This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. The new data preparation interface in AWS Glue Studio provides an intuitive, spreadsheet-style view for interactively working with tabular data. Choose Create policy.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Speaker: Anthony Roach, Director of Product Management at Tableau Software, and Jeremiah Morrow, Partner Solution Marketing Director at Dremio
Tableau works with Strategic Partners like Dremio to build dataintegrations that bring the two technologies together, creating a seamless and efficient customer experience. As a result of a strategic partnership, Tableau and Dremio have built a native integration that goes well beyond a traditional connector.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. To overcome these hurdles, many organizations are building bespoke integrations between services, tools, and homegrown access management systems.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising dataintegrity. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
AWS Glue is a serverless, scalable dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources. AWS Glue provides an extensible architecture that enables users with different data processing use cases. as follows: # Use Glue version 3.0
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
The Perilous State of Today’s Data Environments Data teams often navigate a labyrinth of chaos within their databases. Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. Let’s say that this company is located in Europe and the data product must comply with the GDPR.
Over the last decade, we have often heard about the proliferation of data creating sources (mobile applications, laptops, sensors, enterprise apps) in heterogeneous environments (cloud, on-prem, edge) resulting in the exponential growth of data being created.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
Hundreds of thousands of customers use AWS Glue , a serverless dataintegration service, to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue for Apache Spark jobs work with your code and configuration of the number of data processing units (DPU). or later.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing. For Workgroup , choose blog-workgroup.
Over the last decade, we have often heard about the proliferation of data creating sources (mobile applications, laptops, sensors, enterprise apps) in heterogeneous environments (cloud, on-prem, edge) resulting in the exponential growth of data being created.
The data sourcing problem To ensure the reliability of PySpark data pipelines, it’s essential to have consistent record-level data from both dimensional and fact tables stored in the Enterprise Data Warehouse (EDW). These tables are then joined with tables from the Enterprise DataLake (EDL) at runtime.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
The trend has been towards using cloud-based applications and tools for different functions, such as Salesforce for sales, Marketo for marketing automation, and large-scale data storage like AWS or datalakes such as Amazon S3 , Hadoop and Microsoft Azure. Sisense provides instant access to your cloud data warehouses.
For any modern data-driven company, having smooth dataintegration pipelines is crucial. These pipelines pull data from various sources, transform it, and load it into destination systems for analytics and reporting. When running properly, it provides timely and trustworthy information.
This data is derived from your purpose-built data stores and previous interactions. Semantic context – Is there any meaningfully relevant data that would help the FMs generate the response? The semantic context originates from vector data stores or machine learning (ML) search services. Also, who is the user?
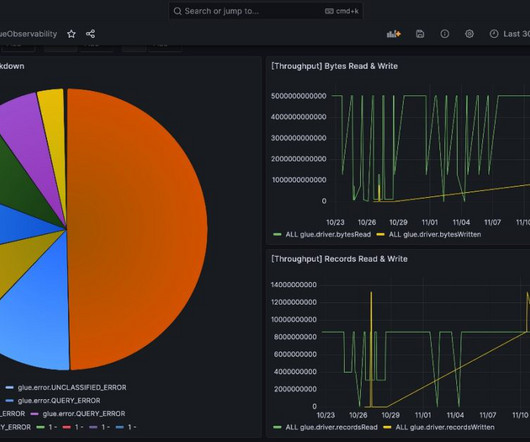
Monitoring data pipelines in real time is critical for catching issues early and minimizing disruptions. AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your dataintegration pipelines built on AWS Glue.
QuickSight makes it straightforward for business users to visualize data in interactive dashboards and reports. You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. Mohit Saxena is a Senior Software Development Manager on the AWS Glue team.
Third, AWS continues adding support for more data sources including connections to software as a service (SaaS) applications, on-premises applications, and other clouds so organizations can act on their data. Visit Dataintegration with AWS to learn more.
We are excited to announce the General Availability of AWS Glue Data Quality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. DeeQu is optimized to run data quality rules in minimal passes that makes it efficient.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Introduction.
Customer 360 (C360) provides a complete and unified view of a customer’s interactions and behavior across all touchpoints and channels. This view is used to identify patterns and trends in customer behavior, which can inform data-driven decisions to improve business outcomes. Then, you transform this data into a concise format.
In case the data sources change, data engineers have to manually make changes in their code and deploy it again. Furthermore, the time required to build or change pipelines makes the data unfit for near-real-time use cases such as detecting fraudulent transactions, placing online ads, and tracking passenger train schedules.
This post proposes an automated solution by using AWS Glue for automating the PostgreSQL data archiving and restoration process, thereby streamlining the entire procedure. Vivek Shrivastava is a Principal Data Architect, DataLake in AWS Professional Services. He is a big data enthusiast and holds 14 AWS Certifications.
Migrating workloads to AWS Glue AWS Glue is a serverless dataintegration service that helps analytics users to discover, prepare, move, and integratedata from multiple sources. You can visually create, run, and monitor ETL pipelines to load data into your datalakes.
Reduced Data Redundancy : By eliminating data duplication, it optimizes storage and enhances data quality, reducing errors and discrepancies. Efficient Development : Accurate data models expedite database development, leading to efficient dataintegration, migration, and application development.
When a mix of batch, interactive, and data serving workloads are added to the mix, the problem becomes nearly intractable. While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ datalake. Cloudera Manager (CM) 6.2
Satori accelerates implementing data security controls on datawarehouses like Amazon Redshift, is straightforward to integrate, and doesn’t require any changes to your Amazon Redshift data, schema, or how your users interact with data.
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating datalakes, serving as object storage for consumer applications, storing logs, and archiving data. For Report path prefix , enter cur-data/account-cur-daily.
Architecture for data democratization Data democratization requires a move away from traditional “data at rest” architecture, which is meant for storing static data. Traditionally, data was seen as information to be put on reserve, only called upon during customer interactions or executing a program.
For those asking big questions, in the case of healthcare, an incredible amount of insight remains hidden away in troves of clinical notes, EHR data, medical images, and omics data. To arrive at quality data, organizations are spending significant levels of effort on dataintegration, visualization, and deployment activities.
With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics in 2021, it became more critical to scale and generate near-real-time data. You can visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content