This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Dataarchitecture has evolved significantly to handle growing data volumes and diverse workloads. Data and metadata are shown in blue in the following detail diagram. create_hudi_s3.py
Over the past decade, the successful deployment of large scale data platforms at our customers has acted as a big data flywheel driving demand to bring in even more data, apply more sophisticated analytics, and on-board many new data practitioners from business analysts to data scientists. What’s Next.
Many of the tests to check performance and volumes of data scanned have used Athena because it provides a simple to use, fully serverless, cost effective, interface without the need to setup infrastructure. Expire snapshots Each write to an Iceberg table creates a new snapshot , or version, of a table. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
Over the years, data lakes on Amazon Simple Storage Service (Amazon S3) have become the default repository for enterprise data and are a common choice for a large set of users who query data for a variety of analytics and machine leaning use cases. Analytics use cases on data lakes are always evolving.
Today it’s used by many innovative technology companies at petabyte scale, allowing them to easily evolve schemas, create snapshots for time travel style queries, and perform row level updates and deletes for ACID compliance. Test Drive CDP Pubic Cloud. Modernizing pipelines.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern dataarchitecture implementations on the AWS Cloud. We begin with a Data lake reference architecture followed by an overview of operational data processing framework. This concludes the demo.
Additionally, BPG has not been tested with the Volcano scheduler , and the solution is not applicable in environments using native Amazon EMR on EKS APIs. Test the solution To test the solution, you can submit multiple Spark jobs by running the following sample code multiple times. For example: HTTP/1.1
Test SCD Type 2 implementation With the infrastructure in place, you’re ready to test out the overall solution design and query historical records from the employee dataset. This post is designed to be implemented for a real customer use case, where you get full snapshotdata on a daily basis.
A modern dataarchitecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale. Clustering data for better data colocation using z-ordering.
By analyzing the historical report snapshot, you can identify areas for improvement, implement changes, and measure the effectiveness of those changes. In our example, we have configured a ruleset against a table containing patient data within a healthcare synthetic dataset generated using Synthea.
Choose Test connection to verify that AWS SCT can connect to your source Azure Synapse project. Choose Test connection to verify that AWS SCT can connect to your target Redshift workgroup. When the test is successful, choose OK. Select Use SSL to encrypt AWS SCT connection to Data Extraction Agent. Choose Test connection.
Developers need to understand the application APIs, write implementation and test code, and maintain the code for future API changes. Test the solution Log in to your Salesforce account, and edit any record in the Account object. He’s on a mission to make life easier for customers who are facing complex data integration challenges.
Apache Iceberg, together with the REST Catalog, dramatically simplifies the enterprise dataarchitecture, reducing the Time to Value, Time to Market, and overall TCO, and driving greater ROI. This shows that the REST Catalog will automatically handle any metadata pointer changes, guaranteeing that you will get the most recent data.
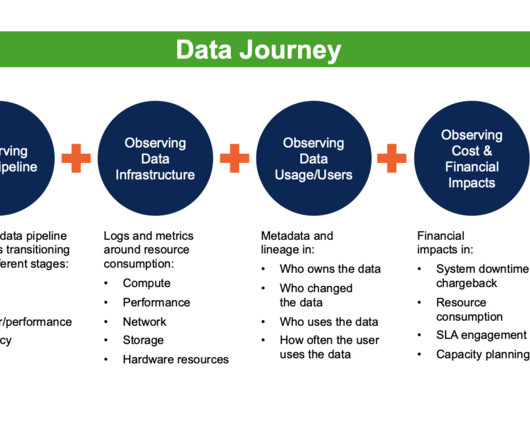
DataOps Observability includes monitoring and testing the data pipeline, data quality, datatesting, and alerting. Datatesting is an essential aspect of DataOps Observability; it helps to ensure that data is accurate, complete, and consistent with its specifications, documentation, and end-user requirements.
Like an apartment blueprint, Data lineage provides a written document that is only marginally useful during a crisis. This is especially true regarding our one-to-many, producer-to-consumer relationships on our dataarchitecture. Are problems with datatests? Data Lineage is static analysis for data systems.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content