This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
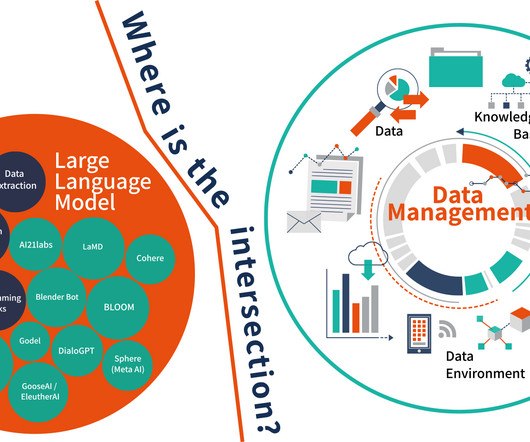
I did some research because I wanted to create a basic framework on the intersection between large language models (LLM) and data management. But there are also a host of other issues (and cautions) to take into consideration. Another concern relates to the definition of ‘data constraints.’
Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc. The gigantic evolution of structured, unstructured, and semi-structureddata is referred to as Big data. Self-Service.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structureddata) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. The system had an integration with legacy backend services that were all hosted on premises.
Overview of solution As a data-driven company, smava relies on the AWS Cloud to power their analytics use cases. smava ingests data from various external and internal data sources into a landing stage on the data lake based on Amazon Simple Storage Service (Amazon S3).
They classified the metrics and indicators in the following categories: Data usage – A clear understanding of who is consuming what data source, materialized with a mapping of consumers and producers. For other organizations, the desired data mesh might look different and the approach might have other learnings.
Strategize based on how your teams explore data, run analyses, wrangle data for downstream requirements, and visualize data at different levels. The AWS modern dataarchitecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud.
This is the final part of a three-part series where we show how to build a data lake on AWS using a modern dataarchitecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. In our use case, we use Redshift Query Editor to create data marts using SQL code.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content