This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction In order to build machine learning models that are highly generalizable to a wide range of test conditions, training models with high-quality data is essential.
The good news is that researchers from academia recently managed to leverage that large body of work and combine it with the power of scalable statistical inference for data cleaning. HoloClean adopts the well-known “noisy channel” model to explain how data was generated and how it was “polluted.”
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. After training, the system can make predictions (or deliver other results) based on data it hasn’t seen before. Machine learning adds uncertainty.
In these instances, data feeds come largely from various advertising channels, and the reports they generate are designed to help marketers spend wisely. Others aim simply to manage the collection and integration of data, leaving the analysis and presentation work to other tools that specialize in data science and statistics.
Predictive analytics definition Predictive analytics is a category of data analytics aimed at making predictions about future outcomes based on historical data and analytics techniques such as statistical modeling and machine learning. from 2022 to 2028. from 2022 to 2028.
The strategic decision-making in the future of business intelligence will be shaped by faster reports, deeper data insights, broader areas of datacollection. BI software will gauge internal data on performance, sales and marketing, social media and other sources to build actionable recommendations for your business.
What are the benefits of data management platforms? Modern, data-driven marketing teams must navigate a web of connected data sources and formats. Others aim simply to manage the collection and integration of data, leaving the analysis and presentation work to other tools that specialize in data science and statistics.
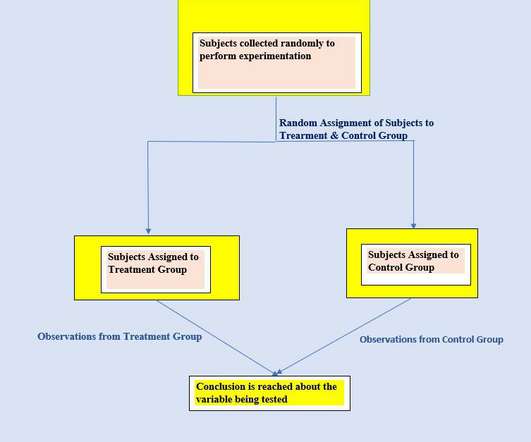
Bias ( syatematic unfairness in datacollection ) can be a potential problem in experiments and we need to take it into account while designing experiments. Statistics Essential for Dummies by D. Rumsey Statistical Reasoning Course by Stanford Ligunita Introduction to the Practice of Statistics by D. REFERENCES.
Data scientists usually build models for data-driven decisions asking challenging questions that only complex calculations can try to answer and creating new solutions where necessary. Programming and statistics are two fundamental technical skills for data analysts, as well as data wrangling and data visualization.
These toolbars also collect limited information about the browsing behavior of the customers who use them, including the pages visited, the search terms used, perhaps even time spent on each page, and so forth. Typically, datacollected is anonymous and not personally identifiable information (PII). 6: Self-reported Data.
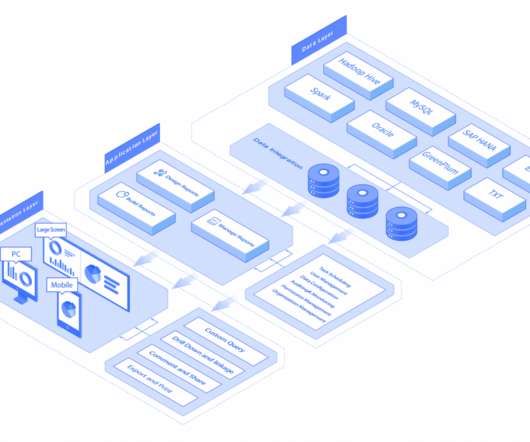
As illustrated above, a data catalog is essential to business users because it synthesizes all the details about an organization’s data assets across multiple data sources. It organizes them into a simple, easy- to-digest format and then publishes them to data communities for knowledge-sharing and collaboration.
So one of the biggest lessons we’re learning from COVID-19 is the need for datacollection, management and governance. What’s the best way to organize data and ensure it is supported by business policies and well-defined, governed systems, data elements and performance measures? Put border controls in place.
UMass Global has a very insightful article on the growing relevance of big data in business. Big data has been discussed by business leaders since the 1990s. The term was first published in 1999 and gained a solid definition in the early 2000s. It refers to datasets too large for normal statistical methods.
COVID-19 exposes shortcomings in data management. Getting consistency is also a daunting challenge in the face of a tsunami of data. Having a data-driven approach creates much sought after competitive advantage. To get consistent and reliable data, this is the kind of standardisation we need.
Then the reporting engine publishes these reports to the reporting portal to allow non-technical end-users access. In this way, users can gain insights from the data and make data-driven decisions. . The underlying data is responsible for data management, including datacollection, ETL, building a data warehouse, etc.
