This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Are you looking to build scalable and effective machinelearning solutions? AWS offers a comprehensive suite of services designed to simplify every step of the ML lifecycle, from datacollection to model monitoring.
Handling missing data is one of the most common challenges in data analysis and machinelearning. Missing values can arise for various reasons, such as errors in datacollection, manual omissions, or even the natural absence of information.
The future of business strategy will not be decided by intuition alone, but by the integration of fast-learning systems that reshape what decision-making looks like. For more information, look over the accompanying infographic. Founder of Catalyst For Business and contributor to search giants like Yahoo Finance, MSN. Followers Like 33.7k
AI and machinelearning models that analyze data and simulate scenarios to predict future behaviors and outcomes. Tools and interfaces that present the data and insights from the digital twin in an understandable format. Datacollection and integration The cornerstone of digital twin architecture is data.
Data architecture components A modern data architecture consists of the following components, according to IT consulting firm BMC : Data pipelines. A data pipeline is the process in which data is collected, moved, and refined. It includes datacollection, refinement, storage, analysis, and delivery.
Common data management practices are too slow, structured, and rigid for AI where data cleaning needs to be context-specific and tailored to the particular use case. For AI, there’s no universal standard for when data is ‘clean enough.’ One person’s trash is another person’s treasure,” as Swaminathan puts it.
SmartData Collective > Exclusive > How CIS Credentials Can Launch Your AI Development Career Exclusive News How CIS Credentials Can Launch Your AI Development Career CIS graduates have a strong foundation to build successful careers in artificial intelligence. You can then move on to supervised and unsupervised learning techniques.
Queue Hub, begun in earnest in July 2023, was created using machinelearning (ML) algorithms, open-source object detection algorithms, and custom AI models. The homegrown platform, now fully operational, runs on AWS and is enhanced continuously, Kundu says. “It
The problem of data silos, where a customer's data is stored across several dis connected systems, hinder the building of a unified view of the customer. These technologies can analyze data to process and provide important features at an exceptional pace. Customers expect to receive instant responses from businesses.
By leveraging machinelearning algorithms, businesses can predict customer needs with remarkable accuracy, tailoring interactions to create a more personalized journey that resonates on an emotional level. Moreover, embracing the future of CX means prioritizing transparency and ethical considerations in AI deployment.
Managed Prometheus allows for real-time high-volume datacollection, which scales the ingestion, storage, and querying of operational metrics as workloads increase or decrease. She manages Big Data Operations which includes managing petabyte-scale data and complex workloads processing in cloud.
Webinars stand out among these options for their comprehensive AI integration potential, offering unique advantages in datacollection, real-time optimization, and relationship building that complement other digital initiatives.
Teams are able to receive up-to-date data and dashboards in real time and take quick actions based on market changes and customer behavior. DataOps makes all processes easier, starting from datacollection to decision-making. Enhanced Data Quality and Governance Poor data is one of the biggest hurdles for activation processes.
The data retention issue is a big challenge because internally collecteddata drives many AI initiatives, Klingbeil says. With updated datacollection capabilities, companies could find a treasure trove of data that their AI projects could feed on. of their IT budgets on tech debt at that time.
Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. Companies can enrich these versatile tools with their own data using the RAG (retrieval-augmented generation) architecture.
If followed right, more data can be used in the apps and AI solutions that are built as new data comes in, says Francesco Marzoni, chief data and analytics officer at Ingka, the holding company that runs most of Ikeas department stores. By analyzing this data, their AI competence increases, he says.
They also have a massive proxy network (over 170 million residential IPs) and a handy AI assistant called OxyCopilot that helps automate datacollection without any code. They now offer APIs that take care of the full datacollection process, so you don’t have to worry about blocks or bans.
Project managers in the data business were independently designing and building data infrastructure, resulting in duplication of components for datacollection, processing, and storage.
Alexandra Bohigian 15 Min Read AI-Generated Image from Google Labs SHARE Since we took over Smart DataCollective, we’ve made it a priority to focus on how artificial intelligence influences the practical side of data mining. The bottom line? Followers Like 33.7k Followers Like 33.7k
Recently, SAP has released various applications that generate high-quality business data, and implementing trustworthy AI based on this is a key strategy,” said Irfan Khan, president and chief product officer of SAP Data and Analytics, at a press conference held in Seoul on July 15.
SmartData Collective > Big Data > Stopping Lateral Movement in a Data-Heavy, Edge-First World Big Data Exclusive Stopping Lateral Movement in a Data-Heavy, Edge-First World Cybersecurity challenges are growing rapidly as big data and AI reshape the digital threat environment. Followers Like 33.7k
AI and MachineLearning will drive innovation across the government, healthcare, and banking/financial services sectors, strongly focusing on generative AI and ethical regulation. Data sovereignty and local cloud infrastructure will remain priorities, supported by national cloud strategies, particularly in the GCC.
