This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data lakes and datawarehouses are two of the most important data storage and management technologies in a modern dataarchitecture. Data lakes store all of an organization’s data, regardless of its format or structure. Delta Lake doesn’t have a specific concept for incremental queries.
In todays data-driven world, securely accessing, visualizing, and analyzing data is essential for making informed business decisions. For instance, a global sports gear company selling products across multiple regions needs to visualize its sales data, which includes country-level details.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. And move with confidence and trust with built-in governance to address enterprise security needs.
They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML. Based on business needs and the nature of the data, raw vs structured, organizations should determine whether to set up a datawarehouse, a Lakehouse or consider a data fabric technology.
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. Data architect vs. data engineer The data architect and data engineer roles are closely related.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
In a modern dataarchitecture, unified analytics enable you to access the data you need, whether it’s stored in a data lake or a datawarehouse. Select the Visual with a blank canvas , because we’re authoring a job from scratch, then choose Create.
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
It provides insights and metrics related to the performance and effectiveness of data quality processes. In this post, we highlight the seamless integration of Amazon Athena and Amazon QuickSight , which enables the visualization of operational metrics for AWS Glue Data Quality rule evaluation in an efficient and effective manner.
Investment in datawarehouses is rapidly rising, projected to reach $51.18 billion by 2028 as the technology becomes a vital cog for enterprises seeking to be more data-driven by using advanced analytics. Datawarehouses are, of course, no new concept. More data, more demanding. “As
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
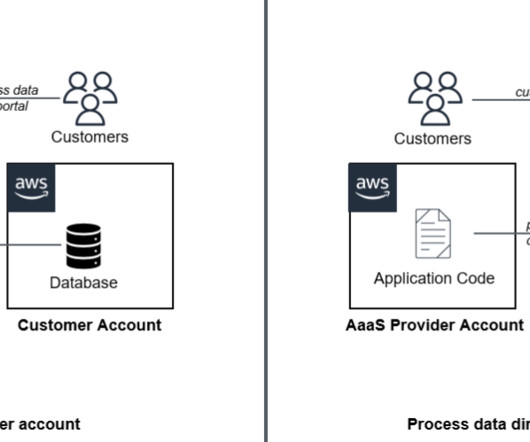
The AaaS model accelerates data-driven decision-making through advanced analytics, enabling organizations to swiftly adapt to changing market trends and make informed strategic choices. times better price-performance than other cloud datawarehouses. Data processing jobs enrich the data in Amazon Redshift.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Amazon SageMaker Unified Studio brings together functionality and tools from the range of standalone studios, query editors, and visual tools available today in Amazon EMR , AWS Glue , Amazon Redshift , Amazon Bedrock , and the existing Amazon SageMaker Studio. AWS Glue 5.0 Finally, AWS Glue 5.0 Additional resources: Introducing AWS Glue 5.0
Managing large-scale datawarehouse systems has been known to be very administrative, costly, and lead to analytic silos. The good news is that Snowflake, the cloud data platform, lowers costs and administrative overhead. agentless) Birst to Snowflake real-time connector. What gaps does the joint solution address in the market?
Amazon Redshift is a fully managed cloud datawarehouse that’s used by tens of thousands of customers for price-performance, scale, and advanced data analytics. This would necessitate the ability to securely share and potentially monetize the company’s data with external partners, such as franchises.
Data scientists derive insights from data while business analysts work closely with and tend to the data needs of business units. Business analysts sometimes perform data science, but usually, they integrate and visualizedata and create reports and dashboards from data supplied by other groups.
During that same time, AWS has been focused on helping customers manage their ever-growing volumes of data with tools like Amazon Redshift , the first fully managed, petabyte-scale cloud datawarehouse. One group performed extract, transform, and load (ETL) operations to take raw data and make it available for analysis.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern dataarchitecture to accelerate the delivery of new solutions. Snowflake can query across Iceberg and Snowflake table formats.
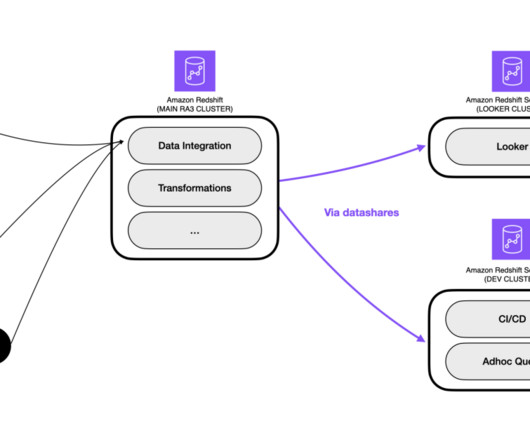
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Organisations are looking at ways of simplifying data; for example, through simple rebranding efforts to disguise the complexity. However, SAP Datasphere goes much deeper deeper than a simple rebranding; it is the next generation of SAP DataWarehouse Cloud. They fail to get a grip on their data.
