This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. Two big things: They bring the messiness of the real world into your system through unstructured data.
Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy. Those F’s are: Fragility, Friction, and FUD (Fear, Uncertainty, Doubt). These changes may include requirements drift, data drift, model drift, or concept drift.
AI products are automated systems that collect and learn from data to make user-facing decisions. All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. Machine learning adds uncertainty.
From a technical perspective, it is entirely possible for ML systems to function on wildly different data. For example, you can ask an ML model to make an inference on data taken from a distribution very different from what it was trained on—but that, of course, results in unpredictable and often undesired performance. I/O validation.
by AMIR NAJMI & MUKUND SUNDARARAJAN Data science is about decision making under uncertainty. Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature.
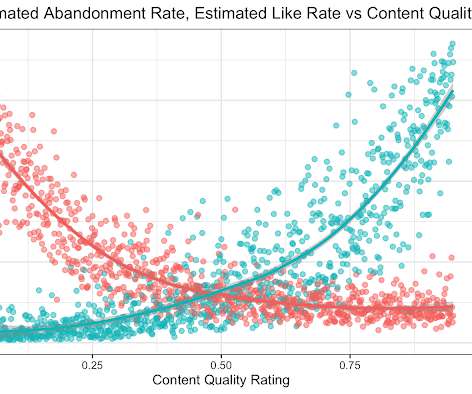
Crucially, it takes into account the uncertainty inherent in our experiments. Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well. The data showed us that metrics are not exactly straight-line functions of parameters.
Experiment with the “highly visible and highly hyped”: Gartner repeatedly pointed out that organisations that innovate during tough economic times “stay ahead of the pack”, with Mesaglio in particular calling for such experimentation to be public and visible.
It’s been a year filled with disruption and uncertainty. Businesses had to literally switch operations, and enable better collaboration and access to data in an instant — while streamlining processes to accommodate a whole new way of doing things. One day we were all going to the office, and the next we were working from home.
Our world today is experiencing an extremely social, connected, competitive and technology-driven business environment. If anything, the past few years have shown us the levels of uncertainty we are facing. Infosys Living Labs helps customers solve business problems with their emerging technology solutions and service offerings.
We are far too enamored with data collection and reporting the standard metrics we love because others love them because someone else said they were nice so many years ago. It helps you to amplify what’s proven to work, throw away what isn’t, and tweak the goal-posts when data indicates that they may be in the wrong place.
These circumstances have induced uncertainty across our entire business value chain,” says Venkat Gopalan, chief digital, data and technology officer, Belcorp. “As The R&D laboratories produced large volumes of unstructured data, which were stored in various formats, making it difficult to access and trace.
What are some of the unique data and cybersecurity challenges that Havmor faces as a vast customer-centric business? Data and cybersecurity issues challenge every IT leader. With cybersecurity and data protection, end-user awareness presents itself as a key challenge. We are working on similar projects for supply chain as well.
It’s around these four work streams that leading organizations are positioning themselves to mature their data strategies and, in doing so, answer not only today’s AI questions but tomorrow’s. So, if you, too, want to leverage AI to its fullest extent, you must first look in the mirror: Can I manage this growing volume of data?
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Without large amounts of labeled training data solving most AI problems is not possible.
Machine learning, artificial intelligence, data engineering, and architecture are driving the data space. The Strata Data Conferences helped chronicle the birth of big data, as well as the emergence of data science, streaming, and machine learning (ML) as disruptive phenomena. The term “AI,” meanwhile, is No.
You help companies adapt to a changing, tech-driven economy. Among several services my organization provides; we help individuals, enterprises, and public agencies plan, prepare, and manage through the uncertainty, demands, and challenges of the future. How quickly do companies need to become “data-driven”?
To allow or not According to various news reports, some big-name companies initially blocked generative AI tools such as ChatGPT for various reasons, including concerns about protecting proprietary data. 1 question now is to allow or not allow,” says Mir Kashifuddin, data risk and privacy leader with the professional services firm PwC US.
The shift in consumer habits and geopolitical crises have rendered data patterns collected pre-COVID obsolete. This has prompted AI/ML model owners to retrain their legacy models using data from the post-COVID era, while adapting to continually fluctuating market trends and thinking creatively about forecasting.
by NIALL CARDIN, OMKAR MURALIDHARAN, and AMIR NAJMI When working with complex systems or phenomena, the data scientist must often operate with incomplete and provisional understanding, even as she works to advance the state of knowledge. There has been debate as to whether the term “data science” is necessary. Some don’t see the point.
I have no doubt that as consumers, well soon enjoy new generative AI (genAI)-driven experiences that move the needle on delightfulness, efficiency, or both. And while its beyond the scope of this article, the applicable knowledge gained through our hands-on experimentation with genAI was head and shoulders above simple web searches (e.g.,
Without a strong IT culture, inspiring IT teams to extend beyond their “run the business” responsibilities into areas requiring collaboration between business colleagues, data scientists, and partners is challenging. When changes are made without transparency or input from the team, it breeds uncertainty and resentment.
Economic uncertainty, geopolitical instability, and the explosion of AI-driven initiatives mean that enterprise architects must redefine their roles to remain relevant and valuable. Mistake #4: Falling Behind in AI Strategy The Problem: Technology-driven growth, and AI in particular, is dominating the strategic agenda for CEOs in 2025.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content