This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data is becoming more valuable and more important to organizations. At the same time, organizations have become more disciplined about the data on which they rely to ensure it is robust, accurate and governed properly.
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
Speaker: Anthony Roach, Director of Product Management at Tableau Software, and Jeremiah Morrow, Partner Solution Marketing Director at Dremio
Tableau works with Strategic Partners like Dremio to build dataintegrations that bring the two technologies together, creating a seamless and efficient customer experience. As a result of a strategic partnership, Tableau and Dremio have built a native integration that goes well beyond a traditional connector.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
A high hurdle many enterprises have yet to overcome is accessing mainframe data via the cloud. Data professionals need to access and work with this information for businesses to run efficiently, and to make strategic forecasting decisions through AI-powered data models.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses.
A modern data strategy redefines and enables sharing data across the enterprise and allows for both reading and writing of a singular instance of the data using an open table format. Why Cloudinary chose Apache Iceberg Apache Iceberg is a high-performance table format for huge analytic workloads.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
Businesses are constantly evolving, and data leaders are challenged every day to meet new requirements. licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. This post is co-written with Andries Engelbrecht and Scott Teal from Snowflake.
At Salesforce World Tour NYC today, Salesforce unveiled a new global ecosystem of technology and solution providers geared to help its customers leverage third-party data via secure, bidirectional zero-copy integrations with Salesforce Data Cloud. It works in Salesforce just like any other native Salesforce data,” Carlson said.
Amazon Redshift is a fast, fully managed petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
Amazon SageMaker brings together widely adopted AWS machine learning (ML) and analytics capabilities and addresses the challenges of harnessing organizational data for analytics and AI through unified access to tools and data with governance built in. The data analyst then discovers it and creates a comprehensive view of their market.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, data quality and master data management. Its code generation architecture uses a visual interface to create Java or SQL code.
Effective data analytics relies on seamlessly integratingdata from disparate systems through identifying, gathering, cleansing, and combining relevant data into a unified format. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
As coined by British mathematician Clive Humby, "data is the new oil." Like oil, data is valuable but it must be refined in order to provide value. Organizations need to collect, organize, and analyze their data across multi-cloud, hybrid cloud, and datalakes.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. This innovation drives an important change: you’ll no longer have to copy or move data between datalake and data warehouses.
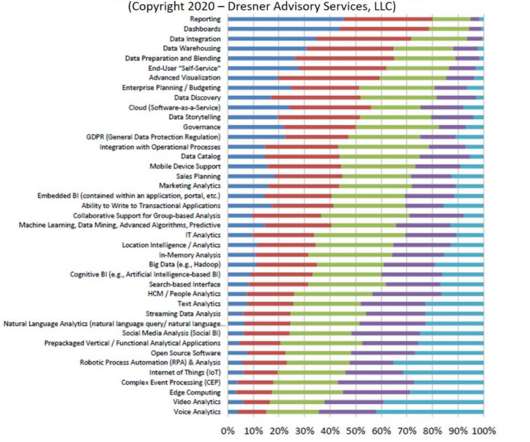
In fact, the top of the list is all meat-and-potatoes data needs — reporting, dashboards, dataintegration, data warehousing (sorry, not datalakes), and data prep. It is everywhere, holding the data universe together, yet it manages to elude our attention and affection.
When internal resources fall short, companies outsource data engineering and analytics. Large enterprises integrate hundreds or thousands of asynchronous data sources into a web of pipelines that flow into visualizations and purpose-built databases that support self-service analysis. Here is where the loss of control begins.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
Data quality is no longer a back-office concern. As a leader, your commitment to data quality sets the tone for the entire organization, inspiring others to prioritize this crucial aspect of digital transformation. However, even the most sophisticated models and platforms can be undone by a single point of failure: poor data quality.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Data Centricity. There is evidence to suggest that there is a blind spot when it comes to data in the AI context.
As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls. Yet, it is the quality of the data that will determine how efficient and valuable GenAI initiatives will be for organizations.
Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. In this scenario, you’re a data analyst in this company.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates dataintegration workloads in AWS.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. As mentioned earlier, 80% of quantitative research work is attributed to data management tasks.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make dataintegration effortless. Choose Save to save your job, and choose Run to run the job.
AWS Glue is a serverless, scalable dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources. AWS Glue provides an extensible architecture that enables users with different data processing use cases. as follows: # Use Glue version 3.0
The infrastructure provides an analytics experience to hundreds of in-house analysts, data scientists, and student-facing frontend specialists. The data engineering team is on a mission to modernize its dataintegration platform to be agile, adaptive, and straightforward to use.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
Snapshot and restore results in longer downtimes and greater loss of data between when the disaster event occurs and recovery. Sesha Sanjana Mylavarapu is an Associate DataLake Consultant at AWS Professional Services. Additionally, not all workloads require RTO and RPO in minutes or less. Do not enable standby mode.
The Perilous State of Today’s Data Environments Data teams often navigate a labyrinth of chaos within their databases. Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. These controls are designed to grant access with the right level of privileges and context.
Data fabric and data mesh are also both related to logical data management, which is the approach of providing virtualized access to data across an enterprise without the requirement to first extract and load it into a central repository.
A data management platform (DMP) is a group of tools designed to help organizations collect and manage data from a wide array of sources and to create reports that help explain what is happening in those data streams. Deploying a DMP can be a great way for companies to navigate a business world dominated by data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content