This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
While it’s always been the best way to understand complex data sources and automate design standards and integrity rules, the role of data modeling continues to expand as the fulcrum of collaboration between data generators, stewards and consumers. So here’s why data modeling is so critical to data governance.
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. Data architect vs. data engineer The data architect and data engineer roles are closely related.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern dataarchitecture to accelerate the delivery of new solutions.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. Having confidence in your data is key.
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
Amazon SageMaker Unified Studio brings together functionality and tools from the range of standalone studios, query editors, and visual tools available today in Amazon EMR , AWS Glue , Amazon Redshift , Amazon Bedrock , and the existing Amazon SageMaker Studio. With AWS Glue 5.0,
The complex challenge here is to have the lineage be intelligently updated as the data landscape and processing dynamically bubbles and changes daily across an enterprise. Active metadata will play a critical role in automating such updates as they arise. This approach ensures lineage is easy to visualize. Why Focus on Lineage?
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
The program must introduce and support standardization of enterprise data. Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata.
Metadata management is the key to managing and governing your data and drawing intelligence from it. Beyond harvesting and cataloging metadata , it also must be visualized to break down the complexity of how data is organized and what data relationships there are so that meaning is explicit to all stakeholders in the data value chain.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly. The solution integrates data in three tiers.
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a data lake, transformed, and made available for analytics, machine learning (ML), and visualization. The target accounts read data from the source account S3 buckets.
AWS Glue Data Catalog stores information as metadata tables, where each table specifies a single data store. The AWS Glue crawler writes metadata to the Data Catalog by classifying the data to determine the format, schema, and associated properties of the data. Disable the scheduled AWS Glue job run.
In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse. 1: Multi-function analytics . 2: Open formats. 3: Open Performance.
SAP helps to solve this search problem by offering ways to simplify business data with a solid data foundation that powers SAP Datasphere. It fits neatly with the renewed interest in dataarchitecture, particularly data fabric architecture. They fail to get a grip on their data.
Data fabric and data mesh are emerging data management concepts that are meant to address the organizational change and complexities of understanding, governing and working with enterprise data in a hybrid multicloud ecosystem. The good news is that both dataarchitecture concepts are complimentary.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and data lakes can become equally challenging.
It seamlessly consolidates data from various data sources within AWS, including AWS Cost Explorer (and forecasting with Cost Explorer ), AWS Trusted Advisor , and AWS Compute Optimizer. They can use their own toolsets or rely on provided blueprints to ingest the data from source systems.
Here are some scenarios in which companies found real benefits from automated data lineage solutions: Data Lineage Enables Complex Data Processing Operations. By adopting automated data lineage and automated metadata tagging, companies have the opportunity to increase their data processing speed.
In the first part of this post, we walk through the integration between AWS Glue Data Quality and Amazon DataZone. We discuss how to visualizedata quality scores in Amazon DataZone, enable AWS Glue Data Quality when creating a new Amazon DataZone data source, and enable data quality for an existing data asset.
Profile aggregation – When you’ve uniquely identified a customer, you can build applications in Managed Service for Apache Flink to consolidate all their metadata, from name to interaction history. Then, you transform this data into a concise format. Data exploration Data exploration helps unearth inconsistencies, outliers, or errors.
ATPCO is the industry leader in providing pricing and merchandising content for airlines, global distribution systems (GDSs), online travel agencies (OTAs), and other sales channels for consumers to visually understand differences between various offers. Consume data assets as part of analyzing data to generate insights.
Amazon Q Generative SQL capability Query Editor, an out-of-the-box web-based SQL experience in Amazon Redshift is a popular tool for data exploration, visual analysis, and data collaboration. Here’s a couple of highlights from this week and for the full list, see below.
Kinesis Data Streams has native integrations with other AWS services such as AWS Glue and Amazon EventBridge to build real-time streaming applications on AWS. Refer to Amazon Kinesis Data Streams integrations for additional details. The raw data can be streamed to Amazon S3 for archiving.
Having an accurate and up-to-date inventory of all technical assets helps an organization ensure it can keep track of all its resources with metadata information such as their assigned oners, last updated date, used by whom, how frequently and more. This is a guest blog post co-written with Corey Johnson from Huron.
While there are many factors that led to this event, one critical dynamic was the inadequacy of the dataarchitectures supporting banks and their risk management systems. It required banks to maintain dataarchitecture supporting risk aggregation at all times. Automated Data Lineage Tools Provide Regulatory Solutions.
Overview of solution As a data-driven company, smava relies on the AWS Cloud to power their analytics use cases. smava ingests data from various external and internal data sources into a landing stage on the data lake based on Amazon Simple Storage Service (Amazon S3). This is the Data Mart stage.
