This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In modern dataarchitectures, Apache Iceberg has emerged as a popular table format for data lakes, offering key features including ACID transactions and concurrent write support. However, commits can still fail if the latest metadata is updated after the base metadata version is established.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern dataarchitectures.
Data quality is no longer a back-office concern. We also examine how centralized, hybrid and decentralized dataarchitectures support scalable, trustworthy ecosystems. Why data quality matters and its impact on business AI and analytics are transforming how businesses operate, compete and grow.
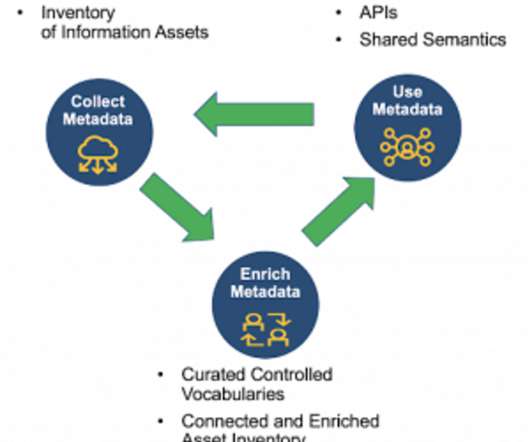
While there has been a lot of talk about big data over the years, the real hero in unlocking the value of enterprise data is metadata , or the data about the data. They don’t know exactly what data they have or even where some of it is. Metadata Is the Heart of Data Intelligence.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Dataarchitecture has evolved significantly to handle growing data volumes and diverse workloads. In later pipeline stages, data is converted to Iceberg, to benefit from its read performance.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. Second-generation – gigantic, complex data lake maintained by a specialized team drowning in technical debt. Introduction to Data Mesh. See the pattern?
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documenting metadata. But in many scenarios, it seems that the underlying driver of metadata collection projects is that it’s just something you do for data governance.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
Reading Time: 3 minutes While cleaning up our archive recently, I found an old article published in 1976 about data dictionary/directory systems (DD/DS). Nowadays, we no longer use the term DD/DS, but “data catalog” or simply “metadata system”. It was written by L.
To improve the way they model and manage risk, institutions must modernize their data management and data governance practices. Implementing a modern dataarchitecture makes it possible for financial institutions to break down legacy data silos, simplifying data management, governance, and integration — and driving down costs.
Manufacturers have long held a data-driven vision for the future of their industry. It’s one where near real-time data flows seamlessly between IT and operational technology (OT) systems. Legacy data management is holding back manufacturing transformation Until now, however, this vision has remained out of reach.
But while state and local governments seek to improve policies, decision making, and the services constituents rely upon, data silos create accessibility and sharing challenges that hinder public sector agencies from transforming their data into a strategic asset and leveraging it for the common good. . Modern dataarchitectures.
And although there is clear momentum behind the data lakehouse as the ideal architecture for multi-function analytics, the demand for open table formats including Apache Iceberg is a clear signal that data leaders value interoperability and engine freedom. It no longer matters where the data is. Open data is the future.
Only a fraction of data created is actually stored and managed, with analysts estimating it to be between 4 – 6 ZB in 2020. Clearly, hybrid data presents a massive opportunity and a tough challenge. Capitalizing on the potential requires the ability to harness the value of all of that data, no matter where it is.
This post describes how HPE Aruba automated their Supply Chain management pipeline, and re-architected and deployed their data solution by adopting a modern dataarchitecture on AWS. Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file.
The AI Forecast: Data and AI in the Cloud Era , sponsored by Cloudera, aims to take an objective look at the impact of AI on business, industry, and the world at large. AI is only as successful as the data behind it. It could be metadata that you weren’t capturing before. But what does that future look like?
For decades, data modeling has been the optimal way to design and deploy new relational databases with high-quality data sources and support application development. Today’s data modeling is not your father’s data modeling software. So here’s why data modeling is so critical to data governance.
Only a fraction of data created is actually stored and managed, with analysts estimating it to be between 4 – 6 ZB in 2020. Clearly, hybrid data presents a massive opportunity and a tough challenge. Capitalizing on the potential requires the ability to harness the value of all of that data, no matter where it is.