Personalized Recommendations : Leveraging AI and machinelearning, it can analyse user preferences, past behaviour, and travel history to offer personalized suggestions. DataCollection and Insights : These chatbots collect valuable data on customer preferences, behaviour, and feedback.
Generative AI and embedded machinelearning capabilities now offer substantial value in everyday business scenarios. The real-time datacollected from IoT sensors is no longer a secondary input; it has become vital for enabling smarter, faster and more resilient operations.
Ive spent more than 25 years working with machinelearning and automation technology, and agentic AI is clearly a difficult problem to solve. Document verification, for instance, might seem straightforward, but it involves multiple steps, including image capture and datacollection, behind the scenes.
Modern AI models, particularly large language models, frequently require real-time data processing capabilities. The machinelearning models would target and solve for one use case, but Gen AI has the capability to learn and address multiple use cases at scale.
This approach supports real-time datacollection and analysis, ultimately enhancing decision-making. As AI and machinelearning technologies mature, containerized MES/MOM systems will enable predictive maintenance, quality control, and supply chain optimization.
But that doesnt mask the fact that AI models rely on large amounts of data. The patterns and interdependencies that machinelearning (ML) algorithms identify and apply form the basis of their use case. Maintain detailed and transparent records of data sources, collection methods, and preprocessing techniques.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machinelearning (ML) to software development, which included a tour through sample tools in data science and for managing data infrastructure.
As the data community begins to deploy more machinelearning (ML) models, I wanted to review some important considerations. We recently conducted a survey which garnered more than 11,000 respondents—our main goal was to ascertain how enterprises were using machinelearning. Privacy and security.
They make use of some of the robust machinelearning and artificial intelligence algorithms to help flexible modelling, predictive analytics, seamless integrations, etc. However, these tools are more of data aggregation and datacollection solutions than effective planning aids.
This article was published as a part of the Data Science Blogathon. Introduction In order to build machinelearning models that are highly generalizable to a wide range of test conditions, training models with high-quality data is essential.
Introduction The advent of the internet and the potential for mass quantitative and qualitative datacollection altered the desire for and potential for measuring processes other than those in human resources.
Here at Smart DataCollective, we have talked about major changes that machinelearning has created in the financial industry. The evolution of smart cards is one of the newest ways that machinelearning and AI are impacting the future of finance. How MachineLearning is Changing the Future of Smart Cards.
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and datacollected incorrectly, more of which we’ll address below. The model and the data specification become more important than the code.
Specifically, in the modern era of massive datacollections and exploding content repositories, we can no longer simply rely on keyword searches to be sufficient. Labeling, indexing, ease of discovery, and ease of access are essential if end-users are to find and benefit from the collection.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machinelearning (ML). AI products are automated systems that collect and learn from data to make user-facing decisions. Machinelearning adds uncertainty.
Toloka is a crowdsourced data labeling platform that handles datacollection and annotation projects for machinelearning at any scale. In this Nov 11 Live Demo, Learn how to get reliable training data for machinelearning.
MachineLearning Projects are Hard: Shifting from a Deterministic Process to a Probabilistic One. Over the years, I have listened to data scientists and machinelearning (ML) researchers relay various pain points and challenges that impede their work. Product Management for MachineLearning.
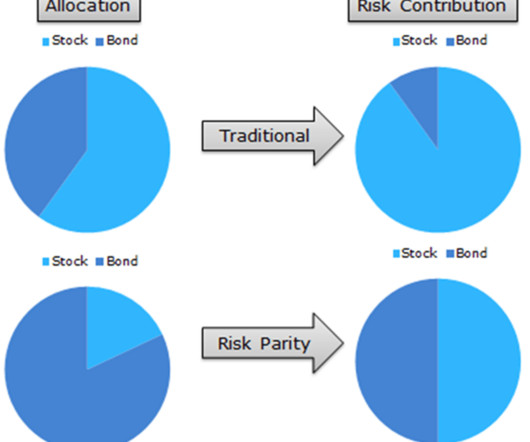
Here at Smart DataCollective, we have blogged extensively about the changes brought on by AI technology. Machinelearning technology has already had a huge impact on our lives in many ways. There are numerous ways that machinelearning technology is changing the financial industry. What is risk parity?
Roughly a year ago, we wrote “ What machinelearning means for software development.” Karpathy suggests something radically different: with machinelearning, we can stop thinking of programming as writing a step of instructions in a programming language like C or Java or Python. Instead, we can program by example.
From delightful consumer experiences to attacking fuel costs and carbon emissions in the global supply chain, real-time data and machinelearning (ML) work together to power apps that change industries. more machinelearning use casesacross the company. By Bryan Kirschner, Vice President, Strategy at DataStax.
One study found that 53% of marketers plan to use machinelearning in some capacity. At Smart DataCollective, we have discussed many of the ways that AI and machinelearning have changed the face of performance marketing. Machinelearning is changing the way that companies position their brand image.
2) MLOps became the expected norm in machinelearning and data science projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content