This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Handling missing data is one of the most common challenges in data analysis and machinelearning. Missing values can arise for various reasons, such as errors in datacollection, manual omissions, or even the natural absence of information.
Generative AI and embedded machinelearning capabilities now offer substantial value in everyday business scenarios. In sales forecasting, AI can identify nuanced patterns and create predictivemodels that far exceed traditional methods.
If you are planning on using predictive algorithms, such as machinelearning or data mining, in your business, then you should be aware that the amount of datacollected can grow exponentially over time.
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and datacollected incorrectly, more of which we’ll address below. The model and the data specification become more important than the code.
2) MLOps became the expected norm in machinelearning and data science projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase.
From delightful consumer experiences to attacking fuel costs and carbon emissions in the global supply chain, real-time data and machinelearning (ML) work together to power apps that change industries. more machinelearning use casesacross the company. By Bryan Kirschner, Vice President, Strategy at DataStax.
Machinelearning solutions for data integration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Models are increasingly becoming commodities. Software 2.0
In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. In this article, we explore model governance, a function of ML Operations (MLOps). MachineLearningModel Lineage. MachineLearningModel Visibility .
Beyond the early days of datacollection, where data was acquired primarily to measure what had happened (descriptive) or why something is happening (diagnostic), datacollection now drives predictivemodels (forecasting the future) and prescriptive models (optimizing for “a better future”).
Predictive analytics definition Predictive analytics is a category of data analytics aimed at making predictions about future outcomes based on historical data and analytics techniques such as statistical modeling and machinelearning.
Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, data transformation, datamodeling, and more. Whereas BI studies historical data to guide business decision-making, business analytics is about looking forward. This is the purview of BI.
The data science path you ultimately choose will depend on your skillset and interests, but each career path will require some level of programming, data visualization, statistics, and machinelearning knowledge and skills. Top 15 data science bootcamps. Data Science Dojo. Data Science Dojo.
Data science is a method for gleaning insights from structured and unstructured data using approaches ranging from statistical analysis to machinelearning. Data science gives the datacollected by an organization a purpose. Data science vs. data analytics.
As organizations start getting back to normal after the COVID-19 pandemic, AI and machinelearning is top of mind for many of these leaders. Now this market is looking at embedding AI and machinelearning together with automations to drive more end-to-end solutions and tackle those potential use cases that were once thought impossible.
Smart cities in the age of AI harness AI’s ability to analyze vast data streams, enabling intelligent decision-making and efficient resource management. Raw datacollected through IoT devices and networks serves as the foundation for urban intelligence. Then there are advanced connectivity solutions.
It not only increases the speed and transparency of decisions and their quality, but it is also the foundation for the use of predictive planning and forecasting powered by statistical methods and machinelearning. Faster information, digital change and data quality are the greatest challenges.
For data, this refinement includes doing some cleaning and manipulations that provide a better understanding of the information that we are dealing with. In a previous blog , we have covered how Pandas Profiling can supercharge the data exploration required to bring our data into a predictivemodelling phase.
They used the datacollected to build a logistic-regression and unsupervised learningmodels, so as to determine the potential relationship between drivers and outcomes. All this data is then used to set pricing fees, meet demand, and ensure an excellent service for both their drivers and clients.
These support a wide array of uses, such as data analysis, manipulation, visualizations, and machinelearning (ML) modeling. Some standard Python libraries are Pandas, Numpy, Scikit-Learn, SciPy, and Matplotlib. These libraries are used for datacollection, analysis, data mining, visualizations, and ML modeling.
Though you may encounter the terms “data science” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
Producing insights from raw data is a time-consuming process. Predictivemodeling efforts rely on dataset profiles , whether consisting of summary statistics or descriptive charts. Results become the basis for understanding the solution space (or, ‘the realm of the possible’) for a given modeling task.
So what is data wrangling? Let’s imagine the process of building a data lake. Let’s further pretend you’re starting out with the aim of doing a big predictivemodeling thing using machinelearning. First off, data wrangling is gathering the appropriate data. I hope you enjoy that sort of thing.
The newly launched IBM Security QRadar Suite offers AI, machinelearning (ML) and automation capabilities across its integrated threat detection and response portfolio , which includes EDR , log management and observability, SIEM and SOAR. The ML app helps your system to learn the expected behavior of the users in your network.
As part of the hackathon, the IT team sought to achieve three things: to aggregate the company’s data into an enterprise data platform; to build an API that would provide business access to that data; and to develop a machinelearning algorithm to provide insights on top of the aggregated IoT data.
Artificial intelligence (AI) can help improve the response rate on your coupon offers by letting you consider the unique characteristics and wide array of datacollected online and offline of each customer and presenting them with the most attractive offers. Training and Testing Different AI Models. Automate Feature Engineering.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machinelearningmodels, and data mining techniques to derive pertinent qualitative information from unstructured text data.
One of the biggest challenges of automation (Robotic Process Automation) and artificial intelligence/machinelearning technologies is our current mindset. AI-based machinelearning and predictive analytics will start to give us more powerful crystal balls. Once cleansed, its possible to enrich the data.
As firms mature their transformation efforts, applying Artificial Intelligence (AI), machinelearning (ML) and Natural Language Processing (NLP) to the data is key to putting it into action quickly and effecitvely. Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029.
Predictive maintenance constantly assesses and re-assesses an asset’s condition in real-time via sensors that collectdata via IoT. That data is then fed into AI-enabled CMMS, where advanced data analysis tools and processes like machinelearning (ML) spot issues and help resolve them.
As firms mature their transformation efforts, applying Artificial Intelligence (AI), machinelearning (ML) and Natural Language Processing (NLP) to the data is key to putting it into action quickly and effecitvely. Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029.
As Domino is committed to supporting data scientists and accelerating research, we reached out to Addison-Wesley Professional (AWP) Pearson for the appropriate permissions to excerpt “Predicting Social-Media Influence in the NBA” from the book, Pragmatic AI: An Introduction to Cloud-Based MachineLearning by Noah Gift.
In this article we cover explainability for black-box models and show how to use different methods from the Skater framework to provide insights into the inner workings of a simple credit scoring neural network model. The interest in interpretation of machinelearning has been rapidly accelerating in the last decade.
Using machinelearning (ML), AI can understand what customers are saying as well as their tone—and can direct them to customer service agents when needed. These systems can evaluate vast amounts of data to uncover trends and patterns, and to make decisions.
At Innocens BV, the belief is that earlier identification of sepsis-related events in newborns is possible, especially given the vast amount of data points collected from the moment a baby is born. Years’ worth of aggregated data in the NICU could help lead us to a solution.
For example, migrating customer data from an on-premises database to a cloud-based CRM system. MachineLearning Pipelines : These pipelines support the entire lifecycle of a machinelearningmodel, including data ingestion , data preprocessing, model training, evaluation, and deployment.
Let’s just give our customers access to the data. You’ve settled for becoming a datacollection tool rather than adding value to your product. While data exports may satisfy a portion of your customers, there will be many who simply want reports and insights that are available “out of the box.”
Many thanks to AWP Pearson for the permission to excerpt “Manual Feature Engineering: Manipulating Data for Fun and Profit” from the book, MachineLearning with Python for Everyone by Mark E. Missing values can be filled in based on expert knowledge, heuristics, or by some machinelearning techniques.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









