

Eight Top DataOps Trends for 2022
DataKitchen
NOVEMBER 29, 2021
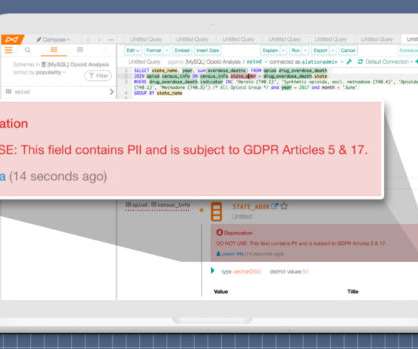
For example, a Hub-Spoke architecture could integrate data from a multitude of sources into a data lake. The Hub-Spoke architecture is part of a data enablement trend in IT. Data that flows through the Hub-Spoke data architecture will be controlled and managed by workflows located in a centralized process hub.





























Let's personalize your content