This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
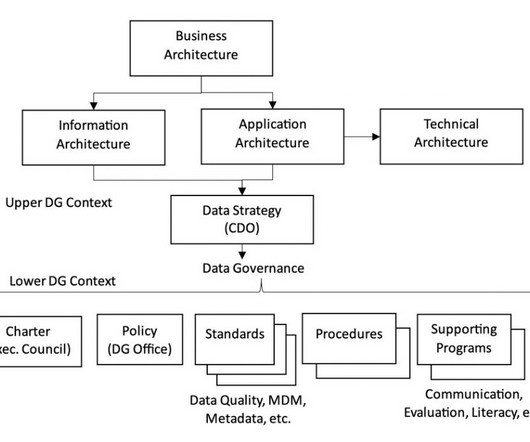
way we package information has a lot to do with metadata. The somewhat conventional metaphor about metadata is the one of the library card. This metaphor has it that books are the data and library cards are the metadata helping us find what we need, want to know more about or even what we don’t know we were looking for.
It addresses many of the shortcomings of traditional data lakes by providing features such as ACID transactions, schema evolution, row-level updates and deletes, and time travel. In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient.
The training data and feature sets that feed machine learning algorithms can now be immensely enriched with tags, labels, annotations, and metadata that were inferred and/or provided naturally through the transformation of your repository of data into a graph of data.
Central IT Data Teams focus on standards, compliance, and cost reduction. ’ They are dataenabling vs. value delivery. Their software purchase behavior will align with enabling standards for line-of-business data teams who use various tools that act on data. Recession: the party is over.
Once you’ve determined what part(s) of your business you’ll be innovating — the next step in a digital transformation strategy is using data to get there. Constructing A Digital Transformation Strategy: DataEnablement. Many organizations prioritize data collection as part of their digital transformation strategy.
I have long stated that data is the lifeblood of digital transformation, and if the pandemic really has accelerated digital transformation, then the trends reported in IDC’s worldwide surveys make sense. But data without intelligence is just data, and this is WHY data intelligence is required.
For business users Data Catalogs offer a number of benefits such as better decision-making; data catalogs provide business users with quick and easy access to high-quality data. This availability of accurate and timely dataenables business users to make informed decisions, improving overall business strategies.
IDC, BARC, and Gartner are just a few analyst firms producing annual or bi-annual market assessments for their research subscribers in software categories ranging from data intelligence platforms and data catalogs to data governance, data quality, metadata management and more. and/or its affiliates in the U.S.
As I recently noted , the term “data intelligence” has been used by multiple providers across analytics and data for several years and is becoming more widespread as software providers respond to the need to provide enterprises with a holistic view of data production and consumption.
Advanced analytics and enterprise data empower companies to not only have a completely transparent view of movement of materials and products within their line of sight, but also leverage data from their suppliers to have a holistic view 2-3 tiers deep in the supply chain.
An effective data governance initiative should enable just that, by giving an organization the tools to: Discover data: Identify and interrogate metadata from various data management silos. Harvest data: Automate the collection of metadata from various data management silos and consolidate it into a single source.
Greater visibility of data is also required for businesses to be able to determine the nature of a document in order to understand, for example, whether it is confidential information, a work product, or an HR document. Getting full visibility of dataenables businesses to put in place a defensible data management process.
Tableau says a user working in hospitality could click “Draft with Einstein” for data about travel. The copilot would then use the data source’s metadata and field names to provide a detailed description of the data, enabling other analysts to more easily reference the insights.
These announcements drive forward the AWS Zero-ETL vision to unify all your data, enabling you to better maximize the value of your data with comprehensive analytics and ML capabilities, and innovate faster with secure data collaboration within and across organizations.
Also, data can be accidentally leaked from storage due to human error. Monitoring all sensitive dataenables companies to identify potential vulnerabilities and secure endpoints before a data leakage can occur. Storage DLP strives to pinpoint confidential files in storage and monitor who accesses and shares them.
At IBM, we believe it is time to place the power of AI in the hands of all kinds of “AI builders” — from data scientists to developers to everyday users who have never written a single line of code. Watsonx, IBM’s next-generation AI platform, is designed to do just that.
A data fabric utilizes an integrated data layer over existing, discoverable, and inferenced metadata assets to support the design, deployment, and utilization of data across enterprises, including hybrid and multi-cloud platforms. It also helps capture and connect data based on business or domains.
Join this session to learn how DIRECTV partnered with Alation to map their new dataverse, which includes Snowflake data sources (hubs), glossaries, enhanced metadata for metadata objects, lineage, and quality. They also recognized that to become 100% data- driven, first they had to become 100% metadata- driven.
In May 2021 at the CDO & Data Leaders Global Summit, DataKitchen sat down with the following data leaders to learn how to use DataOps to drive agility and business value. Kurt Zimmer, Head of Data Engineering for DataEnablement at AstraZeneca. Jim Tyo, Chief Data Officer, Invesco.
