This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses.
At AWS re:Invent 2024, we announced the next generation of Amazon SageMaker , the center for all your data, analytics, and AI. It enables teams to securely find, prepare, and collaborate on data assets and build analytics and AI applications through a single experience, accelerating the path from data to value.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Together, these capabilities enable terminal operators to enhance efficiency and competitiveness in an industry that is increasingly datadriven.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data.
Businesses are constantly evolving, and data leaders are challenged every day to meet new requirements. Customers are using AWS and Snowflake to develop purpose-built data architectures that provide the performance required for modern analytics and artificial intelligence (AI) use cases.
Data is the foundation of innovation, agility and competitive advantage in todays digital economy. As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Data quality is no longer a back-office concern.
Analytics are prone to frequent data errors and deployment of analytics is slow and laborious. When internal resources fall short, companies outsource data engineering and analytics. There’s no shortage of consultants who will promise to manage the end-to-end lifecycle of data from integration to transformation to visualization. .
The rapid adoption of software as a service (SaaS) solutions has led to data silos across various platforms, presenting challenges in consolidating insights from diverse sources. Introducing the Salesforce connector for AWS Glue To meet the demands of diverse dataintegration use cases, AWS Glue now supports SaaS connectivity for Salesforce.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Q: Is data modeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. A: It always was and is getting cooler!!
Data is the most significant asset of any organization. However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture.
In this post, we focus on data management implementation options such as accessing data directly in Amazon Simple Storage Service (Amazon S3), using popular data formats like Parquet, or using open table formats like Iceberg. Data management is the foundation of quantitative research.
Although the terms data fabric and data mesh are often used interchangeably, I previously explained that they are distinct but complementary. The popularity of data fabric and data mesh has highlighted the importance of software providers, such as Denodo, that utilize data virtualization to enable logical data management.
Organizations run millions of Apache Spark applications each month on AWS, moving, processing, and preparing data for analytics and machine learning. Data practitioners need to upgrade to the latest Spark releases to benefit from performance improvements, new features, bug fixes, and security enhancements. Original code (Glue 2.0)
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
This week SnapLogic posted a presentation of the 10 Modern DataIntegration Platform Requirements on the company’s blog. They are: Application integration is done primarily through REST & SOAP services. Large-volume dataintegration is available to Hadoop-based datalakes or cloud-based data warehouses.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. He is a very visual person, so our proof of concept collects different data sets and ingests them into our Azure data house.
A data management platform (DMP) is a group of tools designed to help organizations collect and manage data from a wide array of sources and to create reports that help explain what is happening in those data streams. Deploying a DMP can be a great way for companies to navigate a business world dominated by data.
The need to integrate diverse data sources has grown exponentially, but there are several common challenges when integrating and analyzing data from multiple sources, services, and applications. First, you need to create and maintain independent connections to the same data source for different services.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
For those in the data world, this post provides a curated guide for all analytics sessions that you can use to quickly schedule and build your itinerary. A shapeshifting guardian and protector of data like Data Lynx? Or a digitally clairvoyant master of data insights like Cloud Sight?
Since 2015, the Cloudera DataFlow team has been helping the largest enterprise organizations in the world adopt Apache NiFi as their enterprise standard data movement tool. This need has generated a market opportunity for a universal data distribution service. Why does every organization need it when using a modern data stack?
So if you’re going to move from your data from on-premise legacy data stores and warehouse systems to the cloud, you should do it right the first time. And as you make this transition, you need to understand what data you have, know where it is located, and govern it along the way. Then you must bulk load the legacy data.
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. The company stores vast amounts of transactional data, customer information, and product catalogs in Snowflake.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and datalakes based on operational data.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud data warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
ChatGPT> DataOps, or data operations, is a set of practices and technologies that organizations use to improve the speed, quality, and reliability of their data analytics processes. The goal of DataOps is to help organizations make better use of their data to drive business decisions and improve outcomes.
This first article emphasizes data as the ‘foundation-stone’ of AI-based initiatives. Establishing a Data Foundation. Software development, once solely the domain of human programmers, is now increasingly the by-product of data being carefully selected, ingested, and analysed by machine learning (ML) systems in a recurrent cycle.
Once you’ve determined what part(s) of your business you’ll be innovating — the next step in a digital transformation strategy is using data to get there. Constructing A Digital Transformation Strategy: Data Enablement. Many organizations prioritize data collection as part of their digital transformation strategy.
Data warehousing is getting on in years. However, data warehousing and BI applications are only considered moderately successful. Advanced analytics and new ways of working with data also create new requirements that surpass the traditional concepts. Can the basic nature of the data be proactively improved?
In today’s world that is largely data-driven, organizations depend on data for their success and survival, and therefore need robust, scalable data architecture to handle their data needs. This typically requires a data warehouse for analytics needs that is able to ingest and handle real time data of huge volumes.
The partners say they will create the future of digital manufacturing by leveraging the industrial internet of things (IIoT), digital twin , data, and AI to bring products to consumers faster and increase customer satisfaction, all while improving productivity and reducing costs. Data and AI as digital fundamentals.
Since 2015, the Cloudera DataFlow team has been helping the largest enterprise organizations in the world adopt Apache NiFi as their enterprise standard data movement tool. This need has generated a market opportunity for a universal data distribution service. Why does every organization need it when using a modern data stack?
Most organizations have come to understand the importance of being data-driven. To compete in a digital economy, it’s essential to base decisions and actions on accurate data, both real-time and historical. But the sheer volume of the world’s data is expected to nearly triple between 2020 and 2025 to a whopping 180 zettabytes.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless dataintegration engine.
Today on the AWS re:Invent keynote stage, Swami Sivasubramanian, VP of Data and AI, AWS, spoke about the beneficial relationship among data, generative AI, and humans—all working together to unleash new possibilities in efficiency and creativity. This week, we launched many new tools to help you turn your data into your differentiator.
Data management platform definition A data management platform (DMP) is a suite of tools that helps organizations to collect and manage data from a wide array of first-, second-, and third-party sources and to create reports and build customer profiles as part of targeted personalization campaigns.
We live in a world of data: there’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways organizations tackle the challenges of this new world to help their companies and their customers thrive. Understanding how data becomes insights.
For any modern data-driven company, having smooth dataintegration pipelines is crucial. These pipelines pull data from various sources, transform it, and load it into destination systems for analytics and reporting. Undetected errors result in bad data and impact downstream analysis.
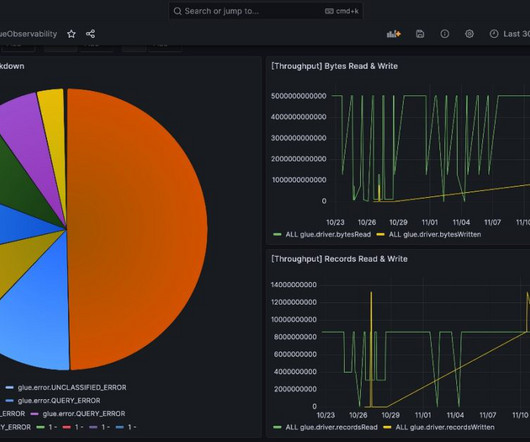
Monitoring data pipelines in real time is critical for catching issues early and minimizing disruptions. AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your dataintegration pipelines built on AWS Glue. Choose Add new data source.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content