This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As AI adoption accelerates, it demands increasingly vast amounts of data, leading to more users accessing, transferring, and managing it across diverse environments. Each interaction amplifies the potential for errors, breaches, or misuse, underscoring the critical need for a strong governance framework to mitigate these risks.
Why should you integrate datagovernance (DG) and enterprise architecture (EA)? Datagovernance provides time-sensitive, current-state architecture information with a high level of quality. Datagovernance provides time-sensitive, current-state architecture information with a high level of quality.
Organizations with a solid understanding of datagovernance (DG) are better equipped to keep pace with the speed of modern business. In this post, the erwin Experts address: What Is DataGovernance? Why Is DataGovernance Important? What Is Good DataGovernance? What Is DataGovernance?
Automating datagovernance is key to addressing the exponentially growing volume and variety of data. Data readiness is everything. The State of Data Automation. Data readiness depends on automation to create the data pipeline. We asked participants to “talk to us about data value chain bottlenecks.”
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. What Is Metadata? Harvest data.
Metadata has been defined as the who, what, where, when, why, and how of data. Without the context given by metadata, data is just a bunch of numbers and letters. But going on a rampage to define, categorize, and otherwise metadata-ize your data doesn’t necessarily give you the key to the value in your data.
It addresses many of the shortcomings of traditional data lakes by providing features such as ACID transactions, schema evolution, row-level updates and deletes, and time travel. In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive datagovernance approach. Datagovernance is a critical building block across all these approaches, and we see two emerging areas of focus.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
The words “ datagovernance ” and “fun” are seldom spoken together. The term datagovernance conjures images of restrictions and control that result in an uphill challenge for most programs and organizations from the beginning. Or they are spending too much time preparing the data for proper use.
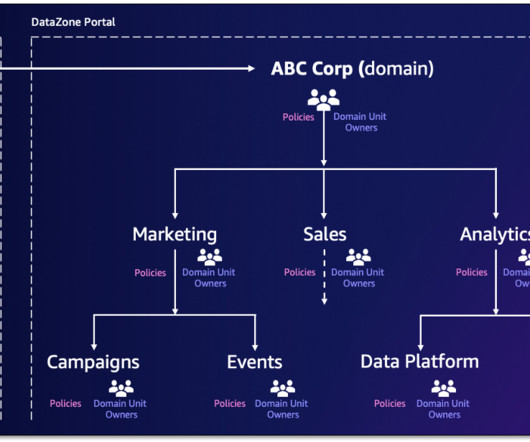
Amazon DataZone has announced a set of new datagovernance capabilities—domain units and authorization policies—that enable you to create business unit-level or team-level organization and manage policies according to your business needs. Data domains form a foundational pillar in datagovernance frameworks.
To achieve this, they aimed to break down data silos and centralize data from various business units and countries into the BMW Cloud Data Hub (CDH). However, the initial version of CDH supported only coarse-grained access control to entire data assets, and hence it was not possible to scope access to data asset subsets.
You also need solutions that let you understand what data you have and who can access it. About a third of the respondents in the survey indicated they are interested in datagovernance systems and data catalogs. Metadata and artifacts needed for audits. Marquez (WeWork) and Databook (Uber). Source: O'Reilly.
The reversal from information scarcity to information abundance and the shift from the primacy of entities to the primacy of interactions has resulted in an increased burden for the data involved in those interactions to be trustworthy.
A data catalog benefits organizations in a myriad of ways. With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, data quality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects.
Instead, we got data. Lots and lots of data. Well, we got jetpacks, too, but we rarely interact with them during the workday. It does feel, however, as if we need jet-like speed to analyze and understand our data, who is using it, how it is used, and if it is being used to drive value. This data about data is valuable.
Application Logic: Application logic refers to the type of data processing, and can be anything from analytical or operational systems to data pipelines that ingest data inputs, apply transformations based on some business logic and produce data outputs.
With business process modeling (BPM) being a key component of datagovernance , choosing a BPM tool is part of a dilemma many businesses either have or will soon face. Historically, BPM didn’t necessarily have to be tied to an organization’s datagovernance initiative. Choosing a BPM Tool: An Overview.
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). The company is expanding its partnership with Collibra to integrate Collibra’s AI Governance platform with SAP data assets to facilitate datagovernance for non-SAP data assets in customer environments. “We
This person (or group of individuals) ensures that the theory behind data quality is communicated to the development team. 2 – Data profiling. Data profiling is an essential process in the DQM lifecycle. from the business interactions), but if not available, then through confirmation techniques of an independent nature.
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. With AWS Glue 5.0,
“The number-one issue for our BI team is convincing people that business intelligence will help to make true data-driven decisions,” says Diana Stout, senior business analyst at Schellman, a global cybersecurity assessor based in Tampa, Fl. It’s about being able to find relevant data and connect it through a knowledge graph.