Every data professional knows that ensuring data quality is vital to producing usable query results. Streaming data can be extra challenging in this regard, as it tends to be “dirty,” with new fields that are added without warning and frequent mistakes in the datacollection process.
The lens of reductionism and an overemphasis on engineering becomes an Achilles heel for data science work. Instead, consider a “full stack” tracing from the point of datacollection all the way out through inference. Use of influence functions goes back to the 1970s in robust statistics. That seems much more robust.
4) How to Select Your KPIs 5) Avoid These KPI Mistakes 6) How To Choose A KPI Management Solution 7) KPI Management Examples Fact: 100% of statistics strategically placed at the top of blog posts are a direct result of people studying the dynamics of Key Performance Indicators, or KPIs. 3) What Are KPI Best Practices?
According to research completed by the University of Texas , increasing data usability by 10% would boost annual revenue for Fortune 1000 companies by more than $2 billion. The Case for Publishing Dirty Data Early Dont wait to publish your data. Which Comes First, Data Cleanse or CPM solution?
Long ago, I had majored in psychology so I could take as many research methods and statistics courses as possible. And learning how we learn–the courses on cognition, memory, perception, and brain biology–are critical in my everyday work as a data visualization designer and speaker.
2,3 When clinical trials are prematurely discontinued due to trial site underperformance, the research questions remain unanswered and research findings end up not published. AI algorithms have the potential to surpass traditional statistical approaches for analyzing comprehensive recruitment data and accurately forecasting enrollment rates.
I am thrilled to say that my book Web Analytics: An Hour A Day has been published and is now widely available. If you have no experience with Web Analytics then you'll learn what it is and the nitty gritty of datacollection and core metrics such as Visits and Time on Site and Bounce Rate and Top Destinations etc.
He was saying this doesn’t belong just in statistics. He also really informed a lot of the early thinking about data visualization. It involved a lot of interesting work on something new that was data management. To some extent, academia still struggles a lot with how to stick data science into some sort of discipline.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects.
Editor's note : The relationship between reliability and validity are somewhat analogous to that between the notions of statistical uncertainty and representational uncertainty introduced in an earlier post. Measurement challenges Assessing reliability is essentially a process of datacollection and analysis.
However, sometimes we may find some inconveniences in the process of datacollection and data visualization. For example, when making routine work analysis reports, we find it is inconvenient to re-summarize the latest data and recreate a new report, especially when the data is in a large volume.
I try to relate as much published research as I can in the time available to draft a response. – In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend. – In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend.
This month, the theme is not specifically about conference summaries; rather, it’s about a set of follow-up surveys from Strata Data attendees. We had big surprises at several turns and have subsequently published a series of reports. Evolving Data Infrastructure: Tools and Best Practices for Advanced Analytics and AI (Jan 2019).
Despite the possibilities for feedback loops and error propagation, we may end up needing AI to label data for other AI systems. We’ve also observed organizations claiming that data privacy concerns prevent datacollection that would enable bias testing. More are published all the time.
Due to this book being published recently, there are not any written reviews available. 4) Big Data: Principles and Best Practices Of Scalable Real-Time Data Systems by Nathan Marz and James Warren. and this book will give you an insight into their datacollecting procedures and the reasons behind them.
There was only one problem: literary agents, the gatekeepers of the publishing industry, kept rejecting the book?—?often Galbraith eventually opted to publish Cuckoo’s Calling through an acquaintance of sorts. but the publishing industry failed to see it. DataCollection The AIgent leverages book synopses and book metadata.
At Smart DataCollective, we strive to have a balanced conversation about the impact of big data. There are obviously a lot of beneficial changes that big data has spurred. However, big data has also created some important challenges as well, which we feel duty-bound to discuss.
1]" Statistics, as a discipline, was largely developed in a small data world. Data was expensive to gather, and therefore decisions to collectdata were generally well-considered. As computing and storage have made datacollection cheaper and easier, we now gather data without this underlying motivation.
Let’s just give our customers access to the data. You’ve settled for becoming a datacollection tool rather than adding value to your product. While data exports may satisfy a portion of your customers, there will be many who simply want reports and insights that are available “out of the box.”
Those without KPIs are left without any valuable statistics, while those with established performance tracking dashboards are able to make data driven decisions. Setting up an insightful university KPI system requires three main components: effective datacollection, an automated process, and realistic goals.
Data ingestion methods can include batch ingestion (collectingdata at scheduled intervals) or real-time streaming data ingestion (collectingdata continuously as it is generated). Technologies used for data ingestion include data connectors, ingestion frameworks, or datacollection agents.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content