This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and datacollected incorrectly, more of which we’ll address below. The model and the data specification become more important than the code.
As model building become easier, the problem of high-qualitydata becomes more evident than ever. Even with advances in building robust models, the reality is that noisy data and incomplete data remain the biggest hurdles to effective end-to-end solutions. Data integration and cleaning.
As a direct result, less IT support is required to produce reports, trends, visualizations, and insights that facilitate the data decision making process. From these developments, data science was born (or at least, it evolved in a huge way) – a discipline where hacking skills and statistics meet niche expertise.
By contrast, AI adopters are about one-third more likely to cite problems with missing or inconsistent data. The logic in this case partakes of garbage-in, garbage out : data scientists and ML engineers need qualitydata to train their models. This is consistent with the results of our dataquality survey.
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. After training, the system can make predictions (or deliver other results) based on data it hasn’t seen before. Machine learning adds uncertainty.
Emphasizing ethics and impact Like many of the government agencies it serves, Mathematica started its cloud journey on AWS shortly after Bell arrived six years ago and built the Mquiry datacollection, collaboration, management, and analytics platform on the Mathematica Cloud Support System for its myriad clients.
An education in data science can help you land a job as a data analyst , data engineer , data architect , or data scientist. It’s a fast growing and lucrative career path, with data scientists reporting an average salary of $122,550 per year , according to Glassdoor. Top 15 data science bootcamps.
What is a data engineer? Data engineers design, build, and optimize systems for datacollection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers.
Gartner agrees that synthetic data can help solve the data availability problem for AI products, as well as privacy, compliance, and anonymization challenges. Starting from scratch with your own model, in fact, requires much more datacollection work and a lot of skills.
Data scientists usually build models for data-driven decisions asking challenging questions that only complex calculations can try to answer and creating new solutions where necessary. Programming and statistics are two fundamental technical skills for data analysts, as well as data wrangling and data visualization.
It not only increases the speed and transparency of decisions and their quality, but it is also the foundation for the use of predictive planning and forecasting powered by statistical methods and machine learning. Faster information, digital change and dataquality are the greatest challenges.
“We came up with a ‘most valuable data set tool’ that allowed us really to get a clear connection to the outcomes that we’re shooting for and expert opinion on whether or not that data source would help us solve that problem.”. Automate the datacollection and cleansing process. Take a show-me approach.
Every data professional knows that ensuring dataquality is vital to producing usable query results. Streaming data can be extra challenging in this regard, as it tends to be “dirty,” with new fields that are added without warning and frequent mistakes in the datacollection process.
Data analysts contribute value to organizations by uncovering trends, patterns, and insights through data gathering, cleaning, and statistical analysis. They identify and interpret trends in complex datasets, optimize statistical results, and maintain databases while devising new datacollection processes.
Data cleansing is the process of identifying and correcting errors, inconsistencies, and inaccuracies in a dataset to ensure its quality, accuracy, and reliability. This process is crucial for businesses that rely on data-driven decision-making, as poor dataquality can lead to costly mistakes and inefficiencies.
Key features: As a professional data analysis tool, FineBI successfully meets business people’s flexible and changeable data processing requirements through self-service datasets. FineBI is supported by a high-performance Spider engine to extract, calculate and analyze a large volume of data with lightweight architecture.
All you need to know, for now, is that machine learning is a field of artificial intelligence that uses statistical techniques to give computer systems the ability to learn based on data by being trained on past examples. The biggest time sink is often around datacollection, labeling and cleaning.
Then, when we received 11,400 responses, the next step became obvious to a duo of data scientists on the receiving end of that datacollection. Over the past six months, Ben Lorica and I have conducted three surveys about “ABC” (AI, Big Data, Cloud) adoption in enterprise. Spark, Kafka, TensorFlow, Snowflake, etc.,
We found anecdotal data that suggested things such as a) CDO’s with a business, more than a technical, background tend to be more effective or successful, and b) CDOs most often came from a business background, and c) those that were successful had a good chance at becoming CEO or CEO or some other CXO (but not really CIO).
Acquiring data is often difficult, especially in regulated industries. Once relevant data has been obtained, understanding what is valuable and what is simply noise requires statistical and scientific rigor. DataQuality and Standardization. There are many excellent resources on dataquality and data governance.
As a result, concerns of data governance and dataquality were ignored. The direct consequence of bad qualitydata is misinformed decision making based on inaccurate information; the quality of the solutions is driven by the quality of the data. COVID-19 exposes shortcomings in data management.
He was saying this doesn’t belong just in statistics. He also really informed a lot of the early thinking about data visualization. It involved a lot of interesting work on something new that was data management. To some extent, academia still struggles a lot with how to stick data science into some sort of discipline.
Editor's note : The relationship between reliability and validity are somewhat analogous to that between the notions of statistical uncertainty and representational uncertainty introduced in an earlier post. Measurement challenges Assessing reliability is essentially a process of datacollection and analysis.
Most people are aware that companies collect our GPS locale, text messages, credit card purchases, social media posts, Google search history, etc., and this book will give you an insight into their datacollecting procedures and the reasons behind them.
ETL pipelines are commonly used in data warehousing and business intelligence environments, where data from multiple sources needs to be integrated, transformed, and stored for analysis and reporting. Technologies used for data ingestion include data connectors, ingestion frameworks, or datacollection agents.
DataOps Observability includes monitoring and testing the data pipeline, dataquality, data testing, and alerting. Data testing is an essential aspect of DataOps Observability; it helps to ensure that data is accurate, complete, and consistent with its specifications, documentation, and end-user requirements.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



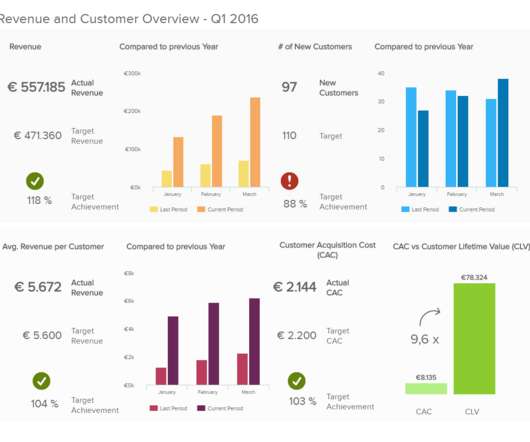



















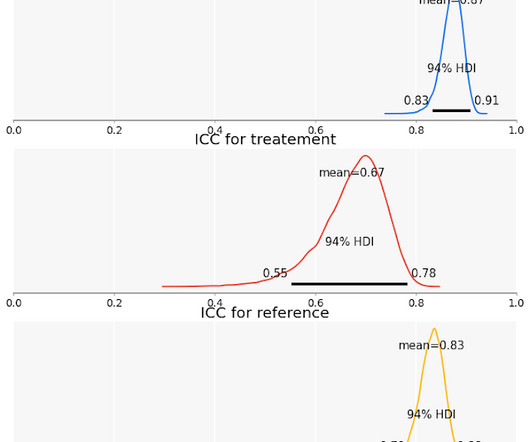











Let's personalize your content