This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern dataarchitectures.
Dataarchitecture is a complex and varied field and different organizations and industries have unique needs when it comes to their data architects. Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and data lakes.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with data quality, and lack of cross-functional governance structure for customer data.
Data is commonly referred to as the new oil, a resource so immensely powerful that its true potential is yet to be discovered. We haven’t achieved enough with data research and other statistical modeling techniques to be able to see data for what it truly is and even our methods of accruing data are rudimentary […].
In turn, they both must also have the data literacy skills to be able to verify the data’s accuracy, ensure its security, and provide or follow guidance on when and how it should be used. Data democratization uses a fit-for-purpose dataarchitecture that is designed for the way today’s businesses operate, in real-time.
While IT is happy to look after the technical storage and backup of data, they refer to line of business experts when it comes to quality and usability. Managers see data as relevant in the context of digitalization, but often think of data-related problems as minor details that have little strategic importance.
In this post, we are excited to summarize the features that the AWS Glue Data Catalog, AWS Glue crawler, and Lake Formation teams delivered in 2022. Whether you are a data platform builder, data engineer, data scientist, or any technology leader interested in data lake solutions, this post is for you.
Independent data products often only have value if you can connect them, join them, and correlate them to create a higher order data product that creates additional insights. A modern dataarchitecture is critical in order to become a data-driven organization.
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies.
Simply put, the term cloud-agnostic refers to the ability to move applications or parts of applications from one cloud platform to another. What does it mean for your data? Let’s dive into what you should consider in a BI platform to ensure you’re protecting and future-proofing your company’s datastrategy.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern dataarchitecture implementations on the AWS Cloud. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
First off, this involves defining workflows for every business process within the enterprise: the what, how, why, who, when, and where aspects of data. These regulations, ultimately, ensure key business values: data consistency, quality, and trustworthiness.
Realize that a data governance program cannot exist on its own – it must solve business problems and deliver outcomes. Start by identifying business objectives, desired outcomes, key stakeholders, and the data needed to deliver these objectives. Don’t try to do everything at once!
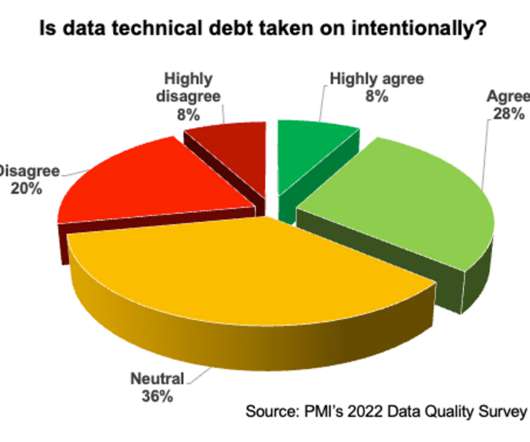
“Technical debt” refers to the implied cost of future refactoring or rework to improve the quality of an asset to make it easy to understand, work with, maintain, and extend.
Though you may encounter the terms “data science” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts.
Amazon Kinesis and Amazon MSK also have capabilities to stream data directly to a data lake on Amazon S3. S3 data lake Using Amazon S3 for your data lake is in line with the modern datastrategy. With this approach, you can bring compute to your data as needed and only pay for capacity it needs to run.
Is there a difference between open data and public data? There is a general consensus that when we talk about open data, we are referring to any piece of data or content that is free to access, use, reuse, and redistribute. And it’s a big one. Due to the way most governments have rolled out […].
In the thirteen years that have passed since the beginning of 2007, I have helped ten organisations to develop commercially-focused DataStrategies [1]. However, in this initial article, I wanted to to focus on one tool that I have used as part of my DataStrategy engagements; a Data Maturity Model.
Unless you’ve been living in a cave somewhere, you’ve certainly heard news about stolen and hacked data, commonly referred to as data breaches. They occur with great regularity, and there is no indication that the frequency of data breaches is slowing down.
Control of Data to ensure it is Fit-for-Purpose. This refers to a wide range of activities from Data Governance to Data Management to Data Quality improvement and indeed related concepts such as Master Data Management. DataArchitecture / Infrastructure. DataStrategy.
For instructions, refer to Amazon DataZone quickstart with AWS Glue data. You also need to define and run a ruleset against your data, which is a set of data quality rules in AWS Glue Data Quality. To learn more about Amazon DataZone, refer to the Amazon DataZone User Guide. option("header", "true").option("inferSchema",
In the next stage of the cycle, Huron’s consultants experiment with new data sources and insights that in turn fed back into the product dashboards. This access to the metadata supports the need for updating visuals based on changes as well as automating row and column level security ensuring customer data is properly governed.