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
The main goal of creating an enterprise data fabric is not new. It is the ability to deliver the right data at the right time, in the right shape, and to the right data consumer, irrespective of how and where it is stored. Data fabric is the common “net” that stitches integrated data from multiple data […].
Dataarchitecture is a complex and varied field and different organizations and industries have unique needs when it comes to their data architects. Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and data lakes.
Several factors determine the quality of your enterprise data like accuracy, completeness, consistency, to name a few. But there’s another factor of data quality that doesn’t get the recognition it deserves: your dataarchitecture. How the right dataarchitecture improves data quality.
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documenting metadata. But in many scenarios, it seems that the underlying driver of metadata collection projects is that it’s just something you do for data governance.
AWS Lake Formation helps with enterprise data governance and is important for a data mesh architecture. It works with the AWS Glue Data Catalog to enforce data access and governance. This solution only replicates metadata in the Data Catalog, not the actual underlying data.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
Over the past decade, the successful deployment of large scale data platforms at our customers has acted as a big data flywheel driving demand to bring in even more data, apply more sophisticated analytics, and on-board many new data practitioners from business analysts to data scientists. Key Design Goals .
Aptly named, metadata management is the process in which BI and Analytics teams manage metadata, which is the data that describes other data. In other words, data is the context and metadata is the content. Without metadata, BI teams are unable to understand the data’s full story.
Data governance definition Data governance is a system for defining who within an organization has authority and control over data assets and how those data assets may be used. It encompasses the people, processes, and technologies required to manage and protect data assets.
In light of recent, high-profile data breaches, it’s past-time we re-examined strategic data governance and its role in managing regulatory requirements. for alleged violations of the European Union’s General Data Protection Regulation (GDPR). Complexity. Five Steps to GDPR/CCPA Compliance. Govern PII “in motion”.
I’m convinced that a fundamental shift in approach to lineage is needed to drive both the value of data (and the analytics culture) to a new level of effectiveness. What Is Data Lineage Creation & Maintenance? But what data things are interconnected? Simply put, I find it fascinating! Why Focus on Lineage? Look familiar?
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern dataarchitecture to accelerate the delivery of new solutions.
A modern data strategy redefines and enables sharing data across the enterprise and allows for both reading and writing of a singular instance of the data using an open table format. Why Cloudinary chose Apache Iceberg Apache Iceberg is a high-performance table format for huge analytic workloads.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
In the data-driven era, CIO’s need a solid understanding of data governance 2.0 … Data governance (DG) is no longer about just compliance or relegated to the confines of IT. Today, data governance needs to be a ubiquitous part of your organization’s culture. It also requires funding.
They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views.
Amazon SageMaker Lakehouse provides an open dataarchitecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift data warehouses, and third-party and federated data sources. With AWS Glue 5.0, AWS Glue 5.0 AWS Glue 5.0 Apache Iceberg 1.6.1,
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. You’ll get a single unified view of all your data for your data and AI workers, regardless of where the data sits, breaking down your data siloes.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. The final step is designing a data solution and its implementation. The biggest challenge is broken data pipelines due to highly manual processes. List of Challenges. Definition of Done.
Over the years, data lakes on Amazon Simple Storage Service (Amazon S3) have become the default repository for enterprise data and are a common choice for a large set of users who query data for a variety of analytics and machine leaning use cases. Analytics use cases on data lakes are always evolving.
Data democratization, much like the term digital transformation five years ago, has become a popular buzzword throughout organizations, from IT departments to the C-suite. It’s often described as a way to simply increase data access, but the transition is about far more than that.
Replace manual and recurring tasks for fast, reliable data lineage and overall data governance. It’s paramount that organizations understand the benefits of automating end-to-end data lineage. The importance of end-to-end data lineage is widely understood and ignoring it is risky business. Doing Data Lineage Right.
The role of data modeling (DM) has expanded to support enterprise data management, including data governance and intelligence efforts. Metadata management is the key to managing and governing your data and drawing intelligence from it. Types of Data Models: Conceptual, Logical and Physical.
Within the context of a data mesh architecture, I will present industry settings / use cases where the particular architecture is relevant and highlight the business value that it delivers against business and technology areas. Introduction to the Data Mesh Architecture and its Required Capabilities.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content