It provided the concept of a database, schemas, and tables for describing the structure of a data lake in a way that let BI tools traverse the data efficiently. The second generation of the Hive Metastore added support for transactional updates with Hive ACID.
Enterprises are… turning to data catalogs to democratize access to data, enable tribal data knowledge to curate information, apply data policies, and activate all data for business value quickly.”. Gartner: Magic Quadrant for Metadata Management Solutions. Below are some of our other favorites.
It provided the concept of a database, schemas, and tables for describing the structure of a data lake in a way that let BI tools traverse the data efficiently. The second generation of the Hive Metastore added support for transactional updates with Hive ACID.
With these techniques, you can enhance the processing speed and accessibility of your XML data, enabling you to derive valuable insights with ease. Process and transform XML data into a format (like Parquet) suitable for Athena using an AWS Glue extract, transform, and load (ETL) job. xml and technique2.xml. Choose Create.
One of the first steps in any digital transformation journey is to understand what data assets exist in the organization. When we began, we had a very technical and archaic tool, an enterprise metadata management platform that cataloged our assets. It was terribly complex. Promoting self-service analytics.
The company, which customizes, sells, and licenses more than one billion images, videos, and music clips from its mammoth catalog stored on AWS and Snowflake to media and marketing companies or any customer requiring digital content, currently stores more than 60 petabytes of objects, assets, and descriptors across its distributed data store.
Built on the Gartner-recognized DQLabs augmented data quality platform, erwin Data Intelligence’s new data quality offering provides erwin Data Intelligence customers with the ability to leverage erwin Data Catalog metadata to initiate a need for data quality assessment.
CIOs — who sign nearly half of all net-zero services deals with top providers, according to Everest Group analyst Meenakshi Narayanan — are uniquely positioned to spearhead data-enabled transformation for ESG reporting given their data-driven track records. The complexity is at a much higher level.”
According to the report, “Demand for data catalogs is soaring as organizations struggle to inventory distributed data assets to facilitate data monetization and conform to regulations.” The tour stops at Gartner Symposium next month, where you can learn first hand why Gartner believes “Data Catalogs are the New Black.”.
It’s the one thing that can save data teams from the risk of processing data from their own circular references, as this framework is a credible check-and-balance. Data Sovereignty and Cross?Border International data sharing is essential for many businesses. and simply sharing data across borders is not permitted.
The AWS Glue job can transform the raw data in Amazon S3 to Parquet format, which is optimized for analytic queries. The AWS Glue Data Catalog stores the metadata, and Amazon Athena (a serverless query engine) is used to query data in Amazon S3.
The need for robust data governance strategies and resources to satisfy corporate objectives while overcoming organizational, cultural, and skills challenges. The impact of AI and automation , which power platforms to achieve data governance driven by and centered around metadata. Dataenablement (literacy and collaboration).
After investing in self-service analytic tooling, organizations are now turning their attention to linking infrastructure and tooling to data-driven decisions. The Forrester Wave : Machine Learning Data Catalogs, Q2 2018. Here’s why your organization should catch the Wave. A New Market Category.
I just attended the 17th Annual Chief Data Officer and Information Quality Symposium in July, and there, I heard many creative suggestions for renaming data governance. Calling it dataenablement, data trust, data utilization, and many other names to try and avoid the […]
Another capability of knowledge graphs that contributes to improved search and discoverability is that they can integrate and index multiple forms of data and associated metadata. This is essential in facilitating complex financial concepts representation as well as data sharing and integration.
Streaming data facilitates the constant flow of diverse and up-to-date information, enhancing the models’ ability to adapt and generate more accurate, contextually relevant outputs. To better understand this, imagine a chatbot that helps travelers book their travel.
You can use the visualizations after you start importing data. Enable the Lambda function to start processing events into OpenSearch Service The final step is to go into the configuration of the Lambda function and enable the triggers so that the data can be read from the subscriber framework in Security Lake.
Offer the right tools Data stewardship is greatly simplified when the right tools are on hand. So ask yourself, does your steward have the software to spot issues with data quality, for example? Do they have a system to manage the metadata for given assets? One example is the EU’s General Data Protection Regulation (GDPR).
In our modern data and analytics strategy and operating model, a PM methodology plays a key enabling role in delivering solutions. Do you draw a distinction between a data-driven vision and a data-enabled vision, and if so, what is that distinction? I didn’t mean to imply this.
In his presentation, Mitesh shared how data intelligence helps joint users of Alation and Fivetran “look before they leap” as they go about the challenging process of building data pipelines (check out the slides from the “ Look Before Your Leap ” session here!) We have a jam-packed conference schedule ahead.
This configuration allows you to augment your sensitive on-premises data with cloud data while making sure all data processing and compute runs on-premises in AWS Outposts Racks. Additionally, Oktank must comply with data residency requirements, making sure that confidential data is stored and processed strictly on premises.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content