of other issues (and cautions) to take into consideration. It was emphasized many times that LLMs are only as good as the data sources.
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
But this glittering prize might cause some organizations to overlook something significantly more important: constructing the kind of event-driven dataarchitecture that supports robust real-time analytics. We can, in the semantics of the software world, refer to digitally mediated business activities asreal-time events.
Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc. The gigantic evolution of structured, unstructured, and semi-structured data is referred to as Big data. Videos, pictures etc.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
Earlier this month we hosted the second annual Data-Centric Architecture Forum (#DCAF2020) in Fort Collins, CO. Last year, (2019) we hosted the first Data-Centric Architecture conference. In 2019, the focus was on getting a sketch of a referencearchitecture (click here to see). Trip report).
The currently available choices include: The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR , Amazon DynamoDB , or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
To create it, refer to Tutorial: Get started with Amazon EC2 Windows instances. To download and install AWS SCT on the EC2 instance that you created, refer to Installing, verifying, and updating AWS SCT. For more information about bucket names, refer to Bucket naming rules. Select Redshift data agent , then choose OK.
Uncomfortable truth incoming: Most people in your organization don’t think about the quality of their data from intake to production of insights. However, as a data team member, you know how important data integrity (and a whole host of other aspects of data management) is. Means of ensuring data integrity.
Just because technology is easy to use, it does not follow that the data is easy to understand. Don’t be fooled by easy-to-use technology; data can still be hard. Logic Apps are hosted in Azure and have a code view rather than a ‘business user coder’ view. Compliant or Complaint?
Cisco has multiple referencearchitectures for running Ozone. Relevance of Operations per Second to Scale Ozone Manager hosts the metadata for the Objects stored within Ozone and consists of a cluster of Ozone Manager instances replicated via Ratis (a raft implementation ).
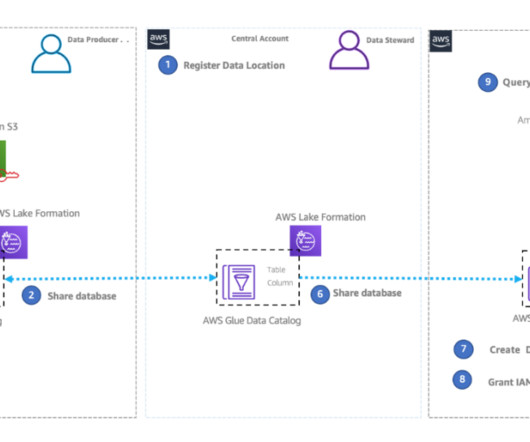
Cost and resource efficiency – This is an area where Acast observed a reduction in data duplication, and therefore cost reduction (in some accounts, removing the copy of data 100%), by reading data across accounts while enabling scaling. In this approach, teams responsible for generating data are referred to as producers.
When data is moved to the Infrequent Access tier, costs are reduced by up to 40%. Similarly, when data is moved to the Archive Instant Access tier, storage costs are reduced by up to 68%. Refer to Amazon S3 pricing for current pricing, as well as for information by region.
An essential capability needed in such a data lake architecture is the ability to continuously understand changes in the data lakes in various other domains and make those available to data consumers. The data mesh producer account hosts the encrypted S3 bucket, which is shared with the central governance account.
Overall, the current architecture didn’t support workload prioritization, therefore a physical model of resources was reserved for this reason. The system had an integration with legacy backend services that were all hosted on premises. Solution overview Amazon Redshift is an industry-leading cloud data warehouse.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
The Delta tables created by the EMR Serverless application are exposed through the AWS Glue Data Catalog and can be queried through Amazon Athena. Solution overview The following diagram shows the overall architecture of the solution that we implement in this post. Let’s refer to this S3 bucket as the raw layer.
Alation Connect synchronizes metadata, sample data, and query logs into the Alation Data Catalog. This rich usage context is what makes our Data Catalog a powerful point of reference for data consumers and data stewards. In the release of Alation 4.0, In the release of Alation 4.0,
The data mesh framework In the dynamic landscape of data management, the search for agility, scalability, and efficiency has led organizations to explore new, innovative approaches. One such innovation gaining traction is the data mesh framework. This empowers individual teams to own and manage their data.
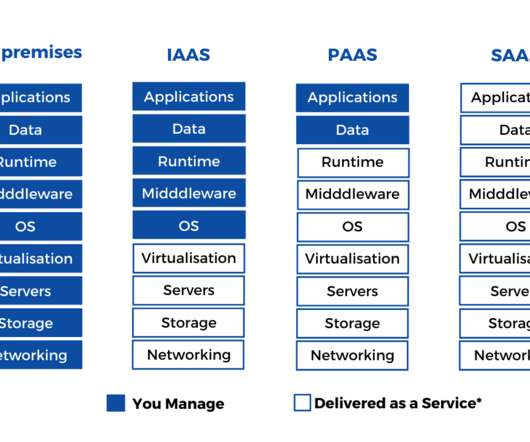
IaaS provides a platform for compute, data storage and networking capabilities. IaaS is mainly used for developing softwares (testing and development, batch processing), hosting web applications and data analysis. Companies develop data ecosystems on the cloud, the dataarchitecture is now independent of on-premise systems.
When building a scalable dataarchitecture on AWS, giving autonomy and ownership to the data domains are crucial for the success of the platform. Solution overview In the first post of this series, we explained how Novo Nordisk and AWS Professional Services built a modern dataarchitecture based on data mesh tenets.
It is prudent to consolidate this data into a single customer view, serving as a primary reference for downstream applications, ranging from ecommerce platforms to CRM systems. This consolidated view acts as a liaison between the data platform and customer-centric applications.
Metadata exporter This section provides details on the AWS Glue job that exports the AWS Glue Data Catalog into an S3 location. The source code for the application is hosted the AWS Glue GitHub. He advises clients on architecting and adopting DataArchitectures that best serve their Data Analytics and Machine Learning needs.
On Thursday January 6th I hosted Gartner’s 2022 Leadership Vision for Data and Analytics webinar. Most of D&A concerns and activities are done within EA in the Info/Dataarchitecture domain/phases. Here is a suggested note: Use Gartner’s Reference Model to Deliver Intelligent Composable Business Applications.
that gathers data from many sources. Data Environment First off, the solutions you consider should be compatible with your current dataarchitecture. We have outlined the requirements that most providers ask for: Data Sources Strategic Objective Use native connectivity optimized for the data source.
The Lambda function will invoke the Amazon Titan Text Embeddings Model hosted in Amazon Bedrock , allowing for efficient and scalable embedding creation. This architecture simplifies various use cases, including recommendation engines, personalized chatbots, and fraud detection systems.
In modern dataarchitectures, the need to manage and query vast datasets efficiently, consistently, and accurately is paramount. For organizations that deal with big data processing, managing metadata becomes a critical concern. Any reference to HMS refers to a Standalone Hive Metastore.
This is the final part of a three-part series where we show how to build a data lake on AWS using a modern dataarchitecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content