This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction In order to build machine learning models that are highly generalizable to a wide range of test conditions, training models with high-quality data is essential.
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and datacollected incorrectly, more of which we’ll address below. Datacollected for one purpose can have limited use for other questions.
What is datascience? Datascience is a method for gleaning insights from structured and unstructured data using approaches ranging from statistical analysis to machine learning. Datascience gives the datacollected by an organization a purpose. Datascience vs. data analytics.
An education in datascience can help you land a job as a data analyst , data engineer , data architect , or data scientist. Here are the top 15 datascience boot camps to help you launch a career in datascience, according to reviews and datacollected from Switchup.
Focus on the strategies that aim these tools, talents, and technologies on reaching business mission and goals: e.g., data strategy, analytics strategy, observability strategy ( i.e., why and where are we deploying the data-streaming sensors, and what outcomes should they achieve?).
Data Platforms. Over the last 12-18 months, companies that use a lot of ML and employ teams of data scientists have been describing their internal datascience platforms (see, for example, Uber , Netflix , Twitter , and Facebook ). How to build analytic products in an age when data privacy has become critical”.
Since they consume a significant amount of time spent on most datascience projects, we highlight these two main classes of data quality problems in this post: Data unification and integration. HoloClean adopts the well-known “noisy channel” model to explain how data was generated and how it was “polluted.”
As a direct result, less IT support is required to produce reports, trends, visualizations, and insights that facilitate the data decision making process. From these developments, datascience was born (or at least, it evolved in a huge way) – a discipline where hacking skills and statistics meet niche expertise.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
What is a data scientist? Data scientists are analytical data experts who use datascience to discover insights from massive amounts of structured and unstructured data to help shape or meet specific business needs and goals. Data scientist salary. Data scientist skills.
Analytics: The products of Machine Learning and DataScience (such as predictive analytics, health analytics, cyber analytics). A reference to a new phase in the Industrial Revolution that focuses heavily on interconnectivity, automation, Machine Learning, and real-time data. They cannot process language inputs generally.
What is a data engineer? Data engineers design, build, and optimize systems for datacollection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. Data engineer vs. data architect.
In 2019, 57% of respondents cited a lack of ML modeling and datascience expertise as an impediment to ML adoption; this year, slightly more—close to 58%—did so. data cleansing services that profile data and generate statistics, perform deduplication and fuzzy matching, etc.—or or function-as-a-service designs.
Producing insights from raw data is a time-consuming process. Predictive modeling efforts rely on dataset profiles , whether consisting of summary statistics or descriptive charts. The Importance of Exploratory Analytics in the DataScience Lifecycle. For one, Python remains the leading language for datascience research.
Philosophers and economists may argue about the quality of the metaphor, but there’s no doubt that organizing and analyzing data is a vital endeavor for any enterprise looking to deliver on the promise of data-driven decision-making. And to do so, a solid data management strategy is key.
In these instances, data feeds come largely from various advertising channels, and the reports they generate are designed to help marketers spend wisely. Others aim simply to manage the collection and integration of data, leaving the analysis and presentation work to other tools that specialize in datascience and statistics.
The first was becoming one of the first research companies to move its panels and surveys online, reducing costs and increasing the speed and scope of datacollection. We rely on cloud-scale technologies and proprietary datascience and analytics engines built on open standards to handle massive data sets,” says Mohammed.
For the modern digital organization, the proof of any inference (that drives decisions) should be in the data! Rich and diverse datacollections enable more accurate and trustworthy conclusions. Obviously, each one of these diagnoses carries a seriously different course of action and treatment.
One of the most-asked questions from aspiring data scientists is: “What is the best language for datascience? People looking into datascience languages are usually confused about which language they should learn first: R or Python. NLP can be used on written text or speech data. R or Python?”.
BI focuses on descriptive analytics, datacollection, data storage, knowledge management, and data analysis to evaluate past business data and better understand currently known information. Whereas BI studies historical data to guide business decision-making, business analytics is about looking forward.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects.
Older statistical modeling methodologies only used three or four variables, so gaming companies can make much more nuanced insights these days. Towards DataScience wrote a very useful article on the evolution of analytics in the gaming industry. Advances in digital datacollection and predictive analytics should help them.
What are the benefits of data management platforms? Modern, data-driven marketing teams must navigate a web of connected data sources and formats. Others aim simply to manage the collection and integration of data, leaving the analysis and presentation work to other tools that specialize in datascience and statistics.
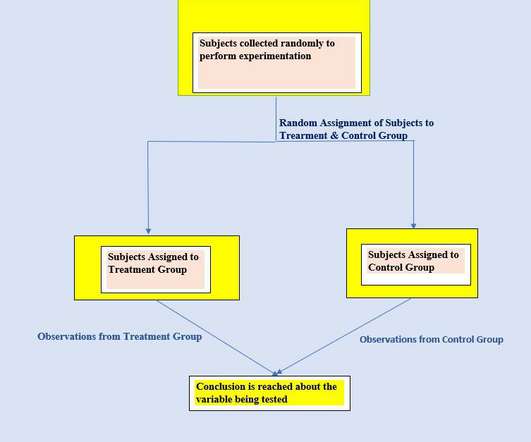
Bias ( syatematic unfairness in datacollection ) can be a potential problem in experiments and we need to take it into account while designing experiments. Statistics Essential for Dummies by D. Rumsey Statistical Reasoning Course by Stanford Ligunita Introduction to the Practice of Statistics by D. REFERENCES.
