This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here, industrial knowledge graphs are going to prove vital by enabling manufacturers to combine structured and unstructured data from a wide range of operational and enterprise software systems to drive better decision-making, problem-solving and more advanced automation.”
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. He specializes in migrating enterprise data warehouses to AWS Modern DataArchitecture. He contributed to query processing and materialized views.
To attain that level of data quality, a majority of business and IT leaders have opted to take a hybrid approach to data management, moving data between cloud, on-premises -or a combination of the two – to where they can best use it for analytics or feeding AI models. What do we mean by ‘true’ hybrid? Let’s dive deeper.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Dataarchitecture has evolved significantly to handle growing data volumes and diverse workloads.
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
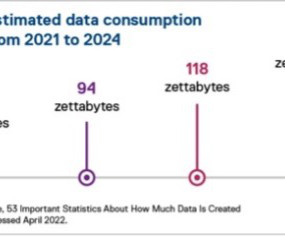
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Newer data lakes are highly scalable and can ingest structured and semi-structureddata along with unstructured data like text, images, video, and audio.
A Few Cautions LLM references a huge amount of data to become truly functional, making it a quite expensive and time consuming effort to train the model. Supercomputers (and other components of infrastructure) along with new approaches to dataarchitecture (with billions of parameters) are needed.
She decided to bring Resultant in to assist, starting with the firm’s strategic data assessment (SDA) framework, which evaluates a client’s data challenges in terms of people and processes, data models and structures, dataarchitecture and platforms, visual analytics and reporting, and advanced analytics.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
The other 10% represents the effort of initial deployment, data-loading, configuration and the setup of administrative tasks and analysis that is specific to the customer, the Henschen said. Features focus on media and entertainment firms.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. He specializes in migrating enterprise data warehouses to AWS Modern DataArchitecture.
Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc. The gigantic evolution of structured, unstructured, and semi-structureddata is referred to as Big data.
A framework for managing data 10 master data management certifications that will pay off Big Data, Data and Information Security, Data Integration, Data Management, Data Mining, Data Science, IT Governance, IT Governance Frameworks, Master Data Management
First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making. Unified data fabric.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structureddata.
It is the only solution that can automatically harvest, transform and feed metadata from operational processes, business applications and data models into a central data catalog and then made accessible and understandable within the context of role-based views.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Solution overview Amazon Redshift is an industry-leading cloud data warehouse.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structureddata) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
It won’t protect you from issues of data quality or from service failures. […] But Linked Data does provide you with new ways to manage these existing data-management challenges. 6 Linked Data, StructuredData on the Web. Linked Data and Information Retrieval.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structuredata for use, train machine learning models and develop artificial intelligence (AI) applications.
Snowflake’s cloud-built data warehouse enables the data-driven enterprise with instant elasticity, secure data sharing, and per-second pricing across multiple clouds. With Snowflake, you can store, transform and analyze structured and semi-structureddata together.
Overview of solution As a data-driven company, smava relies on the AWS Cloud to power their analytics use cases. smava ingests data from various external and internal data sources into a landing stage on the data lake based on Amazon Simple Storage Service (Amazon S3).
In today’s world of complex dataarchitectures and emerging technologies, databases can sometimes be undervalued and unrecognized. Take control of your data governance, security and compliance with Db2’s comprehensive, built-in auditing, access control, and data visibility capabilities.
To that end, IBM is building a set of domain-specific foundation models that go beyond natural language learning models and are trained on multiple types of business data, including code, time-series data, tabular data, geospatial data, semi-structureddata, and mixed-modality data such as text combined with images.
It won’t protect you from issues of data quality or from service failures. […] But Linked Data does provide you with new ways to manage these existing data-management challenges. 6 Linked Data, StructuredData on the Web. Linked Data and Information Retrieval.
The SPARQL query is a way to search, access and retrieve structureddata by pulling together information from diverse data sources. The SPARQL query language, designed and endorsed by the W3C, is the standard for querying data, stored in RDF or mapped to RDF.
