This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
The software provider also claims to be working on other types of assistants, such as creating dataintegration and transformation pipelines, testdata and generating schemas. Rounding out the portfolio of data platform offerings is the announced but not-yet-available Intelligent DataLake.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Effective data analytics relies on seamlessly integratingdata from disparate systems through identifying, gathering, cleansing, and combining relevant data into a unified format. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
Many of the tests to check performance and volumes of data scanned have used Athena because it provides a simple to use, fully serverless, cost effective, interface without the need to setup infrastructure. Iceberg provides several maintenance operations to keep your tables in good shape.
DataOps improves the robustness, transparency and efficiency of data workflows through automation. For example, DataOps can be used to automate dataintegration. Previously, the consulting team had been using a patchwork of ETL to consolidate data from disparate sources into a datalake.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising dataintegrity. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. To learn more, refer to Amazon SageMaker Unified Studio.
The core issue plaguing many organizations is the presence of out-of-control databases or datalakes characterized by: Unrestrained Data Changes: Numerous users and tools incessantly alter data, leading to a tumultuous environment. This approach ensures quick resolution and minimizes the impact of data issues.
Testing these upgrades involves running the application and addressing issues as they arise. Each test run may reveal new problems, resulting in multiple iterations of changes. They then need to modify their Spark scripts and configurations, updating features, connectors, and library dependencies as needed. Python 3.7) to Spark 3.3.0
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Data warehouse Centralized, structured and curated data repository. Inflexible schema, poor for unstructured or real-time data. Datalake Raw storage for all types of structured and unstructured data.
The desire to modernize technology, over time, leads to acquiring many different systems with various data entry points and transformation rules for data as it moves into and across the organization. Map data movement: erwin DI’s Mapping Manager defines data movement and transformation requirements via drag-and-drop functionality.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
The original proof of concept was to have one data repository ingesting data from 11 sources, including flat files and data stored via APIs on premises and in the cloud, Pruitt says. There are a lot of variables that determine what should go into the datalake and what will probably stay on premise,” Pruitt says.
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure DataLake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure DataLake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")
Amazon Redshift Serverless, generally available since 2021, allows you to run and scale analytics without having to provision and manage the data warehouse. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
This post focuses on such schema changes in file-based tables and shows how to automatically replicate the schema evolution of structured data from table formats in databases to the tables stored as files in cost-effective way. Apache Hudi supports ACID transactions and CRUD operations on a datalake. Start the AWS DMS task.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. Let’s say that this company is located in Europe and the data product must comply with the GDPR.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Over the last decade, we have often heard about the proliferation of data creating sources (mobile applications, laptops, sensors, enterprise apps) in heterogeneous environments (cloud, on-prem, edge) resulting in the exponential growth of data being created.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless dataintegration engine.
It’s even harder when your organization is dealing with silos that impede data access across different data stores. Seamless dataintegration is a key requirement in a modern data architecture to break down data silos. We observed that our TPC-DS tests on Amazon S3 had a total job runtime on AWS Glue 4.0
Advanced analytics and new ways of working with data also create new requirements that surpass the traditional concepts. Many companies are therefore forced to put these concepts to the test. But what are the right measures to make the data warehouse and BI fit for the future? What role do technology and IT infrastructure play?
These tables are then joined with tables from the Enterprise DataLake (EDL) at runtime. During feature development, data engineers require a seamless interface to the EDW. Previous solution process In the previous solution, product team data engineers spent 30 minutes per run to manually expose Redshift data to Spark.
Over the last decade, we have often heard about the proliferation of data creating sources (mobile applications, laptops, sensors, enterprise apps) in heterogeneous environments (cloud, on-prem, edge) resulting in the exponential growth of data being created.
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based dataintegration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. Azure Blob Storage serves as the datalake to store raw data.
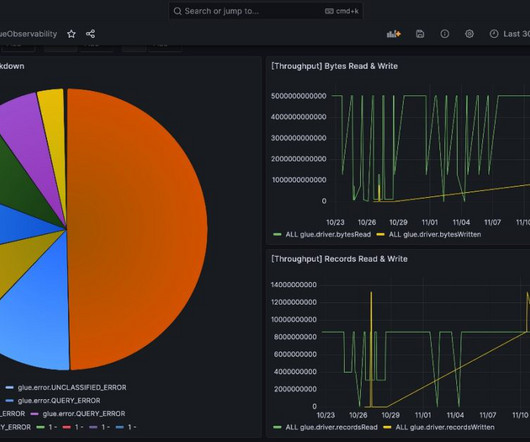
Monitoring data pipelines in real time is critical for catching issues early and minimizing disruptions. AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your dataintegration pipelines built on AWS Glue. Choose Add new data source.
Vyaire developed a custom dataintegration platform, iDataHub, powered by AWS services such as AWS Glue , AWS Lambda , and Amazon API Gateway. In this post, we share how we extracted data from SAP ERP using AWS Glue and the SAP SDK. Test the connection with SAP using the wheel file. Create the PyRFC wheel file.
AWS has invested in a zero-ETL (extract, transform, and load) future so that builders can focus more on creating value from data, instead of having to spend time preparing data for analysis. This means you no longer have to create an external schema in Amazon Redshift to use the datalake tables cataloged in the Data Catalog.
This post proposes an automated solution by using AWS Glue for automating the PostgreSQL data archiving and restoration process, thereby streamlining the entire procedure. You can create an AWS Cloud9 environment in one of the private subnets available in your AWS account to set up testdata in Amazon RDS.
Before starting any production workloads after migration, you need to test your new workflows to ensure no disruption to production systems. Migrating workloads to AWS Glue AWS Glue is a serverless dataintegration service that helps analytics users to discover, prepare, move, and integratedata from multiple sources.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Many customers need an ACID transaction (atomic, consistent, isolated, durable) datalake that can log change data capture (CDC) from operational data sources. There is also demand for merging real-time data into batch data. Delta Lake framework provides these two capabilities. option("header",True).schema(schema).load("s3://"+
Another example of AWS’s investment in zero-ETL is providing the ability to query a variety of data sources without having to worry about data movement. Data analysts and data engineers can use familiar SQL commands to join data across several data sources for quick analysis, and store the results in Amazon S3 for subsequent use.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, datalakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
Tricentis is the global leader in continuous testing for DevOps, cloud, and enterprise applications. Speed changes everything, and continuous testing across the entire CI/CD lifecycle is the key. Tricentis instills that confidence by providing software tools that enable Agile Continuous Testing (ACT) at scale.
While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ datalake. Now the admins need to synchronize multiple copies of the data and metadata and ensure that users across the many clusters are not viewing stale information.
Satori accelerates implementing data security controls on datawarehouses like Amazon Redshift, is straightforward to integrate, and doesn’t require any changes to your Amazon Redshift data, schema, or how your users interact with data. Then complete the following steps to connect to Amazon Redshift: Log in to Satori.
With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics in 2021, it became more critical to scale and generate near-real-time data. You can visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content