This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics.
In June of 2020, CRN featured DataKitchen’s DataOps Platform for its ability to manage the data pipeline end-to-end combining concepts from Agile development, DevOps, and statistical process control: DataKitchen. DBTA Big Data Quarterly’s Big Data 50—Companies Driving Innovation in 2020.
Dataarchitecture is a complex and varied field and different organizations and industries have unique needs when it comes to their data architects. Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and data lakes.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority. It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ?
Data is commonly referred to as the new oil, a resource so immensely powerful that its true potential is yet to be discovered. We haven’t achieved enough with data research and other statistical modeling techniques to be able to see data for what it truly is and even our methods of accruing data are rudimentary […].
When it comes to marketing, business owners need to be fast in adjusting their strategies to fit the continuous advancement in technologies. Today, nearly everyone has a mobile phone or another smart mobile device with them at all times. As the trend of doing everything over a mobile device grows, including tasks such as shopping […].
Mark Twain famously remarked that there are three kinds of lies: lies, damned lies, and statistics. Remember Twain’s quip about statistics and lies. There’s always the possibility that the collected data is itself flawed in some way. Data can be flawed in many ways. Today, many CIOs feel the same way about metrics.
Amazon SageMaker Lakehouse provides an open dataarchitecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift data warehouses, and third-party and federated data sources.
Data engineers and data scientists often work closely together but serve very different functions. Data engineers are responsible for developing, testing, and maintaining data pipelines and dataarchitectures. Data engineer vs. data architect.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. Historic Balance – compares current data to previous or expected values. Statistical Process Control – applies statistical methods to control a process.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern dataarchitecture to accelerate the delivery of new solutions. Andries has over 20 years of experience in the field of data and analytics.
Data scientists usually build models for data-driven decisions asking challenging questions that only complex calculations can try to answer and creating new solutions where necessary. Programming and statistics are two fundamental technical skills for data analysts, as well as data wrangling and data visualization.
Data engineers typically handle large amounts of data and lay the groundwork for data scientists to do their jobs effectively. They are responsible for managing database systems, scaling dataarchitecture to multiple servers, and writing complex queries to sift through the data. The Data Science Process.
DataArchitecture – Definition (2). Data Catalogue. Data Community. Data Domain (contributor: Taru Väre ). Data Enrichment. Data Federation. Data Function. Data Model. Data Operating Model. Master Data – additional definition (contributor: Scott Taylor ).
The world now runs on Big Data. Defined as information sets too large for traditional statistical analysis, Big Data represents a host of insights businesses can apply towards better practices. But what exactly are the opportunities present in big data? In manufacturing, this means opportunity.
Though you may encounter the terms “data science” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
The initial stage involved establishing the dataarchitecture, which provided the ability to handle the data more effectively and systematically. “We Working with non-typical data presents us with a reality where encountering challenges is part of our daily operations.”
There are many statistics that link business success to application speed and responsiveness. Keeping it at acceptable levels requires an underlying dataarchitecture that can handle the demands of globally deployed real-time applications. By Aaron Ploetz, Developer Advocate.
A modern dataarchitecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale. Frequent compaction can be used to optimize read performance.
The existence of a central data catalog enabled teams to seamlessly search, discover, share, and subscribe to data assets produced within the business. Oghosa Omorisiagbon is a Senior Data Engineer at HEMA. Outside of work, he enjoys traveling, playing video games and outdoor activities.
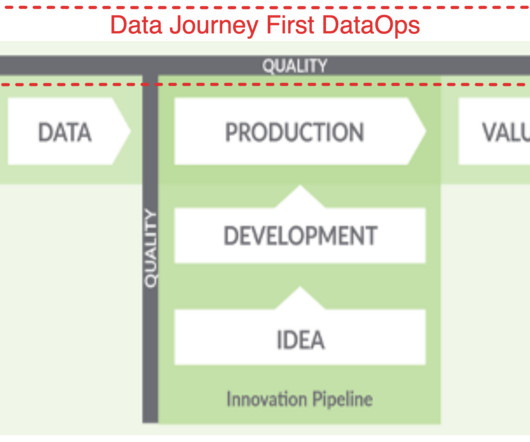
Data Journey First DataOps Putting Problems in Your Data Estate at the Forefront Welcome to the high-octane world of DataOps, a powerhouse that turbocharges data analytics development and management. Historically, automation has taken center stage in the theater of DataOps.
The consumption of the data should be supported through an elastic delivery layer that aligns with demand, but also provides the flexibility to present the data in a physical format that aligns with the analytic application, ranging from the more traditional data warehouse view to a graph view in support of relationship analysis.