Examples of such continuous improvement are technological giants like Google and Amazon who use semantic technology principles to build better dataarchitectures for better user experiences. Such an approach, no matter what name we use for it, is all about improving the way enterprises operate in an interconnected world.
Before data records land on Amazon S3, we implement an ingestion layer to bring all data streams reliably and securely to the data lake. Kinesis Data Streams is deployed as an ingestion layer for accelerated intake of structured and semi-structureddata streams.
Data ingestion, whether real time or batch, forms the basis of any effective data analysis, enabling organizations to gather information from diverse sources and use it for insightful decision-making. It’s raw, unprocessed data straight from the source.
They classified the metrics and indicators in the following categories: Data usage – A clear understanding of who is consuming what data source, materialized with a mapping of consumers and producers. For other organizations, the desired data mesh might look different and the approach might have other learnings.
Business leaders need to quickly access data—and to trust the accuracy of that data—to make better decisions. As organizations grow and evolve, many find a need for more sophisticated analytics across an ever-increasing amount of digital and consumer data. Unreliable Data as a Service (DaaS) implementations.
Amazon SageMaker Lakehouse provides an open dataarchitecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift data warehouses, and third-party and federated data sources.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Key considerations Gameskraft embraces a modern dataarchitecture, with the data lake residing in Amazon S3.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structureddata from open format files in Amazon S3 data lake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your data lake, enabling you to run analytical queries.
Different departments within an organization can place data in a data lake or within their data warehouse depending on the type of data and usage patterns of that department. Nasdaq’s massive data growth meant they needed to evolve their dataarchitecture to keep up.
This will allow enterprises to derive insights from their disparate databases, integrate external knowledge for better interpretation of their data, and incorporate information extracted from unstructured content. In order to integrate structureddata, enterprises need to implement the data fabric pattern.
The SPARQL query is a way to search, access and retrieve structureddata by pulling together information from diverse data sources. The SPARQL query language, designed and endorsed by the W3C, is the standard for querying data, stored in RDF or mapped to RDF.
Examples of such continuous improvement are technological giants like Google and Amazon who use semantic technology principles to build better dataarchitectures for better user experiences. Such an approach, no matter what name we use for it, is all about improving the way enterprises operate in an interconnected world.
Both engines provide native ingestion support from Kinesis Data Streams and Amazon MSK via a separate streaming pipeline to a data lake or data warehouse for analysis. Data streaming enables you to ingest data from a variety of databases across various systems.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, Data Lake emerged, which handles unstructured and structureddata with huge volume. Metadata plays a key role here in discovering the data assets.
Strategize based on how your teams explore data, run analyses, wrangle data for downstream requirements, and visualize data at different levels. The AWS modern dataarchitecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud.
Conclusion In this post, we demonstrated how to identify the changed data for a semi-structureddata source and preserve the historical changes (SCD Type 2) on an S3 Delta Lake, when source systems are unable to provide the change data capture capability, with AWS Glue.
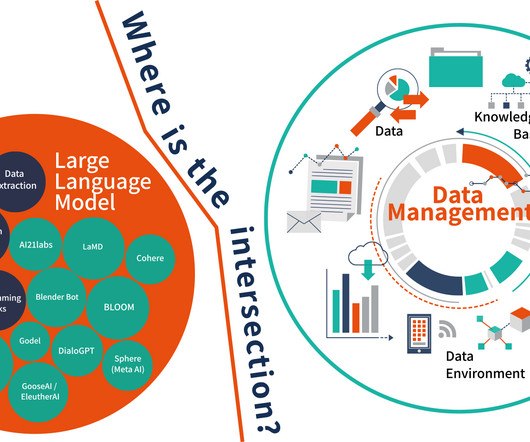
In order to move AI forward, we need to first build and fortify the foundational layer: dataarchitecture. This architecture is important because, to reap the full benefits of AI, it must be built to scale across an enterprise versus individual AI applications. Constructing the right dataarchitecture cannot be bypassed.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content