This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here at Smart DataCollective, we never cease to be amazed about the advances in data analytics. We have been publishing content on data analytics since 2008, but surprising new discoveries in big data are still made every year. You will also want to know how to harvest the data that you get.
As model building become easier, the problem of high-qualitydata becomes more evident than ever. Even with advances in building robust models, the reality is that noisy data and incomplete data remain the biggest hurdles to effective end-to-end solutions. Data integration and cleaning.
You might establish a baseline by replicating collaborative filtering models published by teams that built recommenders for MovieLens, Netflix, and Amazon. It may even be faster to launch this new recommender system, because the Disney data team has access to published research describing what worked for other teams.
The first publisheddata governance framework was the work of Gwen Thomas, who founded the Data Governance Institute (DGI) and put her opus online in 2003. They already had a technical plan in place, and I helped them find the right size and structure of an accompanying data governance program.
This newly published research report addresses this question, covering: Perceptions on planning effectiveness: Find out how supply chain professionals rate the effectiveness of their planning process, who is involved, and what they are doing to improve the planning practice.
Every data professional knows that ensuring dataquality is vital to producing usable query results. Streaming data can be extra challenging in this regard, as it tends to be “dirty,” with new fields that are added without warning and frequent mistakes in the datacollection process.
Domain teams should continually monitor for data errors with data validation checks and incorporate data lineage to track usage. Establish and enforce data governance by ensuring all data used is accurate, complete, and compliant with regulations.
The CompTIA IoT Advisory Council recently published a white paper called The Six Layers of an IoT Solution guide, which breaks down these layers and provides overarching guidance on IoT security to give IT solution practitioners more holistic knowledge of IoT solutions.
What are the metrics that matter? Gartner attempted to list every metric under the sun in their recent report , “T oolkit: Delivery Metrics for DataOps, Self-Service Analytics, ModelOps, and MLOps, ” published February 7, 2023. For example, Gartner’s DataOps metrics can be categorized into Velocity, Efficiency, and Quality.
Data cleansing is the process of identifying and correcting errors, inconsistencies, and inaccuracies in a dataset to ensure its quality, accuracy, and reliability. This process is crucial for businesses that rely on data-driven decision-making, as poor dataquality can lead to costly mistakes and inefficiencies.
Programming and statistics are two fundamental technical skills for data analysts, as well as data wrangling and data visualization. Data analysts in one organization might be called data scientists or statisticians in another. Database design is often an important part of the business analyst role.
Data mesh solves this by promoting data autonomy, allowing users to make decisions about domains without a centralized gatekeeper. It also improves development velocity with better data governance and access with improved dataquality aligned with business needs.
Offer the right tools Data stewardship is greatly simplified when the right tools are on hand. So ask yourself, does your steward have the software to spot issues with dataquality, for example? 2) Always Remember Compliance Source: Unsplash There are now many different data privacy and security laws worldwide.
Lowering the entry cost by re-using data and infrastructure already in place for other projects makes trying many different approaches feasible. Fortunately, learning-based projects typically use datacollected for other purposes. . And the problem is not just a matter of too many copies of data.
I try to relate as much published research as I can in the time available to draft a response. – In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend. – In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend.
This month, the theme is not specifically about conference summaries; rather, it’s about a set of follow-up surveys from Strata Data attendees. We had big surprises at several turns and have subsequently published a series of reports. Evolving Data Infrastructure: Tools and Best Practices for Advanced Analytics and AI (Jan 2019).
Dataquality plays a role into this. And, most of the time, regardless of the size of the size of the company, you only know your code is not working post-launch when data is flowing in (not!). You got me, I am ignoring all the data layer and custom stuff! All that is great.
As a result, concerns of data governance and dataquality were ignored. The direct consequence of bad qualitydata is misinformed decision making based on inaccurate information; the quality of the solutions is driven by the quality of the data. COVID-19 exposes shortcomings in data management.
Amanda said, “There are different points in which we make decisions about how and what we visualize, and then how we publish and share. Amanda went through some of the top considerations, from dataquality, to datacollection, to remembering the people behind the data, to color choices.
In other words, your talk didn’t quite stand out enough to put onstage, but you still get “publish or perish” credits for presenting. These two points provide a different kind of risk management mechanism which is effective for science, specifically data science. Instead they require investment, tooling, and time for datacollection.
One is dataquality, cleaning up data, the lack of labelled data. Frankly, leading data science teams early on, you almost always had to struggle against the BI teams. It was also the year, 2001, when “ Agile Manifesto ” was published. They’re years away from being up to that point.
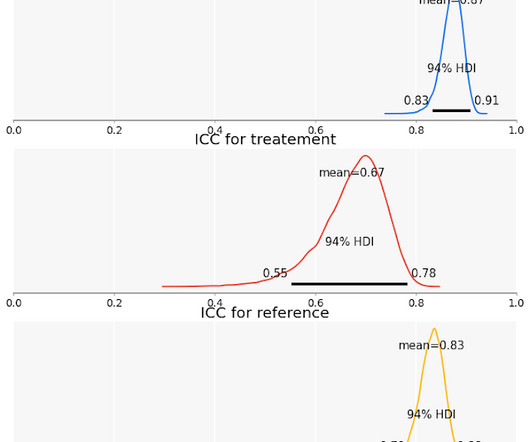
Measurement challenges Assessing reliability is essentially a process of datacollection and analysis. To do this, we collect multiple measurements for each unit of observation, and we determine if these measurements are closely related. Both published articles in the same volume of the British Journal of Psychology.
Having accurate data is crucial to this process, but finance teams struggle to easily access and connect with data. Improve dataquality. Δ The post Automate Your Yardi Real Estate DataCollection and Management appeared first on insightsoftware. Near real-time information is vital to: Save time.
Due to this book being published recently, there are not any written reviews available. 4) Big Data: Principles and Best Practices Of Scalable Real-Time Data Systems by Nathan Marz and James Warren. and this book will give you an insight into their datacollecting procedures and the reasons behind them.
ETL pipelines are commonly used in data warehousing and business intelligence environments, where data from multiple sources needs to be integrated, transformed, and stored for analysis and reporting. Technologies used for data ingestion include data connectors, ingestion frameworks, or datacollection agents.
Companies will have to publish their first sustainability reports under the new standards by as soon as 2025 1. What is the best way to collect the data required for CSRD disclosure? Offering a validation and quality assurance service to check the accuracy and consistency of your XBRL tags, and alert you of any errors or issues.
Moving data across siloed systems is time-consuming and prone to errors, hurting dataquality and reliability. Built on proven technology trusted by thousands, it delivers investor-grade data with robust controls, audit trails, and security. It’s not just a solution, it’s a partnership for a greener future.
And using datacollected during a close to make smart company decisions outside of finance is an emerging expectation for the Office of the CFO. This means real-time validation on XBRL documents to instantly flag any errors to improve overall quality in first and subsequent filings.
Whether youre developing large language models (LLMs), computer vision systems or specialized industry applications, the breadth and depth of training data directly impact a models capabilities, reliability, performance and consistency. Do we have enough data? The median training dataset contained about 3,300 datapoints in 2020.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content