This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction As a data scientist, you have the power to revolutionize the real estate industry by developing models that can accurately predict house prices. This blog post will teach you how to build a real estate price prediction model from start to finish. appeared first on Analytics Vidhya.
Supervised learning is the most popular ML technique among mature AI adopters, while deeplearning is the most popular technique among organizations that are still evaluating AI. The logic in this case partakes of garbage-in, garbage out : data scientists and ML engineers need quality data to train their models.
2) MLOps became the expected norm in machine learning and data science projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase.
You must detect when the model has become stale, and retrain it as necessary. Products based on deeplearning can be difficult (or even impossible) to develop; it’s a classic “high return versus high risk” situation, in which it is inherently difficult to calculate return on investment. Modeling and Evaluation.
We can collect many examples of what we want the program to do and what not to do (examples of correct and incorrect behavior), label them appropriately, and train a model to perform correctly on new inputs. In short, we can use machine learning to automate software development itself. Instead, we can program by example.
There has been a significant increase in our ability to build complex AI models for predictions, classifications, and various analytics tasks, and there’s an abundance of (fairly easy-to-use) tools that allow data scientists and analysts to provision complex models within days. Data integration and cleaning.
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. The model is produced by code, but it isn’t code; it’s an artifact of the code and the training data.
These roles include data scientist, machine learning engineer, software engineer, research scientist, full-stack developer, deeplearning engineer, software architect, and field programmable gate array (FPGA) engineer.
Beyond the early days of datacollection, where data was acquired primarily to measure what had happened (descriptive) or why something is happening (diagnostic), datacollection now drives predictive models (forecasting the future) and prescriptive models (optimizing for “a better future”).
To see this, look no further than Pure Storage , whose core mission is to “ empower innovators by simplifying how people consume and interact with data.” RAG is the essential link between two things: (a) the general large language models (LLMs) available in the market, and (b) a specific organization’s local knowledge base.
People tend to use these phrases almost interchangeably: Artificial Intelligence (AI), Machine Learning (ML) and DeepLearning. DeepLearning is a specific ML technique. Most DeepLearning methods involve artificial neural networks, modeling how our bran works. There won’t be any need for them.
In this example, the Machine Learning (ML) model struggles to differentiate between a chihuahua and a muffin. Will the model correctly determine it is a muffin or get confused and think it is a chihuahua? The extent to which we can predict how the model will classify an image given a change input (e.g. Model Visibility.
It’s impossible to deny the importance of data in several industries, but that data can get overwhelming if it isn’t properly managed. The problem is that managing and extracting valuable insights from all this data needs exceptional datacollecting, which makes data ingestion vital.
It’s a fast growing and lucrative career path, with data scientists reporting an average salary of $122,550 per year , according to Glassdoor. Here are the top 15 data science boot camps to help you launch a career in data science, according to reviews and datacollected from Switchup. Data Science Dojo.
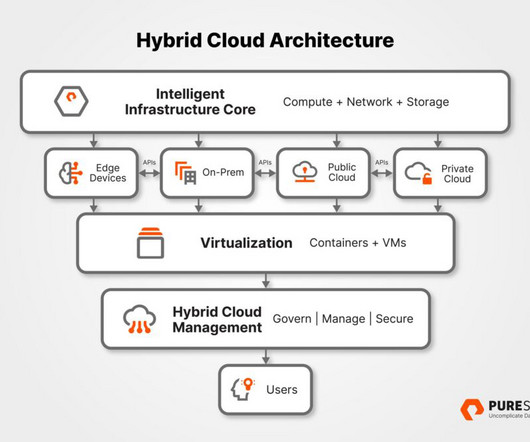
All industries and modern applications are undergoing rapid transformation powered by advances in accelerated computing, deeplearning, and artificial intelligence. The next phase of this transformation requires an intelligent data infrastructure that can bring AI closer to enterprise data.
These support a wide array of uses, such as data analysis, manipulation, visualizations, and machine learning (ML) modeling. Some standard Python libraries are Pandas, Numpy, Scikit-Learn, SciPy, and Matplotlib. These libraries are used for datacollection, analysis, data mining, visualizations, and ML modeling.
Predictive analytics definition Predictive analytics is a category of data analytics aimed at making predictions about future outcomes based on historical data and analytics techniques such as statistical modeling and machine learning. Financial services: Develop credit risk models. from 2022 to 2028.
Machine learning algorithms enable fraud detection systems to distinguish between legitimate and fraudulent behaviors. Some of these algorithms can be adaptive to quickly update the model to take into account new, previously unseen fraud tactics allowing for dynamic rule adjustment. The Public Sector data challenge.
Even when customers have tuned their rules for years with fraud analysts who know the space, we come in with machine learningmodels and beat them,” says Baumhof. Current machine learning systems can make decisions as fast as traditional rules-based systems. Augment complex processes — especially for datacollection.
An important part of artificial intelligence comprises machine learning, and more specifically deeplearning – that trend promises more powerful and fast machine learning. An exemplary application of this trend would be Artificial Neural Networks (ANN) – the predictive analytics method of analyzing data.
They use drones for tasks as simple as aerial photography or as complex as sophisticated datacollection and processing. It can offer data on demand to different business units within an organization, with the help of various sensors and payloads. The global commercial drone market is projected to grow from USD 8.15
But few organizations have made the strategic shift to managing “data as a product.” ” This data management means applying product development practices to data. Each data product has its own lifecycle environment where its data and AI assets are managed in their product-specific data lakehouse.
