This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and datacollected incorrectly, more of which we’ll address below. The model and the data specification become more important than the code.
Even if we boosted the quality of the available data via unification and cleaning, it still might not be enough to power the even more complex analytics and predictions models (often built as a deeplearning model). An important paradigm for solving both these problems is the concept of data programming.
People tend to use these phrases almost interchangeably: Artificial Intelligence (AI), Machine Learning (ML) and DeepLearning. DeepLearning is a specific ML technique. Most DeepLearning methods involve artificial neural networks, modeling how our bran works. There won’t be any need for them.
To see this, look no further than Pure Storage , whose core mission is to “ empower innovators by simplifying how people consume and interact with data.” In deeplearning applications (including GenAI, LLMs, and computer vision), a data object (e.g.,
An important part of artificial intelligence comprises machine learning, and more specifically deeplearning – that trend promises more powerful and fast machine learning. An exemplary application of this trend would be Artificial Neural Networks (ANN) – the predictive analytics method of analyzing data.
It’s a fast growing and lucrative career path, with data scientists reporting an average salary of $122,550 per year , according to Glassdoor. Here are the top 15 data science boot camps to help you launch a career in data science, according to reviews and datacollected from Switchup. Data Science Dojo.
AI personalization utilizes data, customer engagement, deeplearning, natural language processing, machine learning, and more to curate highly tailored experiences to end-users and customers. AI can also be integrated into products to better ensure their safety and the safety of the people who use them.
Let’s not forget that big data and AI can also automate about 80% of the physical work required from human beings, 70% of the data processing, and more than 60% of the datacollection tasks. From the statistics shown, this means that both AI and big data have the potential to affect how we work in the workplace.
The Public Sector data challenge. Robust online systems have streamlined interactions and generated a wealth of new data to support mission success and enhanced citizen engagements. However, this rapid scaling up of data across government agencies brings with it new challenges. Modernization has been a boon to government.
The emergence of NLG has dramatically improved the quality of automated customer service tools, making interactions more pleasant for users, and reducing reliance on human agents for routine inquiries. Machine learning (ML) and deeplearning (DL) form the foundation of conversational AI development. billion by 2030.
The goal is to establish the Mayflower 400 as an open platform for marine research that would reduce costs and ease the burden on scientists and sailors, who have to brave a dangerous and unpredictable environment in the course of their data-collecting missions. We’re finding that it doesn’t have to be completely autonomous.
Achieving that level of governance at scale requires a common understanding of AI and data concepts. Individuals interacting with AI systems should possess a baseline data literacy, especially in high-risk use cases that require human collaboration at the final decision-making stage.
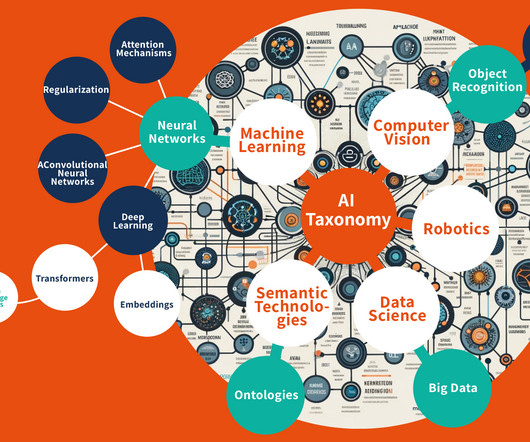
The official (first) repo is tensorflow/tensor2tensor that has topics: machine-learning reinforcement-learningdeep-learning machine-translation tpu. By exploring the first topic machine-learning , we find 117k Github repos. The taxonomy integrates various data sources, offering a holistic view of AI innovation.
AI marketing is the process of using AI capabilities like datacollection, data-driven analysis, natural language processing (NLP) and machine learning (ML) to deliver customer insights and automate critical marketing decisions. What is AI marketing?
Here we will demonstrate an end-to-end unattended workflow that: trains a new model on the Fashion MNIST Dataset uploads it to an Algorithmia DataCollection creates a new algorithm on Algorithmia creates DataRobot deployment Links everything together via the MLOps Agent. The Demo: Autoscaling with MLOps.
This talk will describe how you can navigate all these challenges that you’re going to face and build a business where every product interaction benefits from your investment in machine learning. It used deeplearning to build an automated question answering system and a knowledge base based on that information.
This tradeoff between impact and development difficulty is particularly relevant for products based on deeplearning: breakthroughs often lead to unique, defensible, and highly lucrative products, but investing in products with a high chance of failure is an obvious risk. Prototypes and Data Product MVPs.
The interest in interpretation of machine learning has been rapidly accelerating in the last decade. This can be attributed to the popularity that machine learning algorithms, and more specifically deeplearning, has been gaining in various domains. Methods for explaining DeepLearning.
The lens of reductionism and an overemphasis on engineering becomes an Achilles heel for data science work. Instead, consider a “full stack” tracing from the point of datacollection all the way out through inference. Machine learning model interpretability. training data”) show the tangible outcomes.
By virtue of that, if you take those log files of customers interactions, you aggregate them, then you take that aggregated data, run machine learning models on them, you can produce data products that you feed back into your web apps, and then you get this kind of effect in business. You can take TensorFlow.js
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content