This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Model developers will test for AI bias as part of their pre-deployment testing. Quality test suites will enforce “equity,” like any other performance metric. Data Gets Meshier.
Build up: Databases that have grown in size, complexity, and usage build up the need to rearchitect the model and architecture to support that growth over time. What CIOs can do: To make transitions to new AI capabilities less costly, invest in regression testing and change management practices around AI-enabled large-scale workflows.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Choose Test Connection.
Manish Limaye Pillar #1: Data platform The data platform pillar comprises tools, frameworks and processing and hosting technologies that enable an organization to process large volumes of data, both in batch and streaming modes. He is currently a technology advisor to multiple startups and mid-size companies.
Copy and save the client ID and client secret needed later for the Streamlit application and the IAM Identity Center application to connect using the Redshift Data API. Generate the client secret and set sign-in redirect URL and sign-out URL to [link] (we will host the Streamlit application locally on port 8501). and v3.12.2.
Test access to the producer cataloged Amazon S3 data using EMR Serverless in the consumer account. Test access using Athena queries in the consumer account. Test access using SageMaker Studio in the consumer account. It is recommended to use test accounts. The catalog account will host Lake Formation and AWS Glue.
Create an Amazon Route 53 public hosted zone such as mydomain.com to be used for routing internet traffic to your domain. For instructions, refer to Creating a public hosted zone. Request an AWS Certificate Manager (ACM) public certificate for the hosted zone. hosted_zone_id – The Route 53 public hosted zone ID.
Weston uses uplift modeling, running a series of A/B tests to determine how potential customers respond to different offers, and then uses the results of those tests to build the model. The size of the data sets is limited by business concerns.
Uncomfortable truth incoming: Most people in your organization don’t think about the quality of their data from intake to production of insights. However, as a data team member, you know how important data integrity (and a whole host of other aspects of data management) is. Data integrity: A process and a state.
One Data Platform The ODP architecture is based on the AWS Well Architected Framework Analytics Lens and follows the pattern of having raw, standardized, conformed, and enriched layers as described in Modern dataarchitecture. See the following admin user code: admin_secret_kms_key_options = KmsKeyOptions(.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
While navigating so many simultaneous data-dependent transformations, they must balance the need to level up their data management practices—accelerating the rate at which they ingest, manage, prepare, and analyze data—with that of governing this data.
Overview of solution As a data-driven company, smava relies on the AWS Cloud to power their analytics use cases. smava ingests data from various external and internal data sources into a landing stage on the data lake based on Amazon Simple Storage Service (Amazon S3).
But information broadly, and the management of data specifically, is still “the” critical factor for situational awareness, streamlined operations, and a host of other use cases across today’s tech-driven battlefields. . With over 400 connectors and processors , UDD enables a broad range of data distribution capabilities. .
Over the years, data lakes on Amazon Simple Storage Service (Amazon S3) have become the default repository for enterprise data and are a common choice for a large set of users who query data for a variety of analytics and machine leaning use cases. Analytics use cases on data lakes are always evolving. Choose ETL Jobs.
HEMA has a bespoke enterprise architecture, built around the concept of services. Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. Amazon DataZone is the central piece in this architecture.
Integrating ESG into data decision-making CDOs should embed sustainability into dataarchitecture, ensuring that systems are designed to optimize energy efficiency, minimize unnecessary data replication and promote ethical data use.
Choose Test connection to verify that AWS SCT can connect to your source Azure Synapse project. Choose Test connection to verify that AWS SCT can connect to your target Redshift workgroup. When the test is successful, choose OK. Select Redshift data agent , then choose OK. to indicate local host. Choose Test Task.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
And not only do companies have to get all the basics in place to build for analytics and MLOps, but they also need to build new data structures and pipelines specifically for gen AI. And for some use cases, an expensive, high-end commercial LLM might not be required since a locally-hosted open source model might suffice.
Overall, the current architecture didn’t support workload prioritization, therefore a physical model of resources was reserved for this reason. The system had an integration with legacy backend services that were all hosted on premises. Solution overview Amazon Redshift is an industry-leading cloud data warehouse.
Assemble a cross-collaborative implementation team with well-defined roles and identify major stakeholders to consult and test the system as the project moves forward. During configuration, an organization constructs its dataarchitecture and defines user roles. Security: Ensure all sensitive data is stored appropriately.
Historic data analysis – Data stored in Amazon S3 can be queried to satisfy one-time audit or analysis tasks. Eventually, this data could be used to train ML models to support better anomaly detection. Zurich has done testing with Amazon SageMaker and has plans to add this capability in the near future.
Introduce advanced AI training and programs, including hands-on projects that simulate real-world financial scenarios, or mentorship programs hosted by AI experts. Prepare for higher AI demands, assessing the state of the institution’s infrastructure capacity while taking Into account future data processing needs.
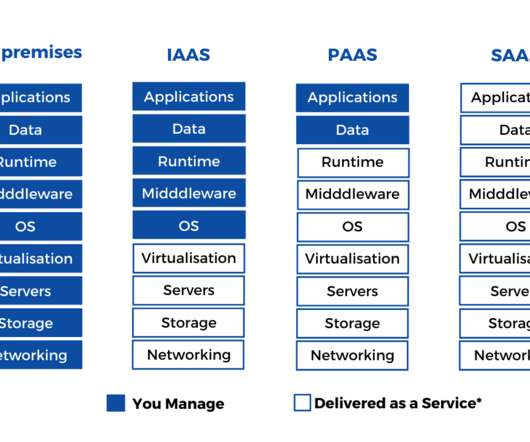
IaaS provides a platform for compute, data storage and networking capabilities. IaaS is mainly used for developing softwares (testing and development, batch processing), hosting web applications and data analysis. To try and test the platforms in accordance with data strategy and governance.
The gold standard in data modeling solutions for more than 30 years continues to evolve with its latest release, highlighted by: PostgreSQL 16.x Migration and modernization : It enables seamless transitions between legacy systems and modern platforms, ensuring your dataarchitecture evolves without disruption.
Through meticulous testing and research, we’ve curated a list of the ten best BI tools, ensuring accessibility and efficacy for businesses of all sizes. The selection of the best BI tools stands as a critical step in leveraging data effectively, driving success, and maintaining competitive advantage in modern markets.
But Barnett, who started work on a strategy in 2023, wanted to continue using Baptist Memorial’s on-premise data center for financial, security, and continuity reasons, so he and his team explored options that allowed for keeping that data center as part of the mix.
Data Environment First off, the solutions you consider should be compatible with your current dataarchitecture. We have outlined the requirements that most providers ask for: Data Sources Strategic Objective Use native connectivity optimized for the data source. Do what you expect your customers to do.
In modern dataarchitectures, the need to manage and query vast datasets efficiently, consistently, and accurately is paramount. For organizations that deal with big data processing, managing metadata becomes a critical concern. Note that this implementation hasnt been tested with other EMR on EKS Spark job submission types.
Permissions from Prerequisites for managing Amazon Redshift namespaces in the AWS Glue Data Catalog granted to the Lake Formation administrator role on both accounts. An S3 bucket in the producer account to host the sample Iceberg table data. Test this solution in your accounts and share feedback in the comments section.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content