This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction In order to build machine learning models that are highly generalizable to a wide range of test conditions, training models with high-quality data is essential. The post An Accurate Approach to Data Imputation appeared first on Analytics Vidhya.
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and datacollected incorrectly, more of which we’ll address below. The model and the data specification become more important than the code.
— Thank you to Ann Emery, Depict Data Studio, and her Simple Spreadsheets class for inviting us to talk to them about the use of statistics in nonprofit program evaluation! But then we realized that much of the time, statistics just don’t have much of a role in nonprofit work. Why Nonprofits Shouldn’t Use Statistics.
Qualitative data, as it is widely open to interpretation, must be “coded” so as to facilitate the grouping and labeling of data into identifiable themes. Quantitative analysis refers to a set of processes by which numerical data is analyzed. It is the sum of the values divided by the number of values within the data set.
Businesses already have a wealth of data but understanding your business will help you identify a data need – what kind of data your business needs to collect and if it collects too much or too little of certain data. Collecting too much data would be overwhelming and too little – inefficient.
As a direct result, less IT support is required to produce reports, trends, visualizations, and insights that facilitate the data decision making process. From these developments, data science was born (or at least, it evolved in a huge way) – a discipline where hacking skills and statistics meet niche expertise.
Business analytics is the practical application of statistical analysis and technologies on business data to identify and anticipate trends and predict business outcomes. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, data transformation, data modeling, and more.
When looked at this way, it’s largely a problem of mathematics and statistics. As organizations like Data For Black Lives , Black in AI , the Algorithmic Justice League , and others have been pointing out, it’s never just an issue of statistics. It’s an issue of harms and of power.
Undoubtedly, the cost of maintaining a fleet depends on many factors, but data helps you figure out what works best for your fleet here and now. According to statistics, fuel costs account for nearly 40% of overall expenses for a fleet. Data also helps in identifying improper routing that usually leads to excessive fuel consumption.
The Power of Data Analytics: An Overview Data analytics, in its simplest form, is the process of inspecting, cleansing, transforming, and modeling data to unearth useful information, draw conclusions, and support decision-making. In the realm of legal affairs, data analytics can serve as a strategic ally.
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. After training, the system can make predictions (or deliver other results) based on data it hasn’t seen before. Machine learning adds uncertainty.
Business intelligence analyst job requirements BI analysts typically handle analysis and data modeling design using datacollected in a centralized data warehouse or multiple databases throughout the organization.
There are four main types of data analytics: Predictive data analytics: It is used to identify various trends, causation, and correlations. It can be further classified as statistical and predictive modeling, but the two are closely associated with each other. They can be again classified as random testing and optimization.
They test the product and find bugs that turn customers away. Game analysts are exclusively engaged in testing and reporting, and the elimination of identified problems falls on the shoulders of the development team. After all, analytics is not just looking at statistics and reading player reviews.
The first step of the manager’s team was instead to hire a UX designer to not only design the interface and experience for the end user, but also carry out tests to bring qualitative and quantitative evidence on site and app performance to direct the business. “E-commerce The data is then re-transported when the line is available.
What is a data engineer? Data engineers design, build, and optimize systems for datacollection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers.
Gartner agrees that synthetic data can help solve the data availability problem for AI products, as well as privacy, compliance, and anonymization challenges. Starting from scratch with your own model, in fact, requires much more datacollection work and a lot of skills.
Researchers/ scientists perform experiments to validate their hypothesis/ statements or to test a new product. Bias ( syatematic unfairness in datacollection ) can be a potential problem in experiments and we need to take it into account while designing experiments. Statistics Essential for Dummies by D. REFERENCES.
An education in data science can help you land a job as a data analyst , data engineer , data architect , or data scientist. It’s a fast growing and lucrative career path, with data scientists reporting an average salary of $122,550 per year , according to Glassdoor. Top 15 data science bootcamps.
In these instances, data feeds come largely from various advertising channels, and the reports they generate are designed to help marketers spend wisely. Others aim simply to manage the collection and integration of data, leaving the analysis and presentation work to other tools that specialize in data science and statistics.
We are far too enamored with datacollection and reporting the standard metrics we love because others love them because someone else said they were nice so many years ago. Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Testing out a new feature.
At Smart DataCollective, we strive to have a balanced conversation about the impact of big data. There are obviously a lot of beneficial changes that big data has spurred. However, big data has also created some important challenges as well, which we feel duty-bound to discuss.
And once we cracked the code on that alternative reality and they saw that we weren’t just talking about running a test but continuous testing every step or instantiating a transit environment to recreate a test environment in seconds rather than days. Automate the datacollection and cleansing process.
