This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from data warehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
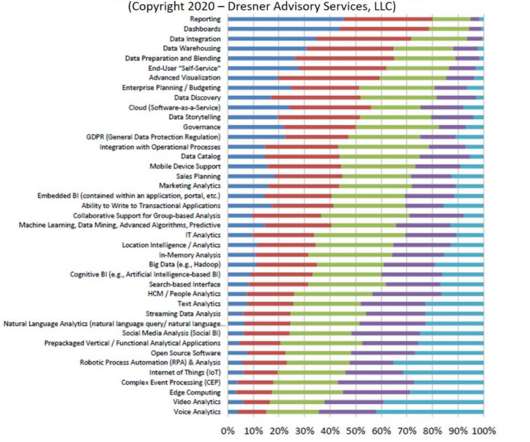
Among all the hot analytics initiatives to choose from (big data, IoT, NLP, data storytelling, cognitive BI, GDPR), plain old reporting is what is considered the most important strategic initiative. But seriously, reporting?
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
When Cargill started putting IoT sensors into shrimp ponds, then CIO Justin Kershaw realized that the $130 billion agricultural business was becoming a digital business. To help determine where IT should stop and IoT product engineering should start, Kershaw did not call CIOs of other food and agricultural businesses to compare notes.
The original proof of concept was to have one data repository ingesting data from 11 sources, including flat files and data stored via APIs on premises and in the cloud, Pruitt says. There are a lot of variables that determine what should go into the datalake and what will probably stay on premise,” Pruitt says.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. Data Pipeline: Use Cases. Destination.
The company has already undertaken pilot projects in Egypt, India, Japan, and the US that use Azure IoT Hub and IoT Edge to help manufacturing technicians analyze insights to create improvements in the production of baby care and paper products. It also involves large amounts of data and near real-time processing.
This typically requires a data warehouse for analytics needs that is able to ingest and handle real time data of huge volumes. Snowflake is a cloud-native platform that eliminates the need for separate data warehouses, datalakes, and data marts allowing secure data sharing across the organization.
One of the most promising technology areas in this merger that already had a high growth potential and is poised for even more growth is the Data-in-Motion platform called Hortonworks DataFlow (HDF). CDF, as an end-to-end streaming data platform, emerges as a clear solution for managing data from the edge all the way to the enterprise.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, datalakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based dataintegration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. Azure Blob Storage serves as the datalake to store raw data.
Loading complex multi-point datasets into a dimensional model, identifying issues, and validating dataintegrity of the aggregated and merged data points are the biggest challenges that clinical quality management systems face. Although datalakes resemble data vaults, a data vault provides more features of a data warehouse.
In my last post, I wrote about the new dataintegration requirements. In this post I wanted to share a few points made recently in a TDWI institute interview with SnapLogic founder and CEO Gaurav Dhillon when he was asked: What are some of the most interesting trends you’re seeing in the BI, analytics, and data warehousing space?
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. The post How Cloudera Data Flow Enables Successful Data Mesh Architectures appeared first on Cloudera Blog.
This typically requires a data warehouse for analytics needs that is able to ingest and handle real time data of huge volumes. Snowflake is a cloud-native platform that eliminates the need for separate data warehouses, datalakes, and data marts allowing secure data sharing across the organization.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, dataintegration, and mission-critical applications. Internet-of-Things [ IoT] devices, system telemetry data, or clickstream data) from a busy website or application.
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a datalake, transformed, and made available for analytics, machine learning (ML), and visualization.
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time data analytics, considering the growing velocity and volume of data being collected.
The post Go Fast and Far Using Data Virtualization appeared first on Data Virtualization blog - DataIntegration and Modern Data Management Articles, Analysis and Information. Technologies change constantly within organizations and having a flexible architecture is key.
The post Go Fast and Far Using Data Virtualization to help you Go Fast and Go Far appeared first on Data Virtualization blog - DataIntegration and Modern Data Management Articles, Analysis and Information. Technologies change constantly within organizations and having a flexible architecture is key.
The post The Energy Utilities Series: Challenges and Opportunities of Decarbonization (Post 2 of 6) appeared first on Data Management Blog - DataIntegration and Modern Data Management Articles, Analysis and Information. Decarbonization is the process of transitioning from.
However, more than 99 percent of respondents said they would migrate data to the cloud over the next two years. The Internet of Things (IoT) is a huge contributor of data to this growing volume, iotaComm estimates there are 35 billion IoT devices worldwide and that in 2025 all IoT devices combined will generate 79.4
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , data warehouse, datalake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
If you reflect for a moment, the last major technology inflection points were probably things like mobility, IoT, development operations and the cloud to name but a few. edge compute data distribution that connect broad, deep PLM eco-systems. Agentic AI is here to stay and will gain tremendous momentum in 2024.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content