This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The foundation of any data product consists of “solid data infrastructure, including datacollection, data storage, data pipelines, data preparation, and traditional analytics.” data platform, metrics, ML/AI research, and applied ML). Avinash Kaushik’s Web Analytics 2.0
2) MLOps became the expected norm in machine learning and datascience projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase.
Data Platforms. Over the last 12-18 months, companies that use a lot of ML and employ teams of data scientists have been describing their internal datascience platforms (see, for example, Uber , Netflix , Twitter , and Facebook ). How to build analytic products in an age when data privacy has become critical”.
For AI, there’s no universal standard for when data is ‘clean enough.’ A lot of organizations spend a lot of time discarding or improving zip codes, but for most datascience, the subsection in the zip code doesn’t matter,” says Kashalikar. We’re looking at a general geographical area to see what the trend might be.
While sometimes it’s okay to follow your instincts, the vast majority of your business-based decisions should be backed by metrics, facts, or figures related to your aims, goals, or initiatives that can ensure a stable backbone to your management reports and business operations. 3) Gather data now. 6) Analyze and understand.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
What is a data scientist? Data scientists are analytical data experts who use datascience to discover insights from massive amounts of structured and unstructured data to help shape or meet specific business needs and goals. Data scientist salary. Data scientist skills.
Here are four specific metrics from the report, highlighting the potentially huge enterprise system benefits coming from implementing Splunk’s observability and monitoring products and services: Four times as many leaders who implement observability strategies resolve unplanned downtime in just minutes, not hours or days.
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG data integrity and fostering collaboration with sustainability teams.
By PATRICK RILEY For a number of years, I led the datascience team for Google Search logs. We were often asked to make sense of confusing results, measure new phenomena from logged behavior, validate analyses done by others, and interpret metrics of user behavior. Something like histograms, CDFs, Q-Q plots, etc.
This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The first blog introduced a mock vehicle manufacturing company, The Electric Car Company (ECC) and focused on DataCollection.
Because ML is becoming more integrated into daily business operations, datascience teams are looking for faster, more efficient ways to manage ML initiatives, increase model accuracy and gain deeper insights. MLOps is the next evolution of data analysis and deep learning. How MLOps will be used within the organization.
Therefore, learning some useful data mining procedures may prove beneficial in this regard. As taught in DataScience Dojo’s datascience bootcamp , you will have improved prediction and forecasting with respect to your product. DataCollection.
One of the most-asked questions from aspiring data scientists is: “What is the best language for datascience? People looking into datascience languages are usually confused about which language they should learn first: R or Python. NLP can be used on written text or speech data. R or Python?”.
Although the oil company has been producing massive amounts of data for a long time, with the rise of new cloud-based technologies and data becoming more and more relevant in business contexts, they needed a way to manage their information at an enterprise level and keep up with the new skills in the data industry.
The potential use cases for BI extend beyond the typical business performance metrics of improved sales and reduced costs. BI focuses on descriptive analytics, datacollection, data storage, knowledge management, and data analysis to evaluate past business data and better understand currently known information.
Data observability becomes business-critical Data observability extends the concept of data quality by closely monitoring data as it flows in and out of the applications. A key data observability attribute is that it acts on metadata, providing a safe way to monitor data directly within applications.
Further, imbalanced data exacerbates problems arising from the curse of dimensionality often found in such biological data. Insufficient training data in the minority class — In domains where datacollection is expensive, a dataset containing 10,000 examples is typically considered to be fairly large. References.
The following figure shows some of the metrics derived from the study. In this post, we discuss how you can use purpose-built AWS services to create an end-to-end data strategy for C360 to unify and govern customer data that address these challenges. Organizations using C360 achieved 43.9% reduction in sales cycle duration, 22.8%
Programming and statistics are two fundamental technical skills for data analysts, as well as data wrangling and data visualization. Overall, however, what often characterizes them is a focus on datacollection, manipulation, and analysis, using standard formulas and methods, and acting as gatekeepers of an organization’s data.