4) How to Select Your KPIs 5) Avoid These KPI Mistakes 6) How To Choose A KPI Management Solution 7) KPI Management Examples Fact: 100% of statistics strategically placed at the top of blog posts are a direct result of people studying the dynamics of Key Performance Indicators, or KPIs. 3) What Are KPI Best Practices?
For example, they may not be easy to apply or simple to comprehend but thanks to bench scientists and mathematicians alike, companies now have a range of logistical frameworks for analyzing data and coming to conclusions. More importantly, we also have statistical models that draw error bars that delineate the limits of our analysis.
Data analyst —Data authors can’t create great art if they don’t like working with their materials. Data authors need to be comfortable with core statistical concepts and comfortable with manipulating data. Getting involved with deep data analysis can reveal the important messages and accurate ways to convey them.
What are the benefits of data management platforms? Modern, data-driven marketing teams must navigate a web of connected data sources and formats. Others aim simply to manage the collection and integration of data, leaving the analysis and presentation work to other tools that specialize in data science and statistics.
IBM Cloud Pak for Business Automation , for example, provides a low-code studio for testing and developing automation strategies. Power Advisor tracks statistics about performance to locate bottlenecks and other issues. Rocketbot Orquestador will manage them, running them as needed while compiling statistics.
The name references the Greek letter sigma, which is a statistical symbol that represents a standard deviation. Larger is Better involves a “lower specification limit,” such as test scores — where the target is 100%. During the improve phase, the focus is on testing the best potential solutions identified in the earlier phases.
These toolbars also collect limited information about the browsing behavior of the customers who use them, including the pages visited, the search terms used, perhaps even time spent on each page, and so forth. Typically, datacollected is anonymous and not personally identifiable information (PII). 6: Self-reported Data.
Generally, if the relative amount of data in a slice is the same across your two groups, you can safely make a comparison. Consider practical significance With a large volume of data, it can be tempting to focus solely on statistical significance or to hone in on the details of every bit of data.
Look – ahead bias – This is a common challenge in backtesting, which occurs when future information is inadvertently included in historical data used to test a trading strategy, leading to overly optimistic results. To comply with licensing considerations, we cannot provide a sample of the ETF constituents data.
Based on initial IBM Research evaluations and testing , across 11 different financial tasks, the results show that by training Granite-13B models with high-quality finance data, they are some of the top performing models on finance tasks, and have the potential to achieve either similar or even better performance than much larger models.
MLOps covers the full gamut from datacollection, verification, and analysis, all the way to managing machine resources and tracking model performance. Every statistic we look at, we’re at an inflection point of rapid scaling up for AI.”. There’s a lack of appreciation for what it takes.”. One hundred percent,” he says.
Unlike state-run health care systems in countries like South Korea and China, in most countries, each state or area manages that health data differently, creating disparate data sets, which increases the difficulty of statistics and allocate resources. Five DataCollection Forms. Download template.
MLOps covers the full gamut from datacollection, verification, and analysis, all the way to managing machine resources and tracking model performance. Every statistic we look at, we’re at an inflection point of rapid scaling up for AI.”. There’s a lack of appreciation for what it takes.”. One hundred percent,” he says.
For the modern digital organization, the proof of any inference (that drives decisions) should be in the data! Rich and diverse datacollections enable more accurate and trustworthy conclusions. lack of appetite; or other pains) and may order other medical tests (blood pressure checks, or other lab results).
Though you may encounter the terms “data science” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
Quantitative analysis can take two forms: the traditional business analysis of numerical data, or the more academic quantitative analysis. Traditional business analysis uses numerical methods to paint a picture, often through numerical methods, like statistics. What Is the Role of Statistics in Quantitative Data Analysis?
Plenty of analytics companies use synthetic data to analyze the performance of online applications and services. The main reason is cost: it takes a fair amount of resources in the form of compute and configurations to capture RUM data in real time. Synthetic data is a statistical representation of reality.
Real-world datasets can be missing values due to the difficulty of collecting complete datasets and because of errors in the datacollection process. The problem is that a new unique identifier of a test example won’t be anywhere in the tree. We proceed as usual and see what happens with our training and testing errors.
Data analysts contribute value to organizations by uncovering trends, patterns, and insights through data gathering, cleaning, and statistical analysis. They identify and interpret trends in complex datasets, optimize statistical results, and maintain databases while devising new datacollection processes.
As a result, Skomoroch advocates getting “designers and data scientists, machine learning folks together and using real data and prototyping and testing” as quickly as possible. As quickly as possible, you want to get designers and data scientists, machine learning folks together and using real data and prototyping and testing.
As data science work is experimental and probabilistic in nature, data scientists are often faced with making inferences. The case that might be familiar to you is an AB test. You can make a change to a product and test it against the original version of the product. Let’s continue with this example. size=N) y = 3. *
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






