This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Two use cases illustrate how this can be applied for business intelligence (BI) and datascience applications, using AWS services such as Amazon Redshift and Amazon SageMaker.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, data warehouses and datalakes fail when applied at the scale and speed of today’s organizations.
Initially, the data inventories of different services were siloed within isolated environments, making data discovery and sharing across services manual and time-consuming for all teams involved. Implementing robust datagovernance is challenging. The following figure illustrates the data mesh architecture.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
But unlocking value from data requires multiple analytics workloads, datascience tools and machine learning algorithms to run against the same diverse data sets. In our ongoing benchmark research project , we are researching the ways in which organizations work with big data and the challenges they face.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from data warehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
Reading Time: 6 minutes DataGovernance as a concept and practice has been around for as long as data management has been around. It, however is gaining prominence and interest in recent years due to the increasing volume of data that needs to be.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
The original proof of concept was to have one data repository ingesting data from 11 sources, including flat files and data stored via APIs on premises and in the cloud, Pruitt says. There are a lot of variables that determine what should go into the datalake and what will probably stay on premise,” Pruitt says.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
The data architect also “provides a standard common business vocabulary, expresses strategic requirements, outlines high-level integrated designs to meet those requirements, and aligns with enterprise strategy and related business architecture,” according to DAMA International’s Data Management Body of Knowledge.
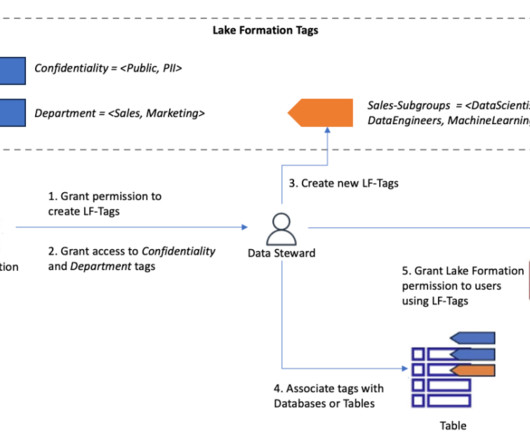
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or DataScience.
Data, of course, has been all the rage the past decade, having been declared the “new oil” of the digital economy. And yes, data has enormous potential to create value for your business, making its accrual and the analysis of it, aka datascience, very exciting.
A data hub is a center of data exchange that constitutes a hub of data repositories and is supported by data engineering, datagovernance, security, and monitoring services. A data hub contains data at multiple levels of granularity and is often not integrated.
This past week, I had the pleasure of hosting DataGovernance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , DataGovernance lead at Alation. Can you have proper data management without establishing a formal datagovernance program?
Datagovernance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or datalakes cataloged with the AWS Glue data catalog.
Modak Nabu automates repetitive tasks in the data preparation process and thus accelerates the data preparation by 4x. Modak Nabu reliably curates datasets for any line of business and personas, from business analysts to data scientists. Customers using Modak Nabu with CDP today have deployed DataLakes and.
To ensure maximum momentum and flawless service the Experian BIS Data Enrichment team decided to use the power of big data by utilizing Cloudera’s DataScience Workbench. This enabled Merck KGaA to control and maintain secure data access, and greatly increase business agility for multiple users.
To keep pace as banking becomes increasingly digitized in Southeast Asia, OCBC was looking to utilize AI/ML to make more data-driven decisions to improve customer experience and mitigate risks. Lastly, data security is paramount, especially in the finance industry.
The outline of the call went as follows: I was taking to a central state agency who was organizing a datagovernance initiative (in their words) across three other state agencies. All four agencies had reported an independent but identical experience with datagovernance in the past. An expensive consulting engagement.
Paco Nathan ‘s latest column dives into datagovernance. This month’s article features updates from one of the early data conferences of the year, Strata Data Conference – which was held just last week in San Francisco. In particular, here’s my Strata SF talk “Overview of DataGovernance” presented in article form.
