This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
1) What Is Data Quality Management? 4) Data Quality Best Practices. 5) How Do You Measure Data Quality? 6) Data Quality Metrics Examples. 7) Data Quality Control: Use Case. 8) The Consequences Of Bad Data Quality. 9) 3 Sources Of Low-Quality Data. 10) Data Quality Solutions: Key Attributes.
Amazon Redshift is a fully managed, AI-powered cloud data warehouse that delivers the best price-performance for your analytics workloads at any scale. It provides a conversational interface where users can submit queries in natural language within the scope of their current data permissions. Your data is not shared across accounts.
In this post, we focus on data management implementation options such as accessing data directly in Amazon Simple Storage Service (Amazon S3), using popular data formats like Parquet, or using open table formats like Iceberg. Data management is the foundation of quantitative research.
This yields results with exact precision, dramatically improving the speed and accuracy of data discovery. In this post, we demonstrate how to streamline data discovery with precise technical identifier search in Amazon SageMaker Unified Studio.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses.
And yeah, the real-world relationships among the entities represented in the data had to be fudged a bit to fit in the counterintuitive model of tabular data, but, in trade, you get reliability and speed. Ironically, relational databases only imply relationships between data points by whatever row or column they exist in.
It’s time to consider data-driven enterprise architecture. The traditional approach to enterprise architecture – the analysis, design, planning and implementation of IT capabilities for the successful execution of enterprise strategy – seems to be missing something … data. That’s right. This is what we call the Mezzo.
Miso’s cofounders, Lucky Gunasekara and Andy Hsieh, are veterans of the Small Data Lab at Cornell Tech, which is devoted to private AI approaches for immersive personalization and content-centric explorations. The platform required a more effective way to connect learners directly to the key information that they sought.
Open table formats are emerging in the rapidly evolving domain of big data management, fundamentally altering the landscape of data storage and analysis. By providing a standardized framework for data representation, open table formats break down data silos, enhance data quality, and accelerate analytics at scale.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
Organization’s cannot hope to make the most out of a data-driven strategy, without at least some degree of metadata-driven automation. The volume and variety of data has snowballed, and so has its velocity. So it’s safe to say that organizations can’t reap the rewards of their data without automation.
I recently saw an informal online survey that asked users which types of data (tabular, text, images, or “other”) are being used in their organization’s analytics applications. The results showed that (among those surveyed) approximately 90% of enterprise analytics applications are being built on tabular data.
Data is the most significant asset of any organization. However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture.
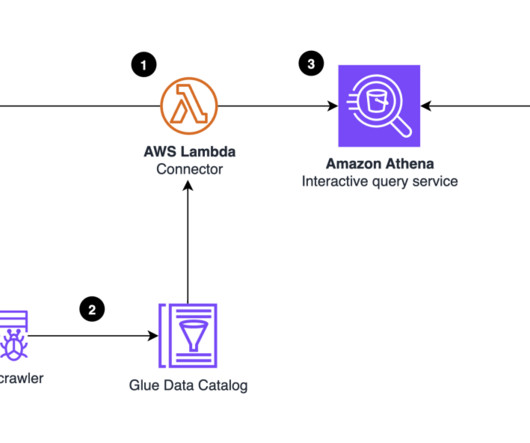
Amazon SageMaker Lakehouse now supports attribute-based access control (ABAC) with AWS Lake Formation , using AWS Identity and Access Management (IAM) principals and session tags to simplify data access, grant creation, and maintenance. You can then query, analyze, and join the data using Redshift, Amazon Athena , Amazon EMR , and AWS Glue.
Organizational data is often fragmented across multiple lines of business, leading to inconsistent and sometimes duplicate datasets. This fragmentation can delay decision-making and erode trust in available data. This solution enhances governance and simplifies access to unstructured data assets across the organization.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in data science and for managing data infrastructure.
If you’re serious about a data-driven strategy , you’re going to need a data catalog. Organizations need a data catalog because it enables them to create a seamless way for employees to access and consume data and business assets in an organized manner. Three Types of Metadata in a Data Catalog.
Q: Is data modeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. A: It always was and is getting cooler!!
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
Through a visual designer, you can configure custom AI search flowsa series of AI-drivendata enrichments performed during ingestion and search. Each processor applies a type of data transform such as encoding text into vector embeddings, or summarizing search results with a chatbot AI service.
AI products are automated systems that collect and learn from data to make user-facing decisions. All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. Why AI software development is different.
In today’s data-driven landscape, Data and Analytics Teams i ncreasingly face a unique set of challenges presented by Demanding Data Consumers who require a personalized level of Data Observability. Data Observability platforms often need to deliver this level of customization.
