This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
According to a study from Rocket Software and Foundry , 76% of IT decision-makers say challenges around accessing mainframe data and contextual metadata are a barrier to mainframe data usage, while 64% view integrating mainframe data with cloud data sources as the primary challenge.
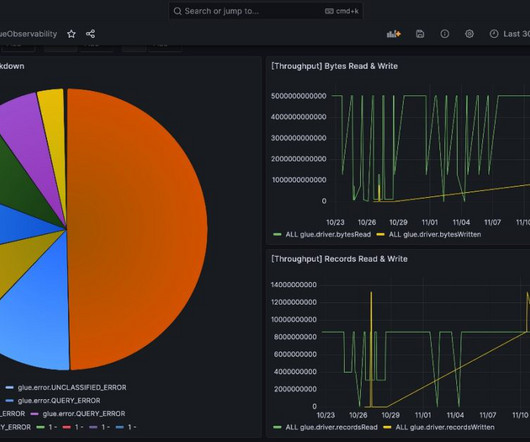
For any modern data-driven company, having smooth dataintegration pipelines is crucial. These pipelines pull data from various sources, transform it, and load it into destination systems for analytics and reporting. This post demonstrates how the new enhanced metrics help you monitor and debug AWS Glue jobs.
AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your dataintegration pipelines built on AWS Glue. This post, walks through how to integrate AWS Glue job observability metrics with Grafana using Amazon Managed Grafana.
Since Apache Iceberg is well supported by AWS data services and Cloudinary was already using Spark on Amazon EMR, they could integrate writing to Data Catalog and start an additional Spark cluster to handle data maintenance and compaction. For example, for certain queries, Athena runtime was 2x–4x faster than Snowflake.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources. The default output is log based.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
In Part 2 of this series, we discussed how to enable AWS Glue job observability metrics and integrate them with Grafana for real-time monitoring. In this post, we explore how to connect QuickSight to Amazon CloudWatch metrics and build graphs to uncover trends in AWS Glue job observability metrics.
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. While real-time data is processed by other applications, this setup maintains high-performance analytics without the expense of continuous processing.
Organizations of all sizes are dealing with exponentially increasing data volume and data sources, which creates challenges such as siloed information, increased technical complexities across various systems and slow reporting of important business metrics.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. The gold model joins the technical logs with billing data and organizes the metrics per business unit.
The Perilous State of Today’s Data Environments Data teams often navigate a labyrinth of chaos within their databases. Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team. Identifying Anomalies: Use advanced algorithms to detect anomalies in data patterns.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
The ability to discover and access data via Denodo Platform is enabled by Denodo Data Catalog , which provides a search-based interface for finding data sources based on metadata or content, as well as metrics related to data popularity and usage.
Jon Pruitt, director of IT at Hartsfield-Jackson Atlanta International Airport, and his team crafted a visual business intelligence dashboard for a top executive in its Emergency Response Team to provide key metrics at a glance, including weather status, terminal occupancy, concessions operations, and parking capacity.
Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Data warehouse Centralized, structured and curated data repository. Inflexible schema, poor for unstructured or real-time data. Datalake Raw storage for all types of structured and unstructured data.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Further, data management activities don’t end once the AI model has been developed. Addressing the Challenge.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
At Stitch Fix, we have been powered by data science since its foundation and rely on many modern datalake and data processing technologies. In our infrastructure, Apache Kafka has emerged as a powerful tool for managing event streams and facilitating real-time data processing.
We are excited to announce the General Availability of AWS Glue Data Quality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. For an up-to-date list, refer to Data Quality Definition Language (DQDL).
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
Hundreds of thousands of organizations build dataintegration pipelines to extract and transform data. They establish data quality rules to ensure the extracted data is of high quality for accurate business decisions. These rules assess the data based on fixed criteria reflecting current business states.
Amazon MSK enables us to tailor the data retention duration to our specific requirements, ranging from seconds to unlimited duration. This flexibility grants uninterrupted data availability to our application, which wasn’t possible with our previous architecture.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Hundreds of thousands of customers use datalakes for analytics and ML to make data-driven business decisions. Choose Save ruleset.
Third, AWS continues adding support for more data sources including connections to software as a service (SaaS) applications, on-premises applications, and other clouds so organizations can act on their data. They can now analyze business metrics in near-real time and make data-driven decisions faster than ever before.
Vyaire developed a custom dataintegration platform, iDataHub, powered by AWS services such as AWS Glue , AWS Lambda , and Amazon API Gateway. In this post, we share how we extracted data from SAP ERP using AWS Glue and the SAP SDK. Prahalathan M is the DataIntegration Architect at Vyaire Medical Inc.
The following figure shows some of the metrics derived from the study. Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data).
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based dataintegration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. Azure Blob Storage serves as the datalake to store raw data.
Loading complex multi-point datasets into a dimensional model, identifying issues, and validating dataintegrity of the aggregated and merged data points are the biggest challenges that clinical quality management systems face. Although datalakes resemble data vaults, a data vault provides more features of a data warehouse.
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating datalakes, serving as object storage for consumer applications, storing logs, and archiving data. For Report path prefix , enter cur-data/account-cur-daily.
To verify the data quality of the sources through statistically-relevant metrics, AWS Glue Data Quality runs data quality tasks on relevant AWS Glue tables. Foundations for a datalake with data governance controls and data quality checks.
In the future, customers will be able to deploy Data Entities and replicate transactional tables in an Azure DataLake. This includes the ability to drill down through live D365 F&SCM data through balances, journal entries, and into subledger transactions to find and fix dataintegrity and reconciliation issues fast.
While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ datalake. Now the admins need to synchronize multiple copies of the data and metadata and ensure that users across the many clusters are not viewing stale information.
With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics in 2021, it became more critical to scale and generate near-real-time data. You can visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes.
It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release 7 times fewer defects. Finally, dataintegrity is of paramount importance.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. This will open the ML transforms page. Choose Next.
Reading Time: 3 minutes During a recent house move I discovered an old notebook with metrics from when I was in the role of a Data Warehouse Project Manager and used to estimate data delivery projects. For the delivery a single data mart with.
We show how to perform extract, transform, and load (ELT), an integration process focused on getting the raw data from a datalake into a staging layer to perform the modeling. The data (business process) needs to be integrated across various departments, in this case, marketing can access the sales data.
To optimize data analytics and AI workloads, organizations need a data store built on an open data lakehouse architecture. This type of architecture combines the performance and usability of a data warehouse with the flexibility and scalability of a datalake.
Creating a single view of any data, however, requires the integration of data from disparate sources. Dataintegration is valuable for businesses of all sizes due to the many benefits of analyzing data from different sources. But dataintegration is not trivial.
Amazon Redshift helps you break down the data silos and allows you to run unified, self-service, real-time, and predictive analytics on all data across your operational databases, datalake, data warehouse, and third-party datasets with built-in governance.
Troubleshooting these production issues requires extensive analysis of logs and metrics, often leading to extended downtimes and delayed insights from critical data pipelines. Usually, troubleshooting requires an experienced data engineer to manually go over the following steps to identify the root cause.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content