This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with dataquality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor dataquality is holding back enterprise AI projects.
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and datacollected incorrectly, more of which we’ll address below. Datacollected for one purpose can have limited use for other questions.
We live in a data-rich, insights-rich, and content-rich world. Datacollections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and datascience. Datasphere is not just for data managers.
An education in datascience can help you land a job as a data analyst , data engineer , data architect , or data scientist. Here are the top 15 datascience boot camps to help you launch a career in datascience, according to reviews and datacollected from Switchup.
As model building become easier, the problem of high-qualitydata becomes more evident than ever. Even with advances in building robust models, the reality is that noisy data and incomplete data remain the biggest hurdles to effective end-to-end solutions. Data integration and cleaning.
By contrast, AI adopters are about one-third more likely to cite problems with missing or inconsistent data. The logic in this case partakes of garbage-in, garbage out : data scientists and ML engineers need qualitydata to train their models. This is consistent with the results of our dataquality survey.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in datascience and for managing data infrastructure.
As a direct result, less IT support is required to produce reports, trends, visualizations, and insights that facilitate the data decision making process. From these developments, datascience was born (or at least, it evolved in a huge way) – a discipline where hacking skills and statistics meet niche expertise.
Since the market for big data is expected to reach $243 billion by 2027 , savvy business owners will need to find ways to invest in big data. Artificial intelligence is rapidly changing the process for collecting big data, especially via online media. The Growth of AI in Web DataCollection.
What is a data engineer? Data engineers design, build, and optimize systems for datacollection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. Data engineer vs. data architect.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. Informatica Axon Informatica Axon is a collection hub and data marketplace for supporting programs.
Data observability becomes business-critical Data observability extends the concept of dataquality by closely monitoring data as it flows in and out of the applications. CIOs should first understand the different approaches to observing data and how it differs from quality management,” he notes.
While the word “data” has been common since the 1940s, managing data’s growth, current use, and regulation is a relatively new frontier. . Governments and enterprises are working hard today to figure out the structures and regulations needed around datacollection and use. Infrastructure.
“By recognizing milestones, leaders give other stakeholders visibility into the progress being made, and also ensure that their team members feel appreciated for the level of effort they are putting in to make unstructured data actionable.” Quality is job one. Another key to success is to prioritize dataquality.
Over the past 5 years, big data and BI became more than just datascience buzzwords. Without real-time insight into their data, businesses remain reactive, miss strategic growth opportunities, lose their competitive edge, fail to take advantage of cost savings options, don’t ensure customer satisfaction… the list goes on.
As Dan Jeavons DataScience Manager at Shell stated: “what we try to do is to think about minimal viable products that are going to have a significant business impact immediately and use that to inform the KPIs that really matter to the business”.
For state and local agencies, data silos create compounding problems: Inaccessible or hard-to-access data creates barriers to data-driven decision making. Legacy data sharing involves proliferating copies of data, creating data management, and security challenges. Towards DataScience ).
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data. This is aligned to the five pillars we discuss in this post.
“Because AVs collectdata in public where there is little ‘reasonable expectation of privacy’, they are not subject to many of the privacy laws in the U.S. The datacollected by AVs in the U.S. will likely be owned by the collector of the data, not the data subject. and abroad,” she explained. Advertising?
Finally, refine and aggregate the clean data into insights that directly support key insurance functions like underwriting, risk analysis and regulatory reporting. Step 3: Data governance Maintain dataquality. Enforce strict rules (schemas) to ensure all incoming data fits the expected format. Ensure reliability.
How Business Benefits from Data Intelligence. Traditional business models and processes can be detrimental to today’s evolving data-driven society. Businesses are then introduced to modern datascience and data intelligence tools to enhance and fine-tune their products and processes. Dataquality management.
Programming and statistics are two fundamental technical skills for data analysts, as well as data wrangling and data visualization. Data analysts in one organization might be called data scientists or statisticians in another.
Data cleansing is the process of identifying and correcting errors, inconsistencies, and inaccuracies in a dataset to ensure its quality, accuracy, and reliability. This process is crucial for businesses that rely on data-driven decision-making, as poor dataquality can lead to costly mistakes and inefficiencies.