Once you’ve determined what part(s) of your business you’ll be innovating — the next step in a digital transformation strategy is using data to get there. Constructing A Digital Transformation Strategy: Data Enablement. Many organizations prioritize data collection as part of their digital transformation strategy.
Understanding the data governance trends for the year ahead will give business leaders and data professionals a competitive edge … Happy New Year! Regulatory compliance and data breaches have driven the data governance narrative during the past few years.
The need to integrate diverse data sources has grown exponentially, but there are several common challenges when integrating and analyzing data from multiple sources, services, and applications. First, you need to create and maintain independent connections to the same data source for different services.
DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data import and export tools. The scalability and flexible data schema of DynamoDB make it well-suited for a variety of use cases. Data stored in DynamoDB is the basis for valuable business intelligence (BI) insights.
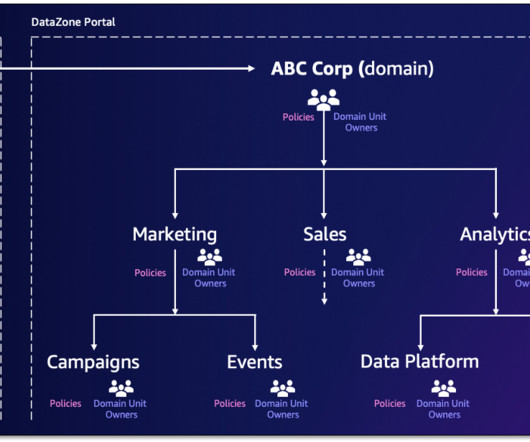
Amazon DataZone has announced a set of new data governance capabilities—domain units and authorization policies—that enable you to create business unit-level or team-level organization and manage policies according to your business needs. Organizations can adopt different approaches when defining and structuring domains and domain units.
Metadata management performs a critical role within the modern data management stack. It helps blur data silos, and empowers data and analytics teams to better understand the context and quality of data. This, in turn, builds trust in data and the decision-making to follow. Improve data discovery.
Although the terms data fabric and data mesh are often used interchangeably, I previously explained that they are distinct but complementary. The popularity of data fabric and data mesh has highlighted the importance of software providers, such as Denodo, that utilize data virtualization to enable logical data management.
We are excited to announce the preview of API-driven, OpenLineage-compatible data lineage in Amazon DataZone to help you capture, store, and visualize lineage of data movement and transformations of data assets on Amazon DataZone. The lineage visualized includes activities inside the Amazon DataZone business data catalog.
Data governance tools used to occupy a niche in an organization’s tech stack, but those days are gone. The rise of data-driven business and the complexities that come with it ushered in a soft mandate for data governance and data governance tools. It is also used to make data more easily understood and secure.
Gartner predicts that “By 2020, 50% of information governance initiatives will be enacted with policies based on metadata alone.”. Magic Quadrant for Metadata Management Solutions , Guido de Simoni and Roxane Edjlali, August 10, 2017. Metadata management no longer refers to a static technical repository.
It has been a little over a decade since the term data operations entered the analytics and data lexicon. It describes the application of agile development, DevOps and lean manufacturing by data engineering professionals in support of data production. Informatica is still closely associated with data integration.
Businesses are constantly evolving, and data leaders are challenged every day to meet new requirements. Customers are using AWS and Snowflake to develop purpose-built data architectures that provide the performance required for modern analytics and artificial intelligence (AI) use cases.
Metadata management is essential to becoming a data-driven organization and reaping the competitive advantage your organization’s data offers. Gartner refers to metadata as data that is used to enhance the usability, comprehension, utility or functionality of any other data point.
The Semantic Web, both as a research field and a technology stack, is seeing mainstream industry interest, especially with the knowledge graph concept emerging as a pillar for data well and efficiently managed. And what are the commercial implications of semantic technologies for enterprise data? Source: tag.ontotext.com.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a data lake to deliver business insights.
Data governance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or data lakes cataloged with the AWS Glue data catalog.
In March 2024, we announced the general availability of the generative artificial intelligence (AI) generated data descriptions in Amazon DataZone. In this post, we share what we heard from our customers that led us to add the AI-generated data descriptions and discuss specific customer use cases addressed by this capability.
Because things are changing and becoming more competitive in every sector of business, the benefits of business intelligence and proper use of data analytics are key to outperforming the competition. BI software uses algorithms to extract actionable insights from a company’s data and guide its strategic decisions.
In the era of digital transformation and data-driven decision making, organizations must rapidly harness insights from their data to deliver exceptional customer experiences and gain competitive advantage. Solution overview Salesforce Data Cloud provides a point-and-click experience to share data with a customer’s AWS account.
Data quality is crucial in data pipelines because it directly impacts the validity of the business insights derived from the data. Today, many organizations use AWS Glue Data Quality to define and enforce data quality rules on their data at rest and in transit.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content