Priority 2 logs, such as operating system security logs, firewall, identity provider (IdP), email metadata, and AWS CloudTrail , are ingested into Amazon OpenSearch Service to enable the following capabilities. Develop log and trace analytics solutions with interactive queries and visualize results with high adaptability and speed.
In today’s AI/ML-driven world of data analytics, explainability needs a repository just as much as those doing the explaining need access to metadata, EG, information about the data being used. The Cloud Data Migration Challenge. A useful feature for exposing patterns in the data. Visual Profiling.
As part of this step, you use AWS Glue Data Quality to compare data between PostgreSQL and Amazon S3 to confirm the data is valid. Complete the following steps to create an AWS Glue job using the AWS Glue visual editor to compare data between PostgreSQL and Amazon S3: Set the source as the PostgreSQL table sample_data.
While the essence of success in data governance is people and not technology, having the right tools at your fingertips is crucial. Technology is an enabler, and for data governance this is essentially having an excellent metadata management tool. Next to data governance, dataarchitecture is really embedded in our DNA.
We foresee organizations pivoting focus beyond the algorithm to things like business-ready predictive dashboards, visualizations, and applications that simplify the use of AI systems to reach conclusions. These features provide businesses with a common metadata, security, and governance model across all their data.
Geocoding Geocoding is the process of adding location metadata to an organization’s datasets. By tagging data with geographical coordinates to track where it originated from, where it has been and where it resides, an organization can ensure national and global geographic data standards are being met.
Streaming jobs constantly ingest new data to synchronize across systems and can perform enrichment, transformations, joins, and aggregations across windows of time more efficiently. OpenSearch Service offers visualization capabilities powered by OpenSearch Dashboards and Kibana (1.5
With fast and fine-grained scaling in EMR Serverless, if a pipeline runs daily and needs to process 1 GB of data one day and 100 GB of data another day, EMR Serverless automatically scales to handle that load. Monjumi Sarma is a Data Lab Solutions Architect at AWS.
With so much valuable data potentially available, it can be frustrating for organizations to discover that they can’t easily work with it because it’s stuck in disconnected silos. Limited data access is a problem when organizations need timely, complete views.
GraphDB’s Visual Graph can be used to explore the data as demonstrated below. As this type of data is very dynamic, the flexibility of knowledge graphs and their capacity to seamlessly integrate data from disparate sources provides researchers with valuable live insights into the COVID-19 pandemic and its consequences.
This is in contrast to traditional BI, which extracts insight from data outside of the app. We rely on increasingly mobile technology to comb through massive amounts of data and solve high-value problems. Plus, there is an expectation that tools be visually appealing to boot. Their dashboards were visually stunning.
AWS Glue also supports the ability to apply complex data transformations, enabling efficient data integration and preparation to meet your needs. Schema and other metadata will be registered in the AWS Glue Data Catalog, a centralized metadata repository for all your data assets.
While enabling organization-wide efficiency, the team also applied these principles to the dataarchitecture, making sure that CLEA itself operates frugally. After evaluating various tools, we built a serverless data transformation pipeline using Amazon Athena and dbt. However, our initial dataarchitecture led to challenges.
Create a federated connection for Amazon Redshift Complete the following steps to create a federated catalog in the Data Catalog to query the data using various preferred analytics tools such as Athena, visual ETL in SageMaker Unified Studio, Amazon EMR, and more: On the SageMaker Unified Studio console, choose your project.
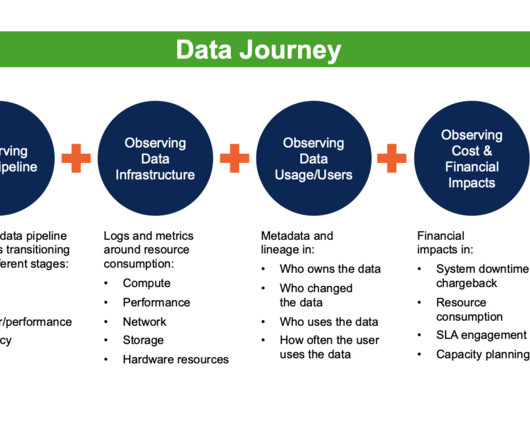
Data Observability leverages five critical technologies to create a data awareness AI engine: data profiling, active metadata analysis, machine learning, data monitoring, and data lineage. Like an apartment blueprint, Data lineage provides a written document that is only marginally useful during a crisis.
To capture a more complete picture of the data’s journey, it is important to have a DataOps Observability system in place. Data lineage is static and often lags by weeks or months. Data lineage is often considered static because it is typically based on snapshots of data and metadata taken at a specific time.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content