This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ISO 20022 data improves payment efficiency The impact of ISO 20022 on payment systems data is significant, as it allows for more detailed information in payment messages. These can help to increase customer satisfaction and loyalty.
In the last few years, Commercial Insurers have been making great strides in expanding the use of their data. The approach is very evolutionary; the initial focus tends to be aimed at cost savings and starts with structureddata. Then there is a recognition that there is so much more that can be done with the data.
The company, which customizes, sells, and licenses more than one billion images, videos, and music clips from its mammoth catalog stored on AWS and Snowflake to media and marketing companies or any customer requiring digital content, currently stores more than 60 petabytes of objects, assets, and descriptors across its distributed data store.
An effective data governance initiative should enable just that, by giving an organization the tools to: Discover data: Identify and interrogate metadata from various data management silos. Harvest data: Automate the collection of metadata from various data management silos and consolidate it into a single source.
Most commonly, we think of data as numbers that show information such as sales figures, marketing data, payroll totals, financial statistics, and other data that can be counted and measured objectively. This is quantitative data. It’s “hard,” structureddata that answers questions such as “how many?”
This means you can seamlessly combine information such as clinical data stored in HealthLake with data stored in operational databases such as a patient relationship management system, together with data produced from wearable devices in near real-time. The Data Catalog objects are listed under the awsdatacatalog database.
AI working on top of a data lakehouse, can help to quickly correlate passenger and security data, enabling real-time threat analysis and advanced threat detection. In order to move AI forward, we need to first build and fortify the foundational layer: data architecture.
Here, the ability of knowledge graphs to integrate diverse data from multiple sources is of high relevance. As you can see from the slide below, knowledge graphs can provide a single access point for various types of data such as structureddata, knowledge organization systems, transactional data and signals from unstructured content.
The AWS Glue Data Catalog stores the metadata, and Amazon Athena (a serverless query engine) is used to query data in Amazon S3. AWS Secrets Manager is an AWS service that can be used to store sensitive data, enabling users to keep data such as database credentials out of source code.
Streaming data facilitates the constant flow of diverse and up-to-date information, enhancing the models’ ability to adapt and generate more accurate, contextually relevant outputs. To better understand this, imagine a chatbot that helps travelers book their travel. versions).
A data pipeline is a series of processes that move raw data from one or more sources to one or more destinations, often transforming and processing the data along the way. Data pipelines support data science and business intelligence projects by providing data engineers with high-quality, consistent, and easily accessible data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







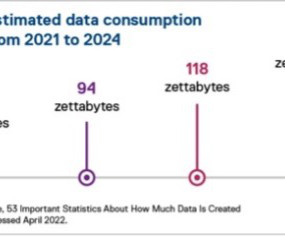











Let's personalize your content