Let’s not forget that big data and AI can also automate about 80% of the physical work required from human beings, 70% of the data processing, and more than 60% of the datacollection tasks. From the statistics shown, this means that both AI and big data have the potential to affect how we work in the workplace.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Figure 1 illustrates the framework for Scope 3 emission estimation employing a large language model.
The goal is to establish the Mayflower 400 as an open platform for marine research that would reduce costs and ease the burden on scientists and sailors, who have to brave a dangerous and unpredictable environment in the course of their data-collecting missions.
For example, we are working on a geospatial foundation model, which can be fine-tuned to track deforestation, detect greenhouse gases (GHGs) or predict crop yields. Foundation models help identify and analyze data, surface trends such as where and why populations are moving and provide insight on how to serve them with renewable energy.
While the word “data” has been common since the 1940s, managing data’s growth, current use, and regulation is a relatively new frontier. . Governments and enterprises are working hard today to figure out the structures and regulations needed around datacollection and use.
It used deeplearning to build an automated question answering system and a knowledge base based on that information. It is like the Google knowledge graph with all those smart, intelligent cards and the ability to create your own cards out of your own data. There’s no substitute for that experience.
Data literacy ensures that diverse perspectives are baked into AI governance and leads to the production of AI systems that achieve better and more consistent outcomes. It is a key component of developing responsible AI, and promotes trust not only in AI concepts but also in individual AI models. What Is Data Literacy?
Because ML is becoming more integrated into daily business operations, data science teams are looking for faster, more efficient ways to manage ML initiatives, increase model accuracy and gain deeper insights. MLOps is the next evolution of data analysis and deeplearning. How the models are stored.
Machine learning (ML) and deeplearning (DL) form the foundation of conversational AI development. DL models can improve over time through further training and exposure to more data. These technologies enable systems to interact, learn from interactions, adapt and become more efficient.
Then, when we received 11,400 responses, the next step became obvious to a duo of data scientists on the receiving end of that datacollection. Over the past six months, Ben Lorica and I have conducted three surveys about “ABC” (AI, Big Data, Cloud) adoption in enterprise. Who builds their models?
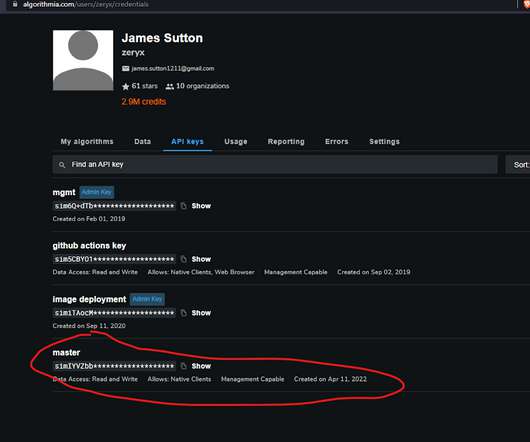
In this technical post, we’ll focus on some changes we’ve made to allow custom models to operate as an algorithm on Algorithmia, while still feeding predictions, input, and other metrics back to the DataRobot MLOps platform —a true best of both worlds. Data Science Expertise Meets Scalability. Then select, Create new key.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machine learningmodels, and data mining techniques to derive pertinent qualitative information from unstructured text data.
Other uses include Netflix offering viewing recommendations powered by models that process data sets collected from viewing history; LinkedIn uses ML to filter items in a newsfeed, making employment recommendations and suggestions on who to connect with; and Spotify uses ML models to generate its song recommendations.
“Data is at the core of digital transformation, and data ingestion, transmission, storage, and analysis are key steps,” says Chen “Huawei provides full-stack datacollection, transmission, storage, computing, and analysis solutions to effectively support end-to-end closed-loop data processing.”.
data science’s emergence as an interdisciplinary field – from industry, not academia. why data governance, in the context of machine learning is no longer a “dry topic” and how the WSJ’s “global reckoning on data governance” is potentially connected to “premiums on leveraging data science teams for novel business cases”.
a “pre-trained” model) to be recycled and reused for many different tasks. In short, I was faced with two major difficulties regarding datacollection: I didn’t have nearly enough images, and the images I did have were not representative of a realistic gym environment. This structure allows the same network (i.e.
In this article we cover explainability for black-box models and show how to use different methods from the Skater framework to provide insights into the inner workings of a simple credit scoring neural network model. The interest in interpretation of machine learning has been rapidly accelerating in the last decade.
Paco Nathan’s latest article features several emerging threads adjacent to model interpretability. I’ve been out themespotting and this month’s article features several emerging threads adjacent to the interpretability of machine learningmodels. Machine learningmodel interpretability. Introduction.
These technologically modern municipalities use a variety of systems, devices, and sensors to enhance services and operations, manage assets, and increase efficiency — fueled by the power of data. To make smart cities work, a governance model supported by champions from across the organization is essential.”
We’ll examine National Oceanic and Atmospheric Administration (NOAA) data management practices which I learned about at their workshop, as a case study in how to handle datacollection, dataset stewardship, quality control, analytics, and accountability when the stakes are especially high. How cool is that?!
AI personalization utilizes data, customer engagement, deeplearning, natural language processing, machine learning, and more to curate highly tailored experiences to end-users and customers. AI can also be integrated into products to better ensure their safety and the safety of the people who use them.
It includes only ML papers and related entities; this SPARQL query shows some statistics: papers tasks models datasets methods evaluations repos 376557 4267 24598 8322 2101 52519 153476 We can start with these repositories (most of them are on Github) and get all their topics. We can start with a connecting dataset like LinkedPapersWithCode.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content