This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Curate the data.
Data professionals need to access and work with this information for businesses to run efficiently, and to make strategic forecasting decisions through AI-powered datamodels. Without integrating mainframe data, it is likely that AI models and analytics initiatives will have blind spots.
How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising dataintegrity and compliance? While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
From within the unified studio, you can discover data and AI assets from across your organization, then work together in projects to securely build and share analytics and AI artifacts, including data, models, and generative AI applications.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. Amazon SageMaker Unified Studio (Preview) solves this challenge by providing an integrated authoring experience to use all your data and tools for analytics and AI.
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
These strategies, such as investing in AI-powered cleansing tools and adopting federated governance models, not only address the current data quality challenges but also pave the way for improved decision-making, operational efficiency and customer satisfaction. When financial data is inconsistent, reporting becomes unreliable.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising dataintegrity. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. To achieve this, they plan to use machine learning (ML) models to extract insights from data.
Q: Is datamodeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. A: It always was and is getting cooler!!
The original proof of concept was to have one data repository ingesting data from 11 sources, including flat files and data stored via APIs on premises and in the cloud, Pruitt says. There are a lot of variables that determine what should go into the datalake and what will probably stay on premise,” Pruitt says.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. The team uses dbt-glue to build a transformed gold model optimized for business intelligence (BI).
But even with the “need for speed” to market, new applications must be modeled and documented for compliance, transparency and stakeholder literacy. The metadata-driven suite automatically finds, models, ingests, catalogs and governs cloud data assets. Subscribe to the erwin Expert Blog.
Modern delivery is product (rather than project) management , agile development, small cross-functional teams that co-create , and continuous integration and delivery all with a new financial model that funds “value” not “projects.”. This model allows us to pivot from a data-defensive to a data-offensive position.”.
The data lakehouse is a relatively new data architecture concept, first championed by Cloudera, which offers both storage and analytics capabilities as part of the same solution, in contrast to the concepts for datalake and data warehouse which, respectively, store data in native format, and structured data, often in SQL format.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Many organisations focus too heavily on fine tuning their computational models in their pursuit of ‘quick-wins.’
Recent research by McGuide Research Services for Avanade found 91% of organisations in the sector believe they need to shift to an AI-first operating model within the next 12 months, while 87% of employees feel generative AI tools will make them more efficient, and more innovative. This requires skillsets that firms may not have in-house.
Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications. Learn more about the zero-ETL integrations, datalake performance enhancements, and other announcements below.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model. Amazon Redshift provides built-in features to accelerate the process of modeling, orchestrating, and reporting from a dimensional model. Declare the grain of your data.
This includes tools to help you customize your foundation models, and new services and features to build a strong data foundation to fuel your generative AI applications. Customizing foundation models The need for data is quite obvious if you are building your own foundation models (FMs).
Part Two of the Digital Transformation Journey … In our last blog on driving digital transformation , we explored how enterprise architecture (EA) and business process (BP) modeling are pivotal factors in a viable digital transformation strategy. Digital Transformation Strategy: Smarter Data.
As a result of utilizing the Amazon Redshift integration for Apache Spark, developer productivity increased by a factor of 10, feature generation pipelines were streamlined, and data duplication reduced to zero. These tables are then joined with tables from the Enterprise DataLake (EDL) at runtime. cast("string")).dropDuplicates())
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
The primary modernization approach is data warehouse/ETL automation, which helps promote broad usage of the data warehouse but can only partially improve efficiency in data management processes. However, an automation approach alone is of limited usefulness when data management processes are inefficient.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and datalakes based on operational data.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
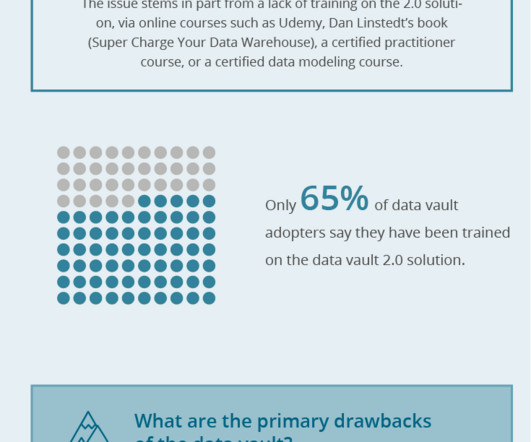
Compared with laggards, a higher portion of best-in-class companies adopt the data vault, embrace its standards, and intend to expand their use of it. They plan to expand their use of this modeling technique and methodology. The lakehouse, data fabric, and data mesh have 8-12% usage each.
Hence the drive to provide ML as a service to the Data & Tech team’s internal customers. All they would have to do is just build their model and run with it,” he says. That step, primarily undertaken by developers and data architects, established data governance and dataintegration.
The trend has been towards using cloud-based applications and tools for different functions, such as Salesforce for sales, Marketo for marketing automation, and large-scale data storage like AWS or datalakes such as Amazon S3 , Hadoop and Microsoft Azure. Sisense provides instant access to your cloud data warehouses.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make dataintegration effortless.
But when it comes to getting the most value out of hybrid cloud, one of the most crucial capabilities required is data replication and synchronization—what enables businesses to efficiently capture data changes and unify various data stores while ensuring low latency, high availability, and dataintegrity.
It requires taking data from equipment sensors, applying advanced analytics to derive descriptive and predictive insights, and automating corrective actions. The end-to-end process requires several steps, including dataintegration and algorithm development, training, and deployment.
Amazon Redshift empowers users to extract powerful insights by securely and cost-effectively analyzing data across data warehouses, operational databases, datalakes, third-party data stores, and streaming sources using zero-ETL approaches.
DataOps involves close collaboration between data scientists, IT professionals, and business stakeholders, and it often involves the use of automation and other technologies to streamline data-related tasks. One of the key benefits of DataOps is the ability to accelerate the development and deployment of data-driven solutions.
In many organizations, the focus is on large language models (LLMs), and foundation models (FMs) more broadly. This is just the tip of the iceberg, because what enables you to obtain differential value from generative AI is your data. In essence, you have to enrich the generative AI models with your differentiated data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content