This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Product Managers are responsible for the successful development, testing, release, and adoption of a product, and for leading the team that implements those milestones. Without clarity in metrics, it’s impossible to do meaningful experimentation. Ongoing monitoring of critical metrics is yet another form of experimentation.
AI PMs should enter feature development and experimentation phases only after deciding what problem they want to solve as precisely as possible, and placing the problem into one of these categories. Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model.
The model outputs produced by the same code will vary with changes to things like the size of the training data (number of labeled examples), network training parameters, and training run time. This has serious implications for software testing, versioning, deployment, and other core development processes.
Pete indicates, in both his November 2018 and Strata London talks, that ML requires a more experimental approach than traditional software engineering. It is more experimental because it is “an approach that involves learning from data instead of programmatically following a set of human rules.”
We are far too enamored with datacollection and reporting the standard metrics we love because others love them because someone else said they were nice so many years ago. Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Testing out a new feature.
Collecting Relevant Data for Conversion Rate Optimization Here is some vital data that e-commerce businesses need to collect to improve their conversion rates. Identifying Key Metrics for Conversion Rate Optimization Datacollection and analysis are both essential processes for optimizing your conversion rate.
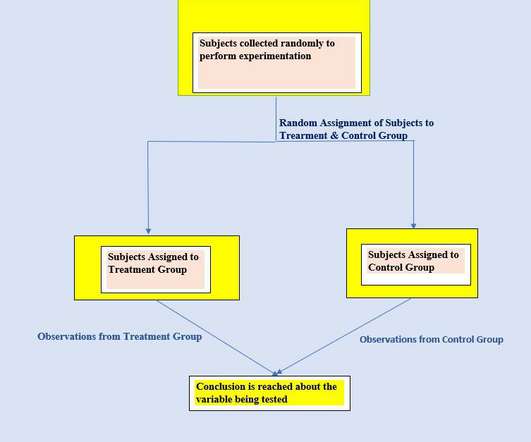
Researchers/ scientists perform experiments to validate their hypothesis/ statements or to test a new product. Bias ( syatematic unfairness in datacollection ) can be a potential problem in experiments and we need to take it into account while designing experiments. We randomly recruit subjects for that.
If you can show ROI on a DW it would be a good use of your money to go with Omniture Discover, WebTrends Data Mart, Coremetrics Explore. If you have evolved to a stage that you need behavior targeting then get Omniture Test and Target or Sitespect. Move from a datacollection obsession and develop a crush on data analysys.
Having two tools guarantees you are going to be datacollection, data processing and data reconciliation organization. If you blog that a short on-exit survey or a feedback button is a great way to collect voice of customer, I don't have to be lazy or hyper paranoid and wait for a convincing case study.
In this conversation with Foundry, Mitali discusses the accelerated importance of technology in healthcare, on enabling healthcare providers with data and why her team isn’t afraid of experimentation. The need is for a user-friendly system that captures all the data. Can you tell me about your career path so far?
This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The first blog introduced a mock vehicle manufacturing company, The Electric Car Company (ECC) and focused on DataCollection.
It surpasses blockchain and metaverse projects, which are viewed as experimental or in the pilot stage, especially by established enterprises. Big Datacollection at scale is increasing across industries, presenting opportunities for companies to develop AI models and leverage insights from that data.
But today, Svevia is driving cross-sector digitization projects where new technology for increased safety for road workers and users is tested. Taking out the trash Division Drift has been key to disruptively digitize Svevia’s remit with the help of the internet of things (IoT), datacollection, and data analysis.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Yet, this challenge is not insurmountable. for what is and isn’t possible) to address these challenges. Transcript.
Look – ahead bias – This is a common challenge in backtesting, which occurs when future information is inadvertently included in historical data used to test a trading strategy, leading to overly optimistic results. To comply with licensing considerations, we cannot provide a sample of the ETF constituents data.
In the science world, if you have a small group of people and do not find statistical significance, one thing you can do is test a much bigger group! Using scientific methods to test hypotheses (which are what statistics test) are what scientists do; delivering programming and tracking client progress is what nonprofit practitioners do.
Remember none of these jobs will do any datacollection/IT work, even in medium-sized companies.) But if their primary output is just data, and not actions to take expressed in English or verbally in weekly senior staff meeting, then they are simply Reporting Squirrels. Usability testing (lab based or online).
