This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
Data is becoming more valuable and more important to organizations. At the same time, organizations have become more disciplined about the data on which they rely to ensure it is robust, accurate and governed properly.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and datamanagement resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud computing.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive datamanagement solutions.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, data quality and master datamanagement.
Under that focus, Informatica's conference emphasized capabilities across six areas (all strong areas for Informatica): dataintegration, datamanagement, data quality & governance, Master DataManagement (MDM), data cataloging, and data security.
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
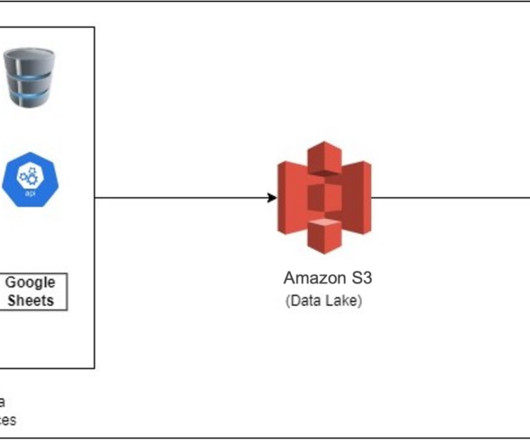
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. We will use AWS Region us-east-1.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Given the importance of data in the world today, organizations face the dual challenges of managing large-scale, continuously incoming data while vetting its quality and reliability. AWS Glue is a serverless dataintegration service that you can use to effectively monitor and managedata quality through AWS Glue Data Quality.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Unlocking the true value of data often gets impeded by siloed information. Traditional datamanagement—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Business units access clean, standardized data.
Effective data analytics relies on seamlessly integratingdata from disparate systems through identifying, gathering, cleansing, and combining relevant data into a unified format. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. To overcome these hurdles, many organizations are building bespoke integrations between services, tools, and homegrown access management systems.
Ask questions in plain English to find the right datasets, automatically generate SQL queries, or create data pipelines without writing code. This innovation drives an important change: you’ll no longer have to copy or move data between datalake and data warehouses.
How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising dataintegrity and compliance? While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. However, efficiently managing and synchronizing data within these lakes presents a significant challenge.
Amazon Redshift is a fast, fully managed petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
The open table format accelerates companies’ adoption of a modern data strategy because it allows them to use various tools on top of a single copy of the data. A solution based on Apache Iceberg encompasses complete datamanagement, featuring simple built-in table optimization capabilities within an existing storage solution.
Giving the mobile workforce access to this data via the cloud allows them to be productive from anywhere, fosters collaboration, and improves overall strategic decision-making. Connecting mainframe data to the cloud also has financial benefits as it leads to lower mainframe CPU costs by leveraging cloud computing for data transformations.
In this post, we delve into the key aspects of using Amazon EMR for modern datamanagement, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
A datamanagement platform (DMP) is a group of tools designed to help organizations collect and managedata from a wide array of sources and to create reports that help explain what is happening in those data streams. Deploying a DMP can be a great way for companies to navigate a business world dominated by data.
It’s a much more seamless process for customers than having to purchase a third-party reverse ETL tool or manage some sort of pipeline back into Salesforce.” For instance, a Data Cloud-triggered flow could update an account manager in Slack when shipments in an external datalake are marked as delayed.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. With the addition of these technologies alongside existing systems like terminal operating systems (TOS) and SAP, the number of data producers has grown substantially. datazone_env_twinsimsilverdata"."cycle_end";')
Data fabric refers to technology products that can be used to integrate, manage and govern data across distributed environments, supporting the cultural and organizational data ownership and access goals of data mesh.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
When internal resources fall short, companies outsource data engineering and analytics. There’s no shortage of consultants who will promise to manage the end-to-end lifecycle of data from integration to transformation to visualization. . The challenge is that data engineering and analytics are incredibly complex.
In this post, we focus on datamanagement implementation options such as accessing data directly in Amazon Simple Storage Service (Amazon S3), using popular data formats like Parquet, or using open table formats like Iceberg. Datamanagement is the foundation of quantitative research.
Amazon OpenSearch Service is a fully managed service offered by AWS that enables you to deploy, operate, and scale OpenSearch domains effortlessly. OpenSearch Service seamlessly integrates with other AWS offerings, providing a robust solution for building scalable and resilient search and analytics applications in the cloud.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Datamanagement platform definition A datamanagement platform (DMP) is a suite of tools that helps organizations to collect and managedata from a wide array of first-, second-, and third-party sources and to create reports and build customer profiles as part of targeted personalization campaigns.
Reading Time: 3 minutes First we had data warehouses, then came datalakes, and now the new kid on the block is the data lakehouse. But what is a data lakehouse and why should we develop one? In a way, the name describes what.
AWS Glue is a serverless, scalable dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources. AWS Glue provides an extensible architecture that enables users with different data processing use cases.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. Choose Add data. About the Authors Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team.
However, companies are still struggling to managedata effectively, to implement GenAI applications that deliver proven business value. Gartner predicts that by the end of this year, 30%.
Alternatively, you might treat them as code and use source code control to manage their evolution over time. Amazon Bedrock is a fully managed service that makes high-performing FMs from leading AI startups and Amazon available through a unified API. The user interaction is stored in a datalake for downstream usage and BI analysis.
Reading Time: 6 minutes Datalake, by combining the flexibility of object storage with the scalability and agility of cloud platforms, are becoming an increasingly popular choice as an enterprise data repository. Whether you are on Amazon Web Services (AWS) and leverage AWS S3.
Reading Time: 6 minutes Datalake, by combining the flexibility of object storage with the scalability and agility of cloud platforms, are becoming an increasingly popular choice as an enterprise data repository. Whether you are on Amazon Web Services (AWS) and leverage AWS S3.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
The infrastructure provides an analytics experience to hundreds of in-house analysts, data scientists, and student-facing frontend specialists. The data engineering team is on a mission to modernize its dataintegration platform to be agile, adaptive, and straightforward to use.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content