This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Without clarity in metrics, it’s impossible to do meaningful experimentation. AI PMs must ensure that experimentation occurs during three phases of the product lifecycle: Phase 1: Concept During the concept phase, it’s important to determine if it’s even possible for an AI product “ intervention ” to move an upstream business metric.
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. After training, the system can make predictions (or deliver other results) based on data it hasn’t seen before. Machine learning adds uncertainty.
— Thank you to Ann Emery, Depict Data Studio, and her Simple Spreadsheets class for inviting us to talk to them about the use of statistics in nonprofit program evaluation! But then we realized that much of the time, statistics just don’t have much of a role in nonprofit work. Why Nonprofits Shouldn’t Use Statistics.
It seems as if the experimental AI projects of 2019 have borne fruit. data cleansing services that profile data and generate statistics, perform deduplication and fuzzy matching, etc.—or However, organizations need to address important data governance and data conditioning to expand and scale their AI practices. [1]
Computer Vision: Data Mining: Data Science: Application of scientific method to discovery from data (including Statistics, Machine Learning, data visualization, exploratory data analysis, experimentation, and more). They cannot process language inputs generally. See [link]. 3) Warehouse / Logistics.
According to data from Robert Half’s 2021 Technology and IT Salary Guide, the average salary for data scientists, based on experience, breaks down as follows: 25th percentile: $109,000 50th percentile: $129,000 75th percentile: $156,500 95th percentile: $185,750 Data scientist responsibilities.
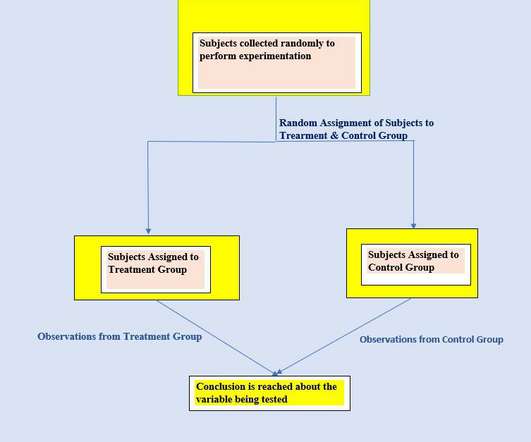
Bias ( syatematic unfairness in datacollection ) can be a potential problem in experiments and we need to take it into account while designing experiments. Some pitfalls of this type of experimentation include: Suppose an experiment is performed to observe the relationship between the snack habit of a person while watching TV.
Emphasizing ethics and impact Like many of the government agencies it serves, Mathematica started its cloud journey on AWS shortly after Bell arrived six years ago and built the Mquiry datacollection, collaboration, management, and analytics platform on the Mathematica Cloud Support System for its myriad clients.
We are far too enamored with datacollection and reporting the standard metrics we love because others love them because someone else said they were nice so many years ago. Remember that the raw number is not the only important part, we would also measure statistical significance. Online, offline or nonline. The result?
Part of it is fueled by a vocal minority genuinely upset that 10 years on we are still not a statistically powered bunch doing complicated analysis that is shifting paradigms. Having two tools guarantees you are going to be datacollection, data processing and data reconciliation organization. Likely not.
The lens of reductionism and an overemphasis on engineering becomes an Achilles heel for data science work. Instead, consider a “full stack” tracing from the point of datacollection all the way out through inference. Use of influence functions goes back to the 1970s in robust statistics. That seems much more robust.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. The biggest time sink is often around datacollection, labeling and cleaning.
Buy Experimentation findings The following table shows Sharpe Ratios for various holding periods and two different trade entry points: announcement and effective dates. By using a scalable Amazon EMR on Amazon EKS stack, researchers can easily handle the entire investment research lifecycle, from datacollection to backtesting.
Experimentation & Testing (A/B, Multivariate, you name it). If you have no experience with Web Analytics then you'll learn what it is and the nitty gritty of datacollection and core metrics such as Visits and Time on Site and Bounce Rate and Top Destinations etc. It is a book about Web Analytics 2.0.
As data science work is experimental and probabilistic in nature, data scientists are often faced with making inferences. What you’re seeing is a general rule: when two variables share a common cause, they will be correlated (or, more generally, statistically dependent) even when there’s no causal relationship between them.
In this article, I will discuss the construction of the AIgent, from datacollection to model assembly. DataCollection The AIgent leverages book synopses and book metadata. The latter is any type of external data that has been attached to a book? Instead, I built the AIgent. features) and metadata (i.e.
1]" Statistics, as a discipline, was largely developed in a small data world. Data was expensive to gather, and therefore decisions to collectdata were generally well-considered. As computing and storage have made datacollection cheaper and easier, we now gather data without this underlying motivation.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content