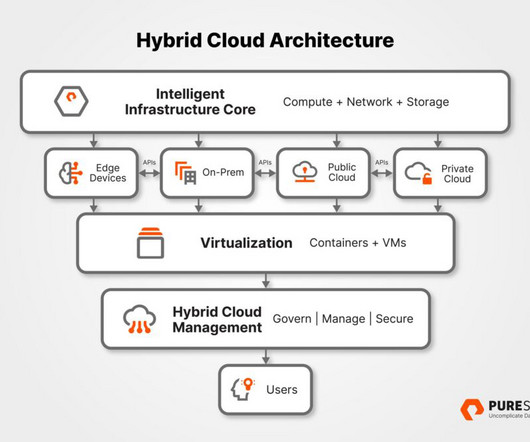






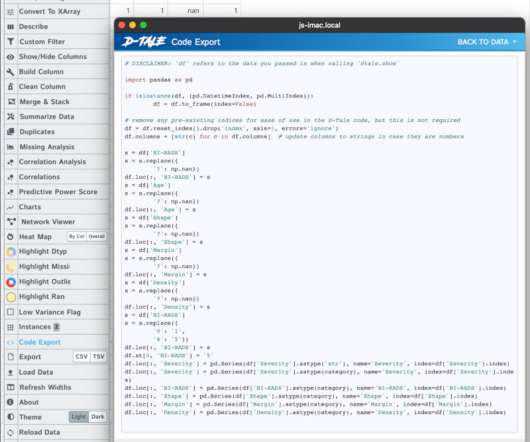






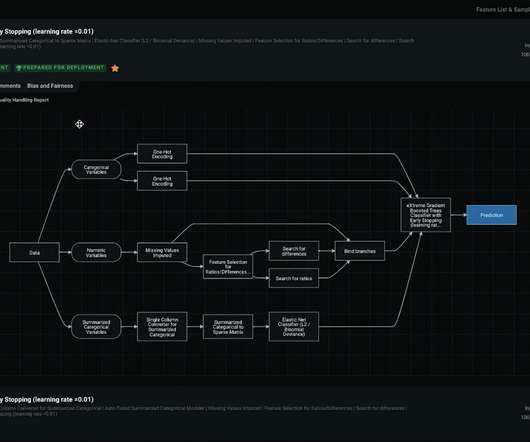




















Let's personalize your content