This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and datacollected incorrectly, more of which we’ll address below. The model and the data specification become more important than the code.
The good news is that researchers from academia recently managed to leverage that large body of work and combine it with the power of scalable statistical inference for data cleaning. HoloClean adopts the well-known “noisy channel” model to explain how data was generated and how it was “polluted.”
Business analytics is the practical application of statistical analysis and technologies on business data to identify and anticipate trends and predict business outcomes. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, data transformation, datamodeling, and more.
Predictive analytics definition Predictive analytics is a category of data analytics aimed at making predictions about future outcomes based on historical data and analytics techniques such as statisticalmodeling and machine learning. from 2022 to 2028.
Data science is a method for gleaning insights from structured and unstructured data using approaches ranging from statistical analysis to machine learning. Data science gives the datacollected by an organization a purpose. Data science vs. data analytics.
There are four main types of data analytics: Predictivedata analytics: It is used to identify various trends, causation, and correlations. It can be further classified as statistical and predictivemodeling, but the two are closely associated with each other.
An education in data science can help you land a job as a data analyst , data engineer , data architect , or data scientist. It’s a fast growing and lucrative career path, with data scientists reporting an average salary of $122,550 per year , according to Glassdoor. Top 15 data science bootcamps.
Producing insights from raw data is a time-consuming process. Predictivemodeling efforts rely on dataset profiles , whether consisting of summary statistics or descriptive charts. The Importance of Exploratory Analytics in the Data Science Lifecycle. imputation of missing values). There is no clear end state.
It not only increases the speed and transparency of decisions and their quality, but it is also the foundation for the use of predictive planning and forecasting powered by statistical methods and machine learning. Faster information, digital change and data quality are the greatest challenges.
Though you may encounter the terms “data science” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
For data, this refinement includes doing some cleaning and manipulations that provide a better understanding of the information that we are dealing with. In a previous blog , we have covered how Pandas Profiling can supercharge the data exploration required to bring our data into a predictivemodelling phase.
R is a tool built by statisticians mainly for mathematics, statistics, research, and data analysis. These visualizations are useful for helping people visualize and understand trends , outliers, and patterns in data. These libraries are used for datacollection, analysis, data mining, visualizations, and ML modeling.
So what is data wrangling? Let’s imagine the process of building a data lake. Let’s further pretend you’re starting out with the aim of doing a big predictivemodeling thing using machine learning. First off, data wrangling is gathering the appropriate data. I hope you enjoy that sort of thing.
Artificial intelligence (AI) can help improve the response rate on your coupon offers by letting you consider the unique characteristics and wide array of datacollected online and offline of each customer and presenting them with the most attractive offers. Training and Testing Different AI Models.
As a result, there has been a recent explosion in individual statistics that try to measure a player’s impact. In the real world, things are never this easy, and it is a battle to get the data into the correct shape as we will see later in this chapter. 05) in predicting changes in attendance. The R-squared value of.282
As firms mature their transformation efforts, applying Artificial Intelligence (AI), machine learning (ML) and Natural Language Processing (NLP) to the data is key to putting it into action quickly and effecitvely. Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029.
Real-world datasets can be missing values due to the difficulty of collecting complete datasets and because of errors in the datacollection process. Recentering the data means that we translate the values so that the extremes are different and the intermediate values are moved in some consistent way. Discretization.
As firms mature their transformation efforts, applying Artificial Intelligence (AI), machine learning (ML) and Natural Language Processing (NLP) to the data is key to putting it into action quickly and effecitvely. Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029.
From the moment of birth to discharge, healthcare professionals can collect so much data about an infant’s vitals—for instance, heartbeat frequency or every rise and drop in blood oxygen level. The worldwide statistics on premature births are staggering— the University of Oxford estimates that neonatal sepsis causes 2.5
Machine Learning Pipelines : These pipelines support the entire lifecycle of a machine learning model, including data ingestion , data preprocessing, model training, evaluation, and deployment. API Data Pipelines : These pipelines retrieve data from various APIs and load it into a database or application for further use.
Let’s just give our customers access to the data. You’ve settled for becoming a datacollection tool rather than adding value to your product. While data exports may satisfy a portion of your customers, there will be many who simply want reports and insights that are available “out of the box.”
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










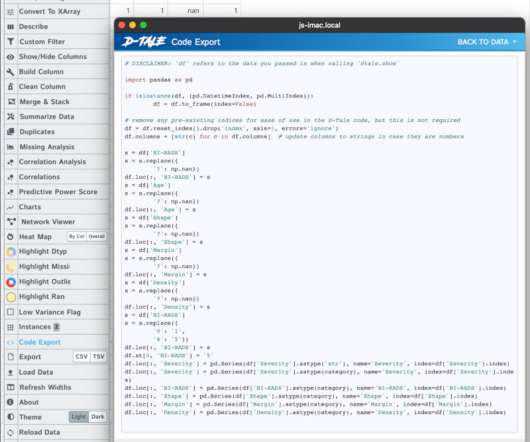


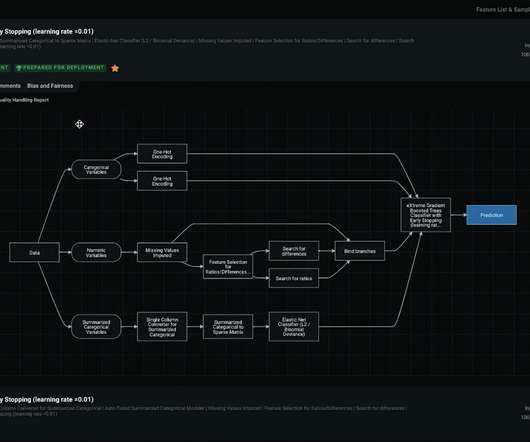















Let's personalize your content