This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI PMs should enter feature development and experimentation phases only after deciding what problem they want to solve as precisely as possible, and placing the problem into one of these categories. Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model.
2) MLOps became the expected norm in machine learning and datascience projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase.
This Domino DataScience Field Note covers Pete Skomoroch ’s recent Strata London talk. Pete indicates, in both his November 2018 and Strata London talks, that ML requires a more experimental approach than traditional software engineering. These steps also reflect the experimental nature of ML product management.
What is a data scientist? Data scientists are analytical data experts who use datascience to discover insights from massive amounts of structured and unstructured data to help shape or meet specific business needs and goals. Data scientist salary. Data scientist skills.
Analytics: The products of Machine Learning and DataScience (such as predictive analytics, health analytics, cyber analytics). A reference to a new phase in the Industrial Revolution that focuses heavily on interconnectivity, automation, Machine Learning, and real-time data. They cannot process language inputs generally.
It seems as if the experimental AI projects of 2019 have borne fruit. In 2019, 57% of respondents cited a lack of ML modeling and datascience expertise as an impediment to ML adoption; this year, slightly more—close to 58%—did so. But what kind? Where AI projects are being used within companies.
Today, SAP and DataRobot announced a joint partnership to enable customers connect core SAP software, containing mission-critical business data, with the advanced Machine Learning capabilities of DataRobot to make more intelligent business predictions with advanced analytics.
This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The first blog introduced a mock vehicle manufacturing company, The Electric Car Company (ECC) and focused on DataCollection.
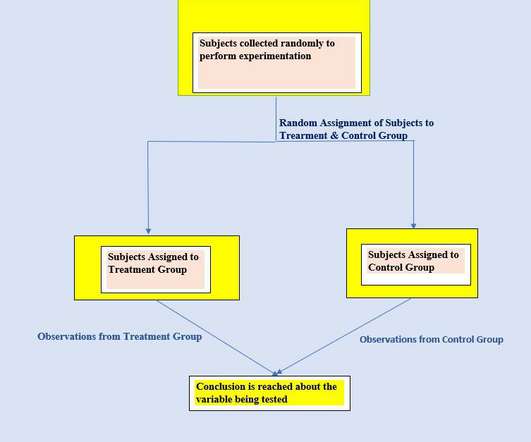
Bias ( syatematic unfairness in datacollection ) can be a potential problem in experiments and we need to take it into account while designing experiments. Some pitfalls of this type of experimentation include: Suppose an experiment is performed to observe the relationship between the snack habit of a person while watching TV.
It’s all about using data to get a clearer understanding of reality so that your company can make more strategically sound decisions (instead of relying only on gut instinct or corporate inertia). Ultimately, business intelligence and analytics are about much more than the technology used to gather and analyze data.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. They have the foundations of data infrastructure. Yet, this challenge is not insurmountable.
Each project consists of a declarative series of steps or operations that define the datascience workflow. We can think of model lineage as the specific combination of data and transformations on that data that create a model. Each user associated with a project performs work via a session.
I previously posted about my experiences with RLS offline datacollection and visualisation of the collecteddata , and have since helped with quite a few RLS surveys. My main "day job" focus in 2020 was on being the tech lead for Automattic’s new experimentation platform (ExPlat). Technical work.
Ways to get better data Efforts to improve the quality of data often have a higher return on investment than efforts to enhance models. There are three main ways to improve data: collecting more data, synthesizing new data, or augmenting existing data. DeepAugment takes 4.2 x2large instance.
This article covers causal relationships and includes a chapter excerpt from the book Machine Learning in Production: Developing and Optimizing DataScience Workflows and Applications by Andrew Kelleher and Adam Kelleher. Datacollected from this system reflects the way the world works when we just observe it.
Without clarity in metrics, it’s impossible to do meaningful experimentation. There’s a substantial literature about ethics, data, and AI, so rather than repeat that discussion, we’ll leave you with a few resources. Ongoing monitoring of critical metrics is yet another form of experimentation.
The lens of reductionism and an overemphasis on engineering becomes an Achilles heel for datascience work. Instead, consider a “full stack” tracing from the point of datacollection all the way out through inference. – back to the structure of the dataset. Let’s look through some antidotes. Ergo, less interpretable.
In Paco Nathan ‘s latest column, he explores the role of curiosity in datascience work as well as Rev 2 , an upcoming summit for datascience leaders. Welcome back to our monthly series about datascience. and dig into details about where science meets rhetoric in datascience.
Implicitly, there was a prior belief about some interesting causal mechanism or an underlying hypothesis motivating the collection of the data. As computing and storage have made datacollection cheaper and easier, we now gather data without this underlying motivation.
With breaking this bottleneck in mind, I’ve used my time as an Insight DataScience Fellow to build the AIgent, a web-based neural net to connect writers to representation. In this article, I will discuss the construction of the AIgent, from datacollection to model assembly. Instead, I built the AIgent.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content