This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. Having confidence in your data is key.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, dataquality and master data management.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Under that focus, Informatica's conference emphasized capabilities across six areas (all strong areas for Informatica): dataintegration, data management, dataquality & governance, Master Data Management (MDM), data cataloging, and data security.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
Hundreds of thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. We also show how to take action based on the dataquality results.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
Ensuring that data is available, secure, correct, and fit for purpose is neither simple nor cheap. Companies end up paying outside consultants enormous fees while still having to suffer the effects of poor dataquality and lengthy cycle time. . For example, DataOps can be used to automate dataintegration.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Hundreds of thousands of customers use datalakes for analytics and ML to make data-driven business decisions.
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. The data science and AI teams are able to explore and use new data sources as they become available through Amazon DataZone.
The core issue plaguing many organizations is the presence of out-of-control databases or datalakes characterized by: Unrestrained Data Changes: Numerous users and tools incessantly alter data, leading to a tumultuous environment. Monitor freshness, schema changes, volume, and column health are standard.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless dataintegration engine.
Working with large language models (LLMs) for enterprise use cases requires the implementation of quality and privacy considerations to drive responsible AI. However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Further, data management activities don’t end once the AI model has been developed. Addressing the Challenge.
These stewards monitor the input and output of dataintegrations and workflows to ensure dataquality. Their focus is on master data management , datalakes / warehouses, and ensuring the trackability of data using audit trails and metadata. How to Get Started with Information Stewardship.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make dataintegration effortless.
Outsourcing these data management efforts to professional services firms only delays schedules and increases costs. With automation, dataquality is systemically assured. The data pipeline is seamlessly governed and operationalized to the benefit of all stakeholders. Digital Transformation Strategy: Smarter Data.
Selling the value of data transformation Iyengar and his team are 18 months into a three- to five-year journey that started by building out the data layer — corralling data sources such as ERP, CRM, and legacy databases into data warehouses for structured data and datalakes for unstructured data.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data.
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Set up unified data governance rules and processes.
Dataquality for account and customer data – Altron wanted to enable dataquality and data governance best practices. Goals – Lay the foundation for a data platform that can be used in the future by internal and external stakeholders.
The application gets prompt templates from an S3 datalake and creates the engineered prompt. The user interaction is stored in a datalake for downstream usage and BI analysis. The application sends the prompt to Amazon Bedrock and retrieves the LLM output.
The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. Read: The first capability of a data fabric is a semantic knowledge data catalog, but what are the other 5 core capabilities of a data fabric? What’s a data mesh?
Many customers need an ACID transaction (atomic, consistent, isolated, durable) datalake that can log change data capture (CDC) from operational data sources. There is also demand for merging real-time data into batch data. Delta Lake framework provides these two capabilities. option("header",True).schema(schema).load("s3://"+
The post OReilly Releases First Chapters of a New Book about Logical Data Management appeared first on Data Management Blog - DataIntegration and Modern Data Management Articles, Analysis and Information. Gartner predicts that by the end of this year, 30%.
Migrating workloads to AWS Glue AWS Glue is a serverless dataintegration service that helps analytics users to discover, prepare, move, and integratedata from multiple sources. You can visually create, run, and monitor ETL pipelines to load data into your datalakes.
Bad data tax is rampant in most organizations. Currently, every organization is blindly chasing the GenAI race, often forgetting that dataquality and semantics is one of the fundamentals to achieving AI success. Sadly, dataquality is losing to data quantity, resulting in “ Infobesity ”. “Any
Thoughtworks says data mesh is key to moving beyond a monolithic datalake. Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Thoughtworks says data mesh is key to moving beyond a monolithic datalake 2. Gartner on Data Fabric.
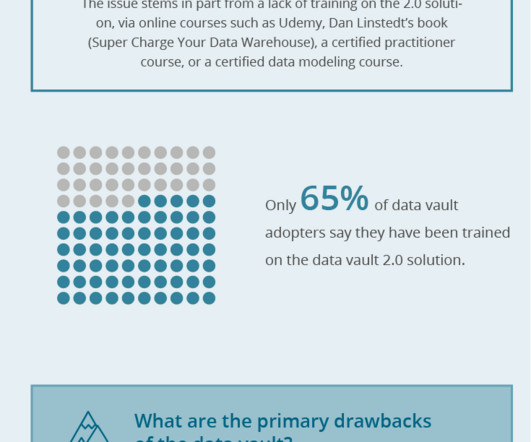
While most continue to struggle with dataquality issues and cumbersome manual processes, best-in-class companies are making improvements with commercial automation tools. The data vault has strong adherents among best-in-class companies, even though its usage lags the alternative approaches of third-normal-form and star schema.
Observability in DataOps refers to the ability to monitor and understand the performance and behavior of data-related systems and processes, and to use that information to improve the quality and speed of data-driven decision making. By using DataOps, organizations can improve. Query> When do DataOps?
Improved Decision Making : Well-modeled data provides insights that drive informed decision-making across various business domains, resulting in enhanced strategic planning. Reduced Data Redundancy : By eliminating data duplication, it optimizes storage and enhances dataquality, reducing errors and discrepancies.
Data Pipeline Use Cases Here are just a few examples of the goals you can achieve with a robust data pipeline: Data Prep for Visualization Data pipelines can facilitate easier data visualization by gathering and transforming the necessary data into a usable state.
With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics in 2021, it became more critical to scale and generate near-real-time data. You can visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, datalakes, data warehouses and SQL databases, providing a holistic view into business performance. Then, it applies these insights to automate and orchestrate the data lifecycle.
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, dataintegrity is of paramount importance.
If your team has easy-to-use tools and features, you are much more likely to experience the user adoption you want and to improve data literacy and data democratization across the organization. Sophisticated Functionality – Don’t sacrifice functionality to get ease-of-use.
For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance. It uses metadata and data management tools to organize all data assets within your organization. Ensuring dataquality is made easier as a result.
As a design concept, data fabric requires a combination of existing and emergent data management technologies beyond just metadata. Data fabric does not replace data warehouses, datalakes, or data lakehouses. This applies policies based on consumer profiles to automate policy enforcements.
Equally crucial is the ability to segregate and audit problematic data, not just for maintaining dataintegrity, but also for regulatory compliance, error analysis, and potential data recovery. One of its key features is the ability to manage data using branches.
Creating a single view of any data, however, requires the integration of data from disparate sources. Dataintegration is valuable for businesses of all sizes due to the many benefits of analyzing data from different sources. But dataintegration is not trivial. Establishes Trust in Data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content