This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In modern dataarchitectures, Apache Iceberg has emerged as a popular table format for data lakes, offering key features including ACID transactions and concurrent write support. The Data Catalog provides the functionality as the Iceberg catalog. Determine the changes in transaction, and write new data files.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Dataarchitecture has evolved significantly to handle growing data volumes and diverse workloads. Querying all snapshots, we can see that we created three snapshots with overwrites after the initial one.
Data migration must be performed separately using methods such as S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication. This utility has two modes for replicating Lake Formation and Data Catalog metadata: on-demand and real-time. Nivas Shankar is a Principal Product Manager for AWS Lake Formation.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern dataarchitecture to accelerate the delivery of new solutions. Snowflake can query across Iceberg and Snowflake table formats.
Over the past decade, the successful deployment of large scale data platforms at our customers has acted as a big data flywheel driving demand to bring in even more data, apply more sophisticated analytics, and on-board many new data practitioners from business analysts to data scientists.
Solving the small file problem and improving query performance In modern dataarchitectures, stream processing engines such as Amazon EMR are often used to ingest continuous streams of data into data lakes using Apache Iceberg. A metadata or data file is considered orphan if it isn’t reachable by any valid snapshot.
Over the years, data lakes on Amazon Simple Storage Service (Amazon S3) have become the default repository for enterprise data and are a common choice for a large set of users who query data for a variety of analytics and machine leaning use cases. Analytics use cases on data lakes are always evolving.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
With data becoming the driving force behind many industries today, having a modern dataarchitecture is pivotal for organizations to be successful. Expiring old snapshots – This operation provides a way to remove outdated snapshots and their associated data files, enabling Orca to maintain low storage costs.
Additionally, this release of Open Data Lakehouse includes a mix of Apache Ozone capabilities, like quotas, snapshots, and disaster recovery enhancements. Open Data Lakehouse also offers expanded support for Python 3.10 and RHEL 9.1, all of which add another layer of compatibility and flexibility.
Tracking data changes and rollback Build your transactional data lake on AWS You can build your modern dataarchitecture with a scalable data lake that integrates seamlessly with an Amazon Redshift powered cloud warehouse. Additionally, you can query in Athena based on the version ID of a snapshot in Iceberg.
Today it’s used by many innovative technology companies at petabyte scale, allowing them to easily evolve schemas, create snapshots for time travel style queries, and perform row level updates and deletes for ACID compliance. Modernizing pipelines.
The takeaway – businesses need control over all their data in order to achieve AI at scale and digital business transformation. The challenge for AI is how to do data in all its complexity – volume, variety, velocity. We believe the best path is with a hybrid data platform for modern dataarchitectures with data anywhere.
In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse. 1: Multi-function analytics . Financial regulation. Reproducibility for ML Ops.
Combining and analyzing both structured and unstructured data is a whole new challenge to come to grips with, let alone doing so across different infrastructures. Both obstacles can be overcome using modern dataarchitectures, specifically data fabric and data lakehouse. Unified data fabric.
Kinesis Data Streams has native integrations with other AWS services such as AWS Glue and Amazon EventBridge to build real-time streaming applications on AWS. Refer to Amazon Kinesis Data Streams integrations for additional details. State snapshot in Amazon S3 – You can store the state snapshot in Amazon S3 for tracking.
Data lakes and data warehouses are two of the most important data storage and management technologies in a modern dataarchitecture. Data lakes store all of an organization’s data, regardless of its format or structure. The original source file 2022.csv
A modern dataarchitecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale. Clustering data for better data colocation using z-ordering.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern dataarchitecture implementations on the AWS Cloud. Table data storage mode – There are two options: Historical – This table in the data lake stores historical updates to records (always append).
The dataarchitecture diagram below shows an example of how you could use AWS services to calculate and visualize an organization’s estimated carbon footprint. Customers have the flexibility to choose the services in each stage of the data pipeline based on their use case.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative dataarchitectures to address complex business challenges.
He has over 20 years of experience in software engineering, software architecture, and cloud architecture. He has over 25 years of experience in Enterprise dataarchitecture, databases and data warehousing. outputs: - Name: ClusterStatus Selector: '$.Clusters[0].ClusterStatus' Clusters[0].ClusterStatus'
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow. The following figure shows a daily usage KPI.