Big data: Architecture and Patterns. The Big data problem can be comprehended properly using a layered architecture. Big dataarchitecture consists of different layers and each layer performs a specific function. The architecture of Big data has 6 layers. Artificial Intelligence.
The CIO delights in detailing the work of Re/Max’s technology team, which is building the pipelines and cloud-native applications to deliver agents in the field the most refined and insightful data from more than 500 MLS listing serivces in the US and Canada as quickly as possible.
Full-stack observability is a critical requirement for effective modern data platforms to deliver the agile, flexible, and cost-effective environment organizations are looking for. RI is a global leader in the design and deployment of large-scale, production-level modern data platforms for the world’s largest enterprises.
Use one click to access your data lake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience. Learn more about the zero-ETL integrations, data lake performance enhancements, and other announcements below.
The flashpoint moment is that rather than being based on rules, statistics, and thresholds, now these systems are being imbued with the power of deep learning and deep reinforcement learning brought about by neural networks,” Mattmann says. The systems are fed the data, and trained, and then improve over time on their own.”
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
Amazon Redshift supports Apache Iceberg’s native schema and partition evolution capabilities using the AWS Glue Data Catalog , eliminating the need to alter table definitions to add new partitions or to move and process large amounts of data to change the schema of an existing data lake table.
These are as follows: General Data Articles. Data Visualisation. Statistics & Data Science. Analytics & Big Data. Data Visualisation. Statistics & Data Science. Data Science Challenges – It’s Deja Vu all over again! CDO perspectives. Programme Advice. Maths & Science.
Here are a few statistics that support this belief: — IoT already has generated more than $123 billion […]. The current decade will see the most rapid technological advancements in history: emergence of new technology and faster development of existing technology.
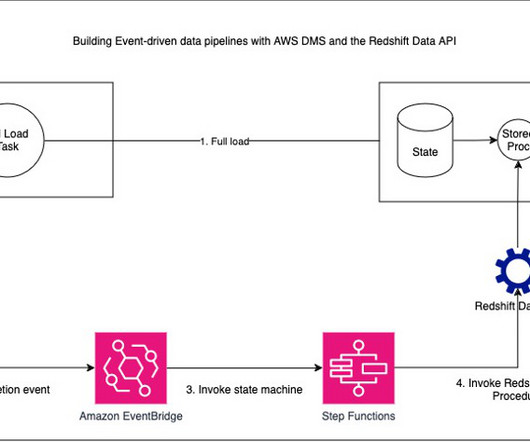
This workflow moves the full volume data from the source database to the Redshift cluster. The following screenshot shows the load statistics for the customer table full load. He has worked with building databases and data warehouse solutions for over 15 years.
Based on the statistics of individual and aggregated application runs per queue and per user, you can determine the existing workload distribution by user. He also understands how to apply technologies to solve big data problems and build a well-designed dataarchitecture. You can find peak and off-peak hours in a day.
Modeling Your Data for Performance. Dataarchitecture. The data landscape has changed significantly over the last two decades. The volume of data being created has increased, and the storage and computational resources needed to store and analyze that data has become cheaper and more widely available.
The purpose of this step is to understand our data quality statistics at the table level as well as at the ruleset level. Use the queries in this section to analyze your data quality metrics and create an Athena view to use to build a QuickSight dashboard in the next step.
You can monitor the tables ingested on the Statistics tab of the replication task. Open the raw layer of the data lake to find a new file holding the incremental changes inside every table’s prefix, for example under the sporting_event prefix. Narendra Merla is a Data Architect in the Amazon Web Services (AWS) Data Lab.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern dataarchitecture implementations on the AWS Cloud. In the Table statistics section, you will see an output similar to the following screenshot.
In the 2010s, the growing scope of the data landscape gave rise to a new profession: the data scientist. This new role, combined with the creation of data lakes and the increasing use of cloud services, created new employment opportunities in data analytics, dataarchitecture, and data management.
For now, I will explore the two fundamental approaches to data lineage creation and maintenance. I’ve adopted the statistics related terminology of deterministic and non-deterministic to help define and explain each. Of course, the other big change is the complexity of the modern application and dataarchitecture.
We expect statistically equal distribution of jobs between the two clusters. Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. contains(GroupName, 'eks-cluster-sg-bpg-cluster-')].GroupId"
In our case, we are appending _custom to the statistic name, resulting in the following format for KPIs: Completeness_custom Uniqueness_custom In a real-world scenario, you might want to set a value that matches with your data quality framework in relation to the KPIs that you want to track in Amazon DataZone.
AWS SCT highlights these objects in blue in the conversion statistics diagram and creates action items with a complexity attached to them. He is deeply passionate about DataArchitecture and helps customers build analytics solutions at scale on AWS.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content