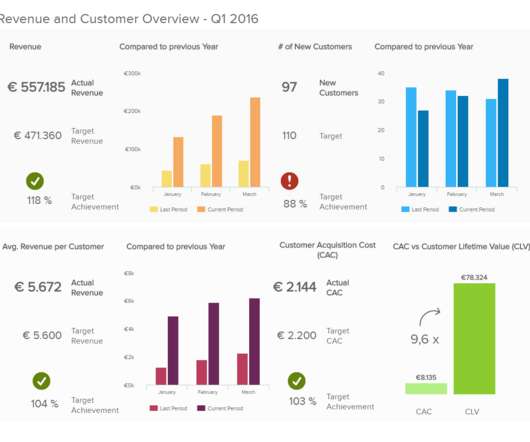











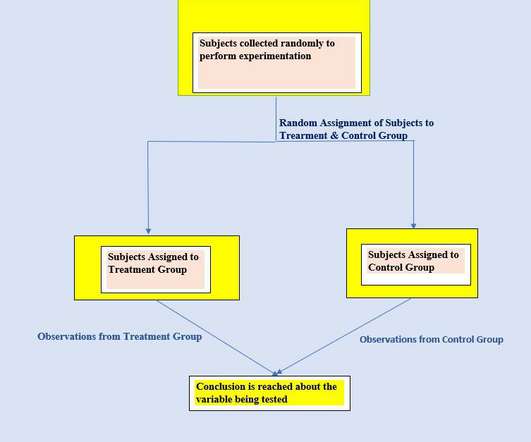







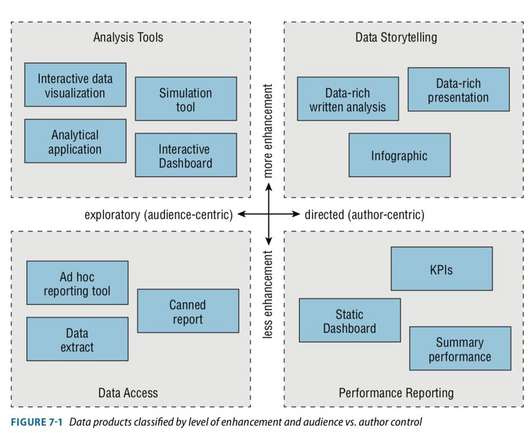








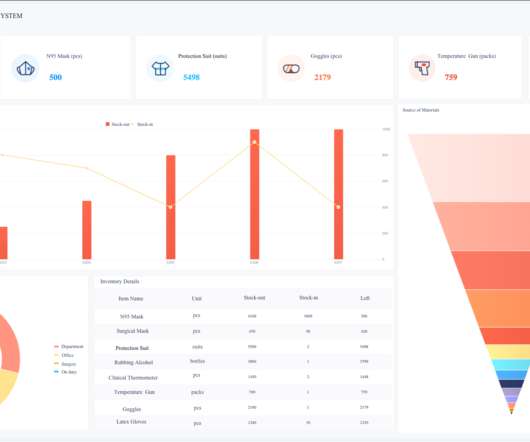
















Let's personalize your content