This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
Founded as Software Development Laboratories in 1977, Oracle is a behemoth in the software industry, generating more than $50 billion in revenue in its fiscal year 2024. Originally focused solely on the relational database market, the software provider operated as Relational Systems, Inc.
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, data quality and master data management.
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
The rapid adoption of software as a service (SaaS) solutions has led to data silos across various platforms, presenting challenges in consolidating insights from diverse sources. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. Now, theyre able to build and collaborate with their data and tools available in one experience, dramatically reducing time-to-value.
A high hurdle many enterprises have yet to overcome is accessing mainframe data via the cloud. Giving the mobile workforce access to this data via the cloud allows them to be productive from anywhere, fosters collaboration, and improves overall strategic decision-making.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from data warehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. The tools to transform your business are here.
Solving the small file problem and improving query performance In modern data architectures, stream processing engines such as Amazon EMR are often used to ingest continuous streams of data into datalakes using Apache Iceberg. Iceberg provides several maintenance operations to keep your tables in good shape.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
AWS Glue is a serverless, scalable dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources. AWS Glue provides an extensible architecture that enables users with different data processing use cases.
Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. She is passionate about helping customers build datalakes using ETL workloads.
How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising dataintegrity and compliance? While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. He has around 20 years of software development and architecture experience.
About the Authors Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. Pradeep Patel is a Software Development Manager on the AWS Glue team. Chuhan Liu is a Software Engineer at AWS Glue.
“Ultimately, CIOs may increasingly be held accountable for the veracity of the reporting, the third-party assurance of the data, and ensuring their organizations’ compliant disclosures align with their corporate ESG goals.” That’s where the single source of truth comes into perspective and increases performance,” Karcher says.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure DataLake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure DataLake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")
Data fabric and data mesh are also both related to logical data management, which is the approach of providing virtualized access to data across an enterprise without the requirement to first extract and load it into a central repository.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
The infrastructure provides an analytics experience to hundreds of in-house analysts, data scientists, and student-facing frontend specialists. The data engineering team is on a mission to modernize its dataintegration platform to be agile, adaptive, and straightforward to use.
In today’s data economy, in which software and analytics have emerged as the key drivers of business, CEOs must rethink the silos and hierarchies that fueled the businesses of the past. They can no longer have “technology people” who work independently from “data people” who work independently from “sales” people or from “finance.”
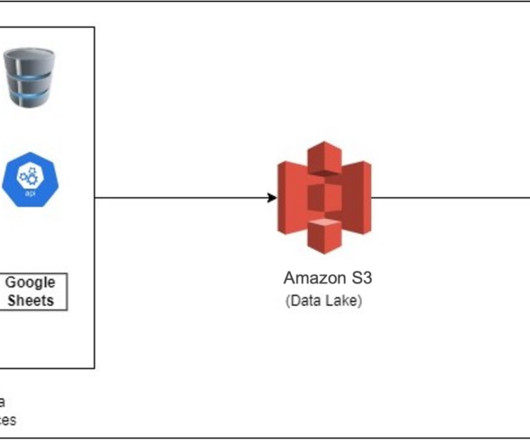
The architecture is comprised of a number of components: Source dataData may be coming from many tens to hundreds of sources, including databases, file transfers, logs, software as a service (SaaS) applications, and more. Amazon AppFlow can be used to transfer data from different SaaS applications to a datalake.
Apache Hudi is an open table format that brings database and data warehouse capabilities to datalakes. Apache Hudi helps data engineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance. Under Administration , choose Data catalog settings.
Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications. Learn more about the zero-ETL integrations, datalake performance enhancements, and other announcements below.
This first article emphasizes data as the ‘foundation-stone’ of AI-based initiatives. Establishing a Data Foundation. The shift away from ‘Software 1.0’ where applications have been based on hard-coded rules has begun and the ‘Software 2.0’ era is upon us. Addressing the Challenge.
It enables data engineers, data scientists, and analytics engineers to define the business logic with SQL select statements and eliminates the need to write boilerplate data manipulation language (DML) and data definition language (DDL) expressions.
The desire to modernize technology, over time, leads to acquiring many different systems with various data entry points and transformation rules for data as it moves into and across the organization. Distribute cloud data: erwin DI’s Business User Portal provides self-service access to cloud data asset discovery and reporting tools.
For any modern data-driven company, having smooth dataintegration pipelines is crucial. These pipelines pull data from various sources, transform it, and load it into destination systems for analytics and reporting. About the Authors Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team.
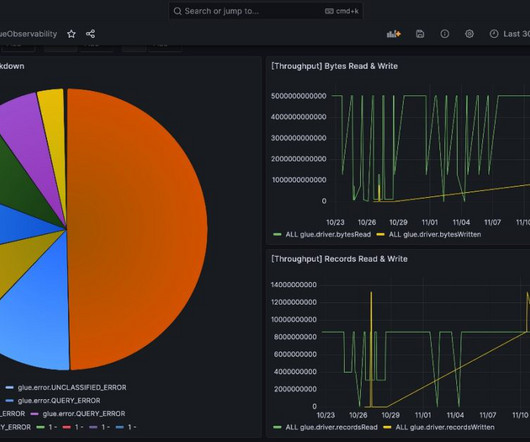
Monitoring data pipelines in real time is critical for catching issues early and minimizing disruptions. AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your dataintegration pipelines built on AWS Glue.
Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Data warehouse Centralized, structured and curated data repository. Inflexible schema, poor for unstructured or real-time data. Datalake Raw storage for all types of structured and unstructured data.
Hundreds of thousands of customers use AWS Glue , a serverless dataintegration service, to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue for Apache Spark jobs work with your code and configuration of the number of data processing units (DPU).
In the first post of this series , we described how AWS Glue for Apache Spark works with Apache Hudi, Linux Foundation Delta Lake, and Apache Iceberg datasets tables using the native support of those datalake formats. Even without prior experience using Hudi, Delta Lake or Iceberg, you can easily achieve typical use cases.
It is noteworthy that business users in particular consider the inability to provide required data and the lack of user acceptance as even more important than enhanced self-service. In particular executives (31 percent) and business intelligence/analytics teams (30 percent) agree that software licenses are too expensive in general.
This typically requires a data warehouse for analytics needs that is able to ingest and handle real time data of huge volumes. Snowflake is a cloud-native platform that eliminates the need for separate data warehouses, datalakes, and data marts allowing secure data sharing across the organization.
If your organization has any kind of data and analytics initiative, then chances are you have people – maybe even an entire department dedicated to managing and integratingdata for (and between) software applications to achieve some sort of business outcome. Is a Power-User or a Data Scientist an Information Steward?
Now finance teams are looking for more efficient and flexible planning that encourages a “total company mindset,” according to the Gartner 2022 Critical Capabilities for Financial Planning Software report. This reflects Jedox’s ability to adjust data models to incorporate operational planning changes,” according to Gartner analysts.
It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release 7 times fewer defects. For users that require a unified view of software quality, this is unacceptable.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content