When data is moved to the Infrequent Access tier, costs are reduced by up to 40%. Similarly, when data is moved to the Archive Instant Access tier, storage costs are reduced by up to 68%. Refer to Amazon S3 pricing for current pricing, as well as for information by region.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
To learn more about how to enable semantic search on unstructured data by integrating Amazon OpenSearch Service as a vector database, refer to Try semantic search with the Amazon OpenSearch Service vector engine. He is also the author of the book Simplify Big Data Analytics with Amazon EMR.
The comprehensive system which collectively includes generating data, storing the data, aggregating and analyzing the data, the tools, platforms and other softwares involved is referred to as Big Data Ecosystem. Data Management. Challenges associated with Data Management and Optimizing Big Data.
Prelude… I recently came across an article in Marketing Week with the clickbait-worthy headline of Why the rise of the chief data officer will be short-lived (their choice of capitalisation). All the references I can find to it are modern pieces comparing it to the CDO role, so perhaps it is apochryphal.
Breaking down these silos to encourage data access, data sharing and collaboration will be an important challenge for organizations in the coming years. The right dataarchitecture to link and gain insight across silos requires the communication and coordination of a strategic data governance program.
Like many, the team at Cbus wanted to use data to more effectively drive the business. “Finding the right data was a real challenge,” recalls John Gilbert, Data Governance Manager. “There was no single source of reference, there was no catalog to leverage, and it was unclear who to ask or seek assistance from.”
Without a well-thought of datastrategy and framework in place, the cloud strategy could prove to be more expensive than it has to be. To try and test the platforms in accordance with datastrategy and governance. Through every phase of cloud adoption, well, sky is still the limit. No pun intended.
Earlier this month we hosted the second annual Data-Centric Architecture Forum (#DCAF2020) in Fort Collins, CO. Last year, (2019) we hosted the first Data-Centric Architecture conference. In 2019, the focus was on getting a sketch of a referencearchitecture (click here to see). These are the highlights.
In reference to the prior column on enterprise data management and high level lego framework, this column reviews in detail the foundational layer of Organization Mission, Level 1.
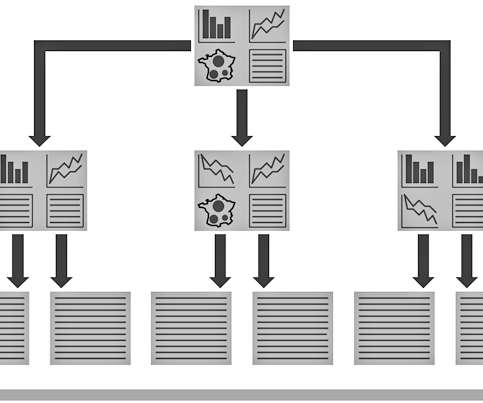
Most data is not static. No, data has a life in which it changes, is used for perhaps multiple purposes, and gets moved all over the place. So, it makes sense to think about the lifecycle of your data at your organization. The accompanying diagram helps to demonstrate this lifecycle.
I have been very much focussing on the start of a data journey in a series of recent articles about DataStrategy [3]. The way that this consistency of figures is achieved is by all elements of the Structured Reporting Framework drawing their data from the same data repositories. Introduction.
We hope your Data Management career and programs are progressing well. If you have issues, please refer to DAMA.org for references, as well as the DAMA Data Management Body of Knowledge (DMBok). Good day from DAMA International. You can purchase the DMBoK at your favorite book source or via website link.
Note: Here an “axis” is a fixed reference line (sometimes invisible for stylistic reasons) which typically goes vertically up the page or horizontally from left to right across the page (but see also Radar Charts ). I use Radar Charts myself extensively when assessing organisations’ data capabilities. Scatter Charts.
This type of data landscape is usually created using innovative data discovery tools like Amundsen , Nemo , and DataHub as part of a company’s data transformation efforts. The use cases and customer outcomes your data supports and the quantifiable value your data creates for the business.
We also decided to use Amazon EMR managed scaling to scale the core and task nodes (for scaling scenarios, refer to Node allocation scenarios ). He is also the author of the book Simplify Big Data Analytics with Amazon EMR. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family.
This is the final part of a three-part series where we show how to build a data lake on AWS using a modern dataarchitecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content