They have the foundations of data infrastructure. I didn’t mention in this talk, but there’s a great diagram from Monica Rogati, the DataScience Pyramid of Needs, with a lot of foundational infrastructure and logging, feature extraction, all those things that you need to do to make these models work.
Folks can work faster, and with more agility, unearthing insights from their data instantly to stay competitive. Yet the explosion of datacollection and volume presents new challenges. Build a roadmap for future data and analytics projects, like cloud computing. Evaluate and monitor dataquality.
The firms that get data governance and management “right” bring people together and leverage a set of capabilities: (1) Agile; (2) Six sigma; (3) datascience; and (4) project management tools. Some data seems more analytical, while other is operational (external facing). Establishing a solid vision and mission is key.
Paco Nathan covers recent research on data infrastructure as well as adoption of machine learning and AI in the enterprise. Welcome back to our monthly series about datascience! This month, the theme is not specifically about conference summaries; rather, it’s about a set of follow-up surveys from Strata Data attendees.
My role encompasses being the business driver for the data platform that we are rolling out across the organisation and its success in terms of the data going onto the platform and the curation of that data in a governed state, depending on the consumer requirements. Data democratisation is enabled by the data platform.
Data Analyst Job Description: Major Tasks and Duties Data analysts collaborate with management to prioritize information needs, collect and interpret business-critical data, and report findings. Each language serves distinct purposes, from performance-oriented applications to web development and datascience.
Modern business is built on a foundation of trusted data. Yet high-volume collection makes keeping that foundation sound a challenge, as the amount of datacollected by businesses is greater than ever before. An effective data governance strategy is critical for unlocking the full benefits of this information.
Most data analysts are very familiar with Excel because of its simple operation and powerful datacollection, storage, and analysis. Key features: Excel has basic features such as data calculation which is suitable for simple data analysis. RapidMiner. From RapidMiner. From KNIME. Apache Spark.
This research does not tell you where to do the work; it is meant to provide the questions to ask in order to work out where to target the work, spanning reporting/analytics (classic), advanced analytics and datascience (lab), data management and infrastructure, and D&A governance. We write about data and analytics.
Paco Nathan presented, “DataScience, Past & Future” , at Rev. At Rev’s “ DataScience, Past & Future” , Paco Nathan covered contextual insight into some common impactful themes over the decades that also provided a “lens” help data scientists, researchers, and leaders consider the future.
There’s a substantial literature about ethics, data, and AI, so rather than repeat that discussion, we’ll leave you with a few resources. Ethics and DataScience is a short book that helps developers think through data problems, and includes a checklist that team members should revisit throughout the process.
In Paco Nathan ‘s latest column, he explores the role of curiosity in datascience work as well as Rev 2 , an upcoming summit for datascience leaders. Welcome back to our monthly series about datascience. and dig into details about where science meets rhetoric in datascience.
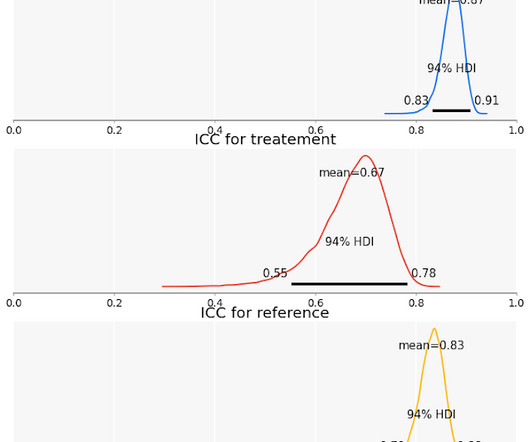
Measurement challenges Assessing reliability is essentially a process of datacollection and analysis. To do this, we collect multiple measurements for each unit of observation, and we determine if these measurements are closely related. In this case, the scale is not measuring the construct that interests us.
Best for : the new intern who has no idea what datascience even means. An excerpt from a rave review : “I would definitely recommend this book to everyone interested in learning about data from scratch and would say it is the finest resource available among all other Big Data Analytics books.”.
Data pipelines are designed to automate the flow of data, enabling efficient and reliable data movement for various purposes, such as data analytics, reporting, or integration with other systems. There are many types of data pipelines, and all of them include extract, transform, load (ETL) to some extent.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content