They’re often responsible for building algorithms for accessing raw data, too, but to do this, they need to understand a company’s or client’s objectives, as aligning data strategies with business goals is important, especially when large and complex datasets and databases are involved.
Data engineers are often responsible for building algorithms for accessing raw data, but to do this, they need to understand a company’s or client’s objectives, as aligning data strategies with business goals is important, especially when large and complex datasets and databases are involved. Data engineer job description.
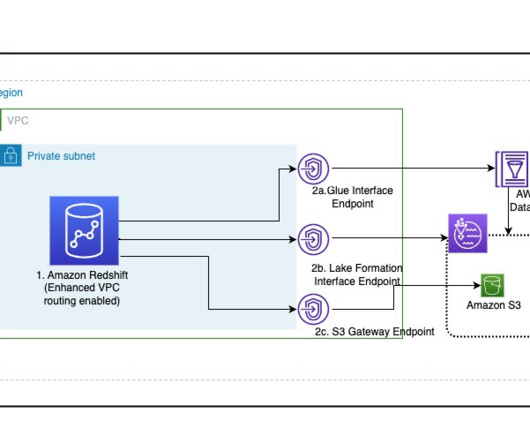
Many customers are extending their datawarehouse capabilities to their data lake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their data lakes based on Amazon Simple Storage Service (Amazon S3).
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and data lakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Remove all data and delete the staging and curated S3 buckets.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. The decoupled compute and storage architecture of Amazon Redshift enables you to build highly scalable, resilient, and cost-effective workloads.
Like all of our customers, Cloudera depends on the Cloudera Data Platform (CDP) to manage our day-to-day analytics and operational insights. Many aspects of our business live within this modern dataarchitecture, providing all Clouderans the ability to ask, and answer, important questions for the business.
Strategize based on how your teams explore data, run analyses, wrangle data for downstream requirements, and visualizedata at different levels. The AWS modern dataarchitecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud.
Through modern dataarchitectures powered by CDP, including Cloudera-enabled data fabric, data lakehouse, and data mesh , DoD agencies can rapidly provision and manage innovative data engineering, datawarehouse, and machine learning environments, with access to secured supply chain data stored in CDP Private Cloud.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and data lakes can become equally challenging.
Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines. If storing operational data in a datawarehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported.
Data fabric and data mesh are emerging data management concepts that are meant to address the organizational change and complexities of understanding, governing and working with enterprise data in a hybrid multicloud ecosystem. The good news is that both dataarchitecture concepts are complimentary.
They can use their own toolsets or rely on provided blueprints to ingest the data from source systems. Once released, consumers use datasets from different providers for analysis, machine learning (ML) workloads, and visualization. The difference lies in when and where data transformation takes place.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificial intelligence (AI) applications.
Kinesis Data Streams has native integrations with other AWS services such as AWS Glue and Amazon EventBridge to build real-time streaming applications on AWS. Refer to Amazon Kinesis Data Streams integrations for additional details. The raw data can be streamed to Amazon S3 for archiving.
The client opted to adopt Kafka and Flink with Iceberg on Cloudera Private Cloud for streaming analytics scenarios and Cloudera Machine Learning and DataWarehouse on CDP Public Cloud for machine learning model development and datavisualization applications.
Amazon Redshift is a fast, fully managed cloud datawarehouse that makes it straightforward and cost-effective to analyze all your data at petabyte scale, using standard SQL and your existing business intelligence (BI) tools. Their cluster size of the provisioned datawarehouse didn’t change.
The most common big data use case is datawarehouse optimization. Big dataarchitecture is used to augment different applications, operating alongside or in a discrete fashion with a datawarehouse. A big data implementation may even replace a datawarehouse entirely with a data lake.
CDE like the other data services (DataWarehouse and Machine Learning for example) deploys within the same kubernetes cluster and is managed through the same security and governance model. Data Engineering should not be limited by one cloud vendor or data locality. With the introduction of PVC 1.3.0
In working with clients, these are some of the most common “pain points” I routinely address: Difficulty in extracting data out of legacy systems. Limited real-time analytics and visuals. Inability to get data quickly. Data accuracy concerns. More time spent accessing data vs. making data-driven decisions.
DaaS is a core component of modern dataarchitecture. It provides a governed standard for accessing existing data objects and pipelines for sharing new data objects within an organization. Because it hides the underlying complexities of connecting to and preparing data sources, DaaS helps expand usage of available data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content