Introducing Precisely for Data Integrity
David Menninger's Analyst Perspectives
JANUARY 25, 2021
At the same time, organizations have become more disciplined about the data on which they rely to ensure it is robust, accurate and governed properly.
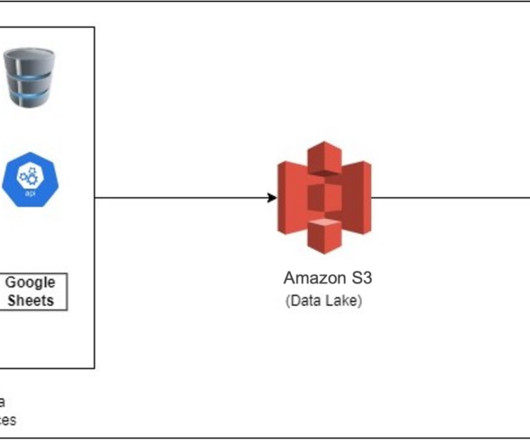
 Data Integration Data Lake Information
Data Integration Data Lake Information 
David Menninger's Analyst Perspectives
JANUARY 25, 2021
At the same time, organizations have become more disciplined about the data on which they rely to ensure it is robust, accurate and governed properly.

AWS Big Data
DECEMBER 4, 2024
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

AWS Big Data
DECEMBER 20, 2024
Amazon Q data integration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q data integration transforms ETL workflow development.

AWS Big Data
OCTOBER 3, 2023
A data lake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.

AWS Big Data
OCTOBER 19, 2023
Data lakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure.

CIO Business Intelligence
FEBRUARY 27, 2025
According to a study from Rocket Software and Foundry , 76% of IT decision-makers say challenges around accessing mainframe data and contextual metadata are a barrier to mainframe data usage, while 64% view integrating mainframe data with cloud data sources as the primary challenge.

AWS Big Data
DECEMBER 17, 2024
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, data lake analytics, machine learning (ML), and data monetization.

Expert insights. Personalized for you.











































Let's personalize your content