Companies with successful ML projects are often companies that already have an experimental culture in place as well as analytics that enable them to learn from data. Ensure that product managers work on projects that matter to the business and/or are aligned to strategic company metrics. That’s another pattern.
An interactive dashboard is a data management tool that tracks, analyzes, monitors, and visually displays key business metrics while allowing users to interact with data, enabling them to make well-informed, data-driven, and healthy business decisions. Benefit from amazing interactive dashboards! 4) Cross Tab Filters.
What Is Data Literacy? Data literacy is the ability to understand datascience and AI applications critically using basic data visualization, communication, and reasoning skills. And beyond uniting diverse stakeholders, data literacy also empowers sectoral regulators to provide industry-specific guidance.
Over the past 5 years, big data and BI became more than just datascience buzzwords. Without real-time insight into their data, businesses remain reactive, miss strategic growth opportunities, lose their competitive edge, fail to take advantage of cost savings options, don’t ensure customer satisfaction… the list goes on.
Each project consists of a declarative series of steps or operations that define the datascience workflow. We can think of model lineage as the specific combination of data and transformations on that data that create a model. Each user associated with a project performs work via a session.
Data products and data mesh Data products are assembled data from sources that can serve a set of functional needs that can be packaged into a consumable unit. Each data product has its own lifecycle environment where its data and AI assets are managed in their product-specific data lakehouse.
Paco Nathan covers recent research on data infrastructure as well as adoption of machine learning and AI in the enterprise. Welcome back to our monthly series about datascience! This month, the theme is not specifically about conference summaries; rather, it’s about a set of follow-up surveys from Strata Data attendees.
Read Gartner’s latest research, “Doing Machine Learning Without Hiring (More) Data Scientists,” which carves out four recommendations for organizations wishing to launch datascience initiatives. We rely on data and analytics to assist in all three areas.
Folks can work faster, and with more agility, unearthing insights from their data instantly to stay competitive. Yet the explosion of datacollection and volume presents new challenges. The third challenge was around trusting the data. The fourth challenge was around using the data. Set consistent data policies.
And how can the datacollected across multiple touchpoints, from retail locations to the supply chain to the factory be easily integrated? Enter data warehousing. So how is the data extracted? By using Structured Query Language, or SQL, the language used to manipulate and extract data stored in cubes.
In this technical post, we’ll focus on some changes we’ve made to allow custom models to operate as an algorithm on Algorithmia, while still feeding predictions, input, and other metrics back to the DataRobot MLOps platform —a true best of both worlds. DataScience Expertise Meets Scalability.
Whether a project aims to improve suicide prevention using datascience or to create new revenue streams by reimagining an organization’s core business, CIO 100 Award winners demonstrate the innovative spirit of today’s IT in the face of rapidly evolving organizational challenges.
In short, I was faced with two major difficulties regarding datacollection: I didn’t have nearly enough images, and the images I did have were not representative of a realistic gym environment. We pass 3 parameters: loss, optimizer , and metrics. The documentation for Keras’ metric functions can be found here.
Regardless of the division or use case it is related to, dimensional data models can be used to store data obtained from tracking various processes like patient encounters, provider practice metrics, aftercare surveys, and more. Amazon Redshift RA3 instances and Amazon Redshift Serverless are perfect choices for a data vault.
Therefore, IBM observes that more clients tend to consult AI leaders to help establish governance and enhance AI and datascience capabilities, an operating model in the form of co-delivery partnerships. This results in many groups using a large gamut of AI-based tools that are not fully integrated into a cohesive system and platform.
Reichental describes data governance as the overarching layer that empowers people to manage data well ; as such, it is focused on roles & responsibilities, policies, definitions, metrics, and the lifecycle of the data. In this way, data governance is the business or process side.
Cloudera often partners with these companies to define the desired path, set reasonable milestones and success metrics, and aide solution design. “Bringing together as much of this data and information as possible will help organizations gain a richer, more detailed picture of customers. ” And teases at the reward.
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. Information retrieval The first step in the text-mining workflow is information retrieval, which requires data scientists to gather relevant textual data from various sources (e.g., What is text mining?
And how can the datacollected across multiple touchpoints, from retail locations to the supply chain to the factory be easily integrated? Enter data warehousing. So how is the data extracted? By using Structured Query Language, or SQL, the language used to manipulate and extract data stored in cubes.
Eighty percent of this problem is collecting the data and then transforming the data. The other 20 percent is ML- and datascience–related tasks like finding the right model, doing EDA, and feature engineering. Gathering the Data. there is a list of data sources to extract and transform. In Figure 6.1,
This research does not tell you where to do the work; it is meant to provide the questions to ask in order to work out where to target the work, spanning reporting/analytics (classic), advanced analytics and datascience (lab), data management and infrastructure, and D&A governance. We write about data and analytics.
The first step in building an AI solution is identifying the problem you want to solve, which includes defining the metrics that will demonstrate whether you’ve succeeded. It sounds simplistic to state that AI product managers should develop and ship products that improve metrics the business cares about. Agreeing on metrics.
I’ve worked on projects without MLOps and I had to like, always go back and forth between the engineering and datascience teams explaining them about each other’s requirements, because both of them understood so little about each other’s jobs. Personally, you know, I can relate to this so much. Kishore: Hmm.
Paco Nathan presented, “DataScience, Past & Future” , at Rev. At Rev’s “ DataScience, Past & Future” , Paco Nathan covered contextual insight into some common impactful themes over the decades that also provided a “lens” help data scientists, researchers, and leaders consider the future.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





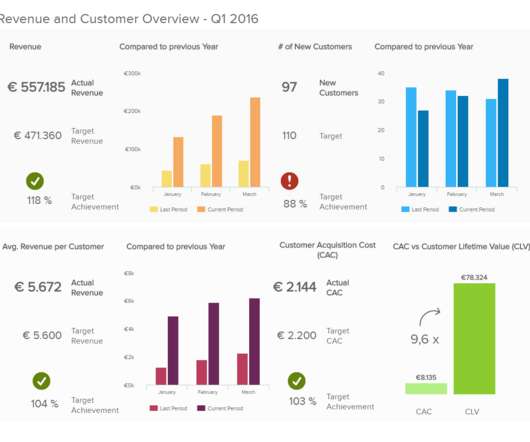


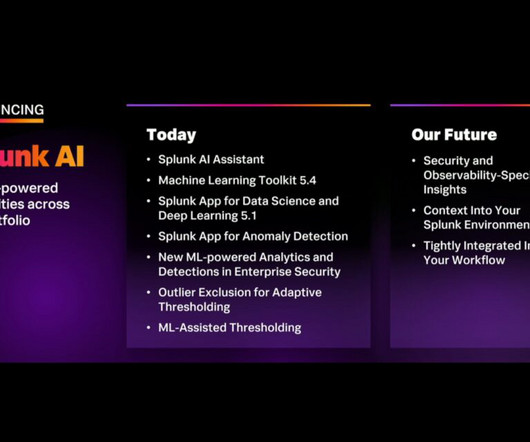






















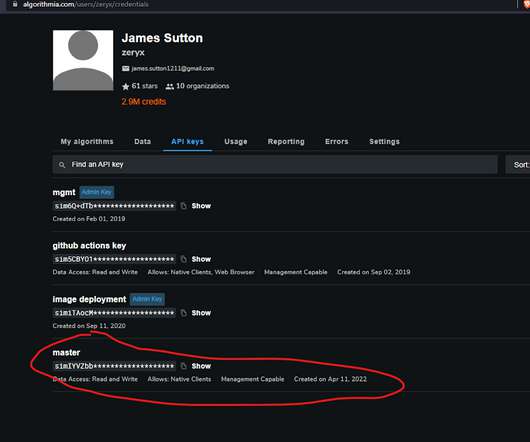



















Let's personalize your content