In this post, we discuss how you can use purpose-built AWS services to create an end-to-end data strategy for C360 to unify and govern customer data that address these challenges. The AWS modern data architecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud.
The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. Read: The first capability of a data fabric is a semantic knowledge data catalog, but what are the other 5 core capabilities of a data fabric? 11 May 2021. .
A data lakehouse is an emerging data management architecture that improves efficiency and converges data warehouse and datalake capabilities driven by a need to improve efficiency and obtain critical insights faster. Let’s start with why data lakehouses are becoming increasingly important.
Paco Nathan ‘s latest monthly article covers Sci Foo as well as why datascience leaders should rethink hiring and training priorities for their datascience teams. In this episode I’ll cover themes from Sci Foo and important takeaways that datascience teams should be tracking. Introduction.
By adopting a custom developed application based on the Cloudera ecosystem, Carrefour has combined the legacy systems into one platform which provides access to customer data in a single datalake. In doing so, Bank of the West has modernized and centralized its Big Data platform in just one year.
Combining AWS data integration services like AWS Glue with data platforms like Snowflake allows you to build scalable, secure datalakes and pipelines to power analytics, BI, datascience, and ML use cases. This unlocks scalable analytics while maintaining datagovernance, compliance, and access control.
With each game release and update, the amount of unstructured data being processed grows exponentially, Konoval says. This volume of data poses serious challenges in terms of storage and efficient processing,” he says. To address this problem RetroStyle Games invested in datalakes.
Use cases could include but are not limited to: optimizing healthcare processes to save lives, data analysis for emergency resource management, building smarter cities with datascience, using data and analytics to fight climate change, tackle the food crisis or prioritize actions against poverty, and more.
Data curation is important in today’s world of data sharing and self-service analytics, but I think it is a frequently misused term. When speaking and consulting, I often hear people refer to data in their datalakes and data warehouses as curated data, believing that it is curated because it is stored as shareable data.
In the case of CDP Public Cloud, this includes virtual networking constructs and the datalake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each project consists of a declarative series of steps or operations that define the datascience workflow.
Reading Time: 5 minutes For years, organizations have been managing data by consolidating it into a single data repository, such as a cloud data warehouse or datalake, so it can be analyzed and delivered to business users. Unfortunately, organizations struggle to get this.
This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and datagovernance. 2) When data becomes information, many (incremental) use cases surface. He is creating information services for his clients, an emerging use case for SSDP.
In this post, we discuss how the Amazon Finance Automation team used AWS Lake Formation and the AWS Glue Data Catalog to build a data mesh architecture that simplified datagovernance at scale and provided seamless data access for analytics, AI, and machine learning (ML) use cases.
Modern data catalogs—originated to help data analysts find and evaluate data—continue to meet the needs of analysts, but they have expanded their reach. They are now central to data stewardship, data curation, and datagovernance—all metadata dependent activities.
If your team has easy-to-use tools and features, you are much more likely to experience the user adoption you want and to improve data literacy and data democratization across the organization.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. Perform data quality monitoring based on pre-configured rules.
Reading Time: 2 minutes The data lakehouse attempts to combine the best parts of the data warehouse with the best parts of datalakes while avoiding all of the problems inherent in both. However, the data lakehouse is not the last word in data.
Reading Time: 2 minutes The data lakehouse attempts to combine the best parts of the data warehouse with the best parts of datalakes while avoiding all of the problems inherent in both. However, the data lakehouse is not the last word in data.
“Le azioni successive per il miglioramento della data quality possono essere sia di processo che applicative e includono la definizione di un modello organizzativo intorno alla datagovernance , assegnando ruoli e compiti chiari alle varie figure coinvolte (data scientist, data engineering, data owner, data steward, eccetera)”.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
Leverage of Data to generate Insight. In this second area we have disciplines such as Analytics and DataScience. The objective here is to use a variety of techniques to tease out findings from available data (both internal and external) that go beyond the explicit purpose for which it was captured. Watch this space. [2].
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content