The lens of reductionism and an overemphasis on engineering becomes an Achilles heel for data science work. Instead, consider a “full stack” tracing from the point of datacollection all the way out through inference. Keep in mind that data science is fundamentally interdisciplinary. Let’s look through some antidotes.
I previously posted about my experiences with RLS offline datacollection and visualisation of the collecteddata , and have since helped with quite a few RLS surveys. My main "day job" focus in 2020 was on being the tech lead for Automattic’s new experimentation platform (ExPlat).
Most email programs now have preview panes that typically block images and scripts (Outlook, Thunderbird, Gmail, everyone), and default settings prevent datacollection due to concerns about viruses. This should drive aggressive experimentation of email content / offers / targeting / every facet by your team. That is okay.
In this post we will look mobile sites first, both datacollection and analysis, and then mobile applications. Media-Mix Modeling/Experimentation. Media-Mix Modeling/Experimentation. Then approach each separately (even though there are tools like Google Analytics that will do both). Tag your mobile website.
If you want to make the smartest decisions about your budget allocation then leveraging the time tested methodology of media mix modeling (at its core powered by controlled experiments) is the only way to go. The decentralized teams understand the difference between reporting and analysis , and simply focus on fast, hyper-relevant analysis!
We can think of model lineage as the specific combination of data and transformations on that data that create a model. This maps to the datacollection, data engineering, model tuning and model training stages of the data science lifecycle. So, we have workspaces, projects and sessions in that order.
We sometimes refer to this as splitting “dev/test” from “production” workloads, but we can generalize the approach by referring to the overall priority of the workload for the business. 3) By workload priority. A third strategy splits clusters based on the overall priority of the workloads running on those clusters.
However, hand-coding, testing, evaluating and deploying highly accurate models is a tedious and time-consuming process. Manually scaling out this process to thousands of stores or SKUs at once and then monitoring them, for example, is a nightmarish experience for data scientists. Improved Productivity.
For companies with small datasets and a mandate to move beyond experimentation, Frugal AI promises to be a way to overcome this challenge. Storage infrastructure and datacollection/processing costs. Frugal by Design: Why Focus on the Data and Not the Code? Today, in 2022, the code (i.e.,
Experimentation & Testing (A/B, Multivariate, you name it). What ideas to test first on your site? If you have no experience with Web Analytics then you'll learn what it is and the nitty gritty of datacollection and core metrics such as Visits and Time on Site and Bounce Rate and Top Destinations etc.
This article covers causal relationships and includes a chapter excerpt from the book Machine Learning in Production: Developing and Optimizing Data Science Workflows and Applications by Andrew Kelleher and Adam Kelleher. As data science work is experimental and probabilistic in nature, data scientists are often faced with making inferences.
PS: The phrase "real-time data analysis" is an oxymoron. Real-time data is super valuable if zero human beings are involved from datacollection to action being taken. Eight Silly Data Things Marketing People Believe That Get Them Fired. PPS: I've mentioned one exception in the past.
In this article, I will discuss the construction of the AIgent, from datacollection to model assembly. DataCollection The AIgent leverages book synopses and book metadata. The latter is any type of external data that has been attached to a book? On my test set, this approach resulted in~75–95% accuracy and ~.65
By articulating fitness functions automated tests tied to specific quality attributes like reliability, security or performance teams can visualize and measure system qualities that align with business goals. Experimentation: The innovation zone Progressive cities designate innovation districts where new ideas can be tested safely.
The companies that are most successful at marketing in both B2C and B2B are using data and online BI tools to craft hyper-specific campaigns that reach out to targeted prospects with a curated message. Everything is being tested, and then the campaigns that succeed get more money put into them, while the others aren’t repeated.
1]" Statistics, as a discipline, was largely developed in a small data world. Implicitly, there was a prior belief about some interesting causal mechanism or an underlying hypothesis motivating the collection of the data. We must correct for multiple hypothesis tests. We ought not dredge our data.
Companies need to focus on goals, testing, and people in their effort to determine if an AI project is viable. This helps test assumptions, gather valuable insights, and refine the solution before full deployment. Kalpala also suggests testing the AI solution through a pilot program in real-world business environments.
The tiny downside of this is that our parents likely never had to invest as much in constant education, experimentation and self-driven investment in core skills. When you go to the interview, the hiring company will proceed to ask questions that test your competency in the listed job requirements. This is normal.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content