Furthermore, data events are filtered, enriched, and transformed to a consumable format using a stream processor. The result is made available to the application by querying the latest snapshot. Data streaming enables you to ingest data from a variety of databases across various systems.
This post is designed to be implemented for a real customer use case, where you get full snapshotdata on a daily basis. The dataset represents employee details such as ID, name, address, phone number, contractor or not, and more. You can also maintain the delta table by compacting the small files.
With scheduled flows, you can choose either full or incremental data transfer: With full transfer, Amazon AppFlow transfers a snapshot of all records at the time of the flow run from the source to the destination. He’s on a mission to make life easier for customers who are facing complex data integration challenges.
By analyzing the historical report snapshot, you can identify areas for improvement, implement changes, and measure the effectiveness of those changes. He focuses on modern dataarchitectures and helping customers accelerate their cloud journey with serverless technologies.
What Are the Biggest Drivers of Cloud Data Warehousing? It’s costly and time-consuming to manage on-premises data warehouses — and modern cloud dataarchitectures can deliver business agility and innovation. There are tools to replicate and snapshotdata, plus tools to scale and improve performance.”
Deselect Create final snapshot. He is deeply passionate about DataArchitecture and helps customers build analytics solutions at scale on AWS. She has helped many customers build large-scale data warehouse solutions in the cloud and on premises. Select Delete the associated namespace.
For more information, refer to Creating external tables for data managed in Delta Lake. A Delta table manifest contains a list of files that make up a consistent snapshot of the Delta table. You could use this high-level architecture for any other use cases where you need to use the latest version of Spark on EMR Serverless.
The following maintenance tasks are supported by the framework: Expire snapshotsSnapshots can be used for rollback operations as well as time traveling queries. Its highly recommended to regularly expire snapshots that are no longer needed. Remove old metadata files Metadata files can accumulate over time just like snapshots.
Apache Iceberg, together with the REST Catalog, dramatically simplifies the enterprise dataarchitecture, reducing the Time to Value, Time to Market, and overall TCO, and driving greater ROI. It provides real time metadata access by directly integrating with the Iceberg-compatible metastore.
Icebergs robust metadata layers, including snapshots and manifest files, were seamlessly updated to capture these changes, providing efficient and accurate synchronization between Hive and Iceberg tables. To address this, NI implemented a solution similar to the previous flow but adapted to Icebergs architecture.
It offers built-in monitoring using Amazon CloudWatch metrics , application state backup with managed snapshots , and automatic scaling. He focuses on building scalable, real-time data pipelines that power Riskifieds core products.
Like an apartment blueprint, Data lineage provides a written document that is only marginally useful during a crisis. This is especially true regarding our one-to-many, producer-to-consumer relationships on our dataarchitecture. Are problems with data tests? Which report tab is wrong? When did it last run? Did it fail?
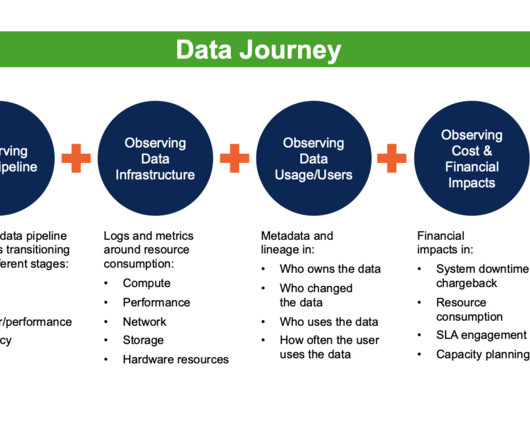
To capture a more complete picture of the data’s journey, it is important to have a DataOps Observability system in place. Data lineage is static and often lags by weeks or months. Data lineage is often considered static because it is typically based on snapshots of data and metadata taken at a specific time.
To demonstrate the complexities that need to be navigated, I thought it would be helpful to present a comparative snapshot of current global issues that should be influencing CIO and CTO priorities across five regions: Europe, the United Kingdom, the United States, the Middle East and Asia.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content