Data scientists usually build models for data-driven decisions asking challenging questions that only complex calculations can try to answer and creating new solutions where necessary. Programming and statistics are two fundamental technical skills for data analysts, as well as data wrangling and data visualization.
By PATRICK RILEY For a number of years, I led the datascience team for Google Search logs. Some people seemed to be naturally good at doing this kind of high quality data analysis. Generally, if the relative amount of data in a slice is the same across your two groups, you can safely make a comparison.
Therefore, learning some useful data mining procedures may prove beneficial in this regard. As taught in DataScience Dojo’s datascience bootcamp , you will have improved prediction and forecasting with respect to your product. DataCollection. Regression.
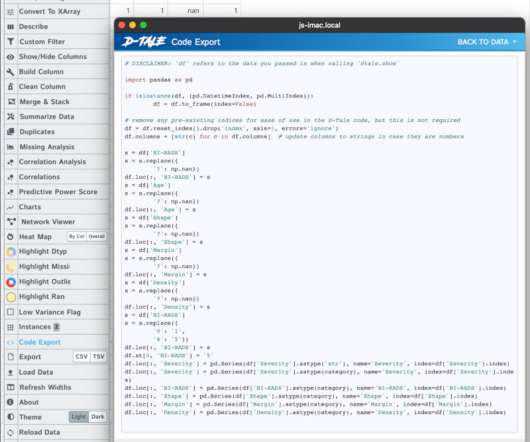
Taking a closer look at the data you will notice that some columns have questions marks ? For this dataset that is the way the datacollection denotes missing data. Let’s look at some examples of the data in the dataset: masses.iloc[[20, 456, 512],:]. Severity is made out of integers. Pandas Profiler.
Enterprises that are just starting to move to this discipline should keep in mind that at its core MLOps is about creating strong connections between datascience and data engineering. “To To ensure the success of an MLOps project, you need both data engineers and data scientists on the same team,” Zuccarelli says.
Enterprises that are just starting to move to this discipline should keep in mind that at its core MLOps is about creating strong connections between datascience and data engineering. “To To ensure the success of an MLOps project, you need both data engineers and data scientists on the same team,” Zuccarelli says.
We are needed today because datacollection is hard. Most humans employed by companies were unable to access data – not intelligent enough or trained enough or simply time pressures. Sidebar: If you don’t know these three phrases, please watch my short talk: A Big Data Imperative: Driving Big Action.].
This may seem like a pretty big constraint because you cannot do analyses which require iterating over the data with state, such as fitting a logistic regression with stochastic optimization or finding the inverse of a giant matrix. However, it turns out to be quite useful for datascience applications.
Data analysts contribute value to organizations by uncovering trends, patterns, and insights through data gathering, cleaning, and statistical analysis. They identify and interpret trends in complex datasets, optimize statistical results, and maintain databases while devising new datacollection processes.
Key features: As a professional data analysis tool, FineBI successfully meets business people’s flexible and changeable data processing requirements through self-service datasets. FineBI is supported by a high-performance Spider engine to extract, calculate and analyze a large volume of data with lightweight architecture.
It includes only ML papers and related entities; this SPARQL query shows some statistics: papers tasks models datasets methods evaluations repos 376557 4267 24598 8322 2101 52519 153476 We can start with these repositories (most of them are on Github) and get all their topics. We can start with a connecting dataset like LinkedPapersWithCode.
For instance, in accounting data cleansing, finance teams might remove duplicate transactions, correct misclassified entries, or update missing financial details to ensure accurate reporting. Benefits of Data Cleansing Messy data slows everything downbad decisions, wasted time, and frustration all stem from inaccurate information.
This article covers causal relationships and includes a chapter excerpt from the book Machine Learning in Production: Developing and Optimizing DataScience Workflows and Applications by Andrew Kelleher and Adam Kelleher. You saw in the previous chapter that conditioning can break statistical dependence. Introduction.
Paco Nathan covers recent research on data infrastructure as well as adoption of machine learning and AI in the enterprise. Welcome back to our monthly series about datascience! This month, the theme is not specifically about conference summaries; rather, it’s about a set of follow-up surveys from Strata Data attendees.
Universities were only just beginning to plan formal academic datascience programs, and the skills to be taught in those programs were still being identified. This year, there are more than 900 academic programs offering training in datascience. A lack of data literacy slows down the process.
They can arise from datacollection errors or other unlikely-to-repeat causes such as an outage somewhere on the Internet. If unaccounted for, these data points can have an adverse impact on forecast accuracy by disrupting seasonality, holiday, or trend estimation. Forecasting data and methods". [2] Specifically, see "1.4
As a result, there has been a recent explosion in individual statistics that try to measure a player’s impact. Eighty percent of this problem is collecting the data and then transforming the data. The other 20 percent is ML- and datascience–related tasks like finding the right model, doing EDA, and feature engineering.
Therefore, IBM observes that more clients tend to consult AI leaders to help establish governance and enhance AI and datascience capabilities, an operating model in the form of co-delivery partnerships. This results in many groups using a large gamut of AI-based tools that are not fully integrated into a cohesive system and platform.
Real-world datasets can be missing values due to the difficulty of collecting complete datasets and because of errors in the datacollection process. Recentering the data means that we translate the values so that the extremes are different and the intermediate values are moved in some consistent way. Discretization.
All you need to know, for now, is that machine learning is a field of artificial intelligence that uses statistical techniques to give computer systems the ability to learn based on data by being trained on past examples. They have the foundations of data infrastructure.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content