By providing a unified view of the data, the semantic layer helps ensure that different users and reports use consistent definitions and calculations, thereby helping to provide a single view of the customer. The new SAP Datasphere catalog provides data lineage, metadata information, and quick searching capabilities across your SAP landscape.
In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated. Interactive Query Synthesis from Input-Output Examples ” – Chenglong Wang, Alvin Cheung, Rastislav Bodik (2017-05-14).
Advanced analytics and enterprise data are empowering several overarching initiatives in supply chain risk reduction – improved visibility and transparency into all aspects of the supply chain balanced with datagovernance and security. . Improve Visibility within Supply Chains.
You will then publish the data assets from these data sources. The Amazon DataZone data sources allow you to connect to various data sources, including databases, data warehouses, and data lakes, and ingest metadata into Amazon DataZone. Add an AWS Glue data source to publish the new AWS Glue table.
The post will include details on how to perform read/write data operations against Amazon S3 tables with AWS Lake Formation managing metadata and underlying data access using temporary credential vending. Create a user defined IAM role following the instructions in Requirements for roles used to register locations.
Analytics reference architecture for gaming organizations In this section, we discuss how gaming organizations can use a data hub architecture to address the analytical needs of an enterprise, which requires the same data at multiple levels of granularity and different formats, and is standardized for faster consumption.
The financial services industry has been in the process of modernizing its datagovernance for more than a decade. But as we inch closer to global economic downturn, the need for top-notch governance has become increasingly urgent. Download the Gartner® Market Guide for Active Metadata Management 1.
The current method is largely manual, relying on emails and general communication, which not only increases overhead but also varies from one use case to another in terms of datagovernance. Data domain producers publish data assets using datasource run to Amazon DataZone in the Central Governance account.
In this post, we discuss how the Amazon Finance Automation team used AWS Lake Formation and the AWS Glue Data Catalog to build a data mesh architecture that simplified datagovernance at scale and provided seamless data access for analytics, AI, and machine learning (ML) use cases.
One of the first steps in any digital transformation journey is to understand what data assets exist in the organization. When we began, we had a very technical and archaic tool, an enterprise metadata management platform that cataloged our assets. The people behind the data are key. It was terribly complex.
The platform converges data cataloging, data ingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the data preparation process and thus accelerates the data preparation by 4x.
What Is Data Intelligence? Data intelligence is a system to deliver trustworthy, reliable data. It includes intelligence about data, or metadata. IDC coined the term, stating, “data intelligence helps organizations answer six fundamental questions about data.” Why keep data at all?
Limiting growth by (data integration) complexity Most operational IT systems in an enterprise have been developed to serve a single business function and they use the simplest possible model for this. In both cases, semantic metadata is the glue that turns knowledge graphs into hubs of data, metadata, and content.
Over the last week, millions of people around the world have interacted with OpenAI’s ChatGPT, which represents a significant advance for generative artificial intelligence (AI) and the foundation models that underpin many of these use cases. It’s a fitting way to end what has been another big year for the industry.
It delivers the ability to capture and unify the business and technical perspectives of data assets, enables effective collaboration between a variety of stakeholders, and delivers metadata-driven automation to accelerate the creation and maintenance of data sources on virtually any data management platform.
Paco Nathan ‘s latest column dives into datagovernance. This month’s article features updates from one of the early data conferences of the year, Strata Data Conference – which was held just last week in San Francisco. In particular, here’s my Strata SF talk “Overview of DataGovernance” presented in article form.
Customer 360 (C360) provides a complete and unified view of a customer’s interactions and behavior across all touchpoints and channels. This view is used to identify patterns and trends in customer behavior, which can inform data-driven decisions to improve business outcomes. Then, you transform this data into a concise format.
According to the Forrester Wave: Machine Learning Data Catalogs, Q4 2020 , “Alation exploits machine learning at every opportunity to improve data management, governance, and consumption by analytic citizens. An MLDC brings many benefits, like: Enhanced data management. Datagovernance streamlining.
Datagovernance is the collection of policies, processes, and systems that organizations use to ensure the quality and appropriate handling of their data throughout its lifecycle for the purpose of generating business value.
Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback. Iceberg captures metadata information on the state of datasets as they evolve and change over time. Choose Create.
Ehtisham Zaidi, Gartner’s VP of data management, and Robert Thanaraj, Gartner’s director of data management, gave an update on the fabric versus mesh debate in light of what they call the “active metadata era” we’re currently in. The foundations of successful datagovernance The state of datagovernance was also top of mind.
This approach allows the team to process the raw data extracted from Account A to Account B, which is dedicated for data handling tasks. This makes sure the raw and processed data can be maintained securely separated across multiple accounts, if required, for enhanced datagovernance and security. secretsmanager ).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content