This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Race For DataQuality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer?
Today, we are pleased to announce that Amazon DataZone is now able to present dataquality information for data assets. Other organizations monitor the quality of their data through third-party solutions. Additionally, Amazon DataZone now offers APIs for importing dataquality scores from external systems.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
SageMaker still includes all the existing ML and AI capabilities you’ve come to know and love for data wrangling, human-in-the-loop data labeling with Amazon SageMaker Ground Truth , experiments, MLOps, Amazon SageMaker HyperPod managed distributed training, and more. Having confidence in your data is key.
Some customers build custom in-house data parity frameworks to validate data during migration. Others use open source dataquality products for data parity use cases. This takes away important person hours from the actual migration effort into building and maintaining a data parity framework.
Due to the volume, velocity, and variety of data being ingested in data lakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your data lake. Data confidentiality and dataquality are the two essential themes for data governance.
This complex process involves suppliers, logistics, quality control, and delivery. This post describes how HPE Aruba automated their Supply Chain management pipeline, and re-architected and deployed their data solution by adopting a modern dataarchitecture on AWS.
To succeed in todays landscape, every company small, mid-sized or large must embrace a data-centric mindset. This article proposes a methodology for organizations to implement a modern data management function that can be tailored to meet their unique needs. Implementing ML capabilities can help find the right thresholds.
In modern dataarchitectures, Apache Iceberg has emerged as a popular table format for data lakes, offering key features including ACID transactions and concurrent write support. For more detailed configuration, refer to Write properties in the Iceberg documentation.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. The program must introduce and support standardization of enterprise data.
In turn, they both must also have the data literacy skills to be able to verify the data’s accuracy, ensure its security, and provide or follow guidance on when and how it should be used. Data democratization uses a fit-for-purpose dataarchitecture that is designed for the way today’s businesses operate, in real-time.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. Based on business rules, additional dataquality tests check the dimensional model after the ETL job completes. A DataOps implementation project consists of three steps.
Data governance is increasingly top-of-mind for customers as they recognize data as one of their most important assets. Effective data governance enables better decision-making by improving dataquality, reducing data management costs, and ensuring secure access to data for stakeholders.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Uncomfortable truth incoming: Most people in your organization don’t think about the quality of their data from intake to production of insights. However, as a data team member, you know how important data integrity (and a whole host of other aspects of data management) is. Means of ensuring data integrity.
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source data lake. What is a data fabric?
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machine learning (ML) and artificial intelligence (AI).
The goal of a data product is to solve the long-standing issue of data silos and dataquality. Independent data products often only have value if you can connect them, join them, and correlate them to create a higher order data product that creates additional insights.
DataArchitecture – Definition (2). Data Catalogue. Data Community. Data Domain (contributor: Taru Väre ). Data Enrichment. Data Federation. Data Function. Data Model. Data Operating Model. Geospatial Data. ReferenceData (contributor: George Firican ).
Realize that a data governance program cannot exist on its own – it must solve business problems and deliver outcomes. Start by identifying business objectives, desired outcomes, key stakeholders, and the data needed to deliver these objectives. So where are you in your data governance journey?
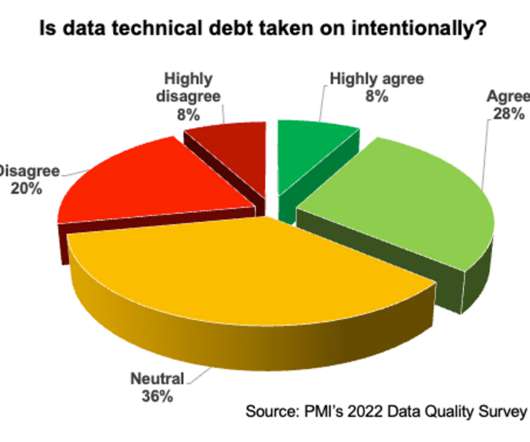
“Technical debt” refers to the implied cost of future refactoring or rework to improve the quality of an asset to make it easy to understand, work with, maintain, and extend.
The data mesh framework In the dynamic landscape of data management, the search for agility, scalability, and efficiency has led organizations to explore new, innovative approaches. One such innovation gaining traction is the data mesh framework. Business Glossaries – what is the business meaning of our data?
The term “data analytics” refers to the process of examining datasets to draw conclusions about the information they contain. Data analysis techniques enhance the ability to take raw data and uncover patterns to extract valuable insights from it.
Control of Data to ensure it is Fit-for-Purpose. This refers to a wide range of activities from Data Governance to Data Management to DataQuality improvement and indeed related concepts such as Master Data Management. DataArchitecture / Infrastructure.
Big Data technology in today’s world. Did you know that the big data and business analytics market is valued at $198.08 Or that the US economy loses up to $3 trillion per year due to poor dataquality? quintillion bytes of data which means an average person generates over 1.5 megabytes of data every second?
Breaking down these silos to encourage data access, data sharing and collaboration will be an important challenge for organizations in the coming years. The right dataarchitecture to link and gain insight across silos requires the communication and coordination of a strategic data governance program.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data.
Consume data assets as part of analyzing data to generate insights. Part 1: Set up account governance and identity management Before you start, compare your current cloud environment, including dataarchitecture, to ATPCO’s environment. Clear Dataquality unless you have already set up AWS Glue dataquality.
Bad data tax is rampant in most organizations. Currently, every organization is blindly chasing the GenAI race, often forgetting that dataquality and semantics is one of the fundamentals to achieving AI success. Sadly, dataquality is losing to data quantity, resulting in “ Infobesity ”. “Any
Like many, the team at Cbus wanted to use data to more effectively drive the business. “Finding the right data was a real challenge,” recalls John Gilbert, Data Governance Manager. “There was no single source of reference, there was no catalog to leverage, and it was unclear who to ask or seek assistance from.”
Business users often think that data is something technical that it is not their concern. While IT is happy to look after the technical storage and backup of data, they refer to line of business experts when it comes to quality and usability. They believe the IT department should take care of it.
All the references I can find to it are modern pieces comparing it to the CDO role, so perhaps it is apochryphal. This may purely be focused on cultural aspects of how an organisation records, shares and otherwise uses data. It may be to build a new (or a first) DataArchitecture. It may be to improve DataQuality.
Both use cases use semantic metadata, which describes information sources with respect to a unified conceptual model , that includes ontologies, data schema, taxonomies, referencedata, or other domain knowledge. They sift through documents, generate metadata, and store it in the knowledge graph.
We hope your Data Management career and programs are progressing well. If you have issues, please refer to DAMA.org for references, as well as the DAMA Data Management Body of Knowledge (DMBok). Good day from DAMA International. You can purchase the DMBoK at your favorite book source or via website link.
They have to misallocate resources because 80% of the time the data scientists are busy doing data finding, accessing, cleansing, etc. This also results in the information loss I’ve already mentioned and severely impacts our insight creation and monetizing the data. So Schemata are interoperable by design.
The data catalog is a foundational layer of the data fabric. This zoomed-in version has references to corresponding vendor markets removed.). Using this diagram as our guide, this blog will deep-dive into each layer of the data fabric, starting with the data catalog. Alation Data Catalog for the data fabric.
If you want to convert your data into the right insights to drive business decisions and processes, you need this data to be easily accessible and stored in a format that is flexible, accurate, and machine-readable. It must retain the context and insight of the original data and be traceable as it flows through the organization.
Most of D&A concerns and activities are done within EA in the Info/Dataarchitecture domain/phases. – I remember that I tried to answer this live during the webinar. – We see most, if not all, of data management being augmented with ML. – I am not totally sure what you mean by data capture.
Convergent Evolution refers to something else. Even back then, these were used for activities such as Analytics , Dashboards , Statistical Modelling , Data Mining and Advanced Visualisation. Of course some architectures featured both paradigms as well. So far so simple.
It allows organizations to see how data is being used, where it is coming from, its quality, and how it is being transformed. DataOps Observability includes monitoring and testing the data pipeline, dataquality, data testing, and alerting. Data observability and